Introducción
Muy ahora, sus condiciones de coincidencia pueden ser demasiado amplias. Sin embargo, puede usar la distancia de levenshtein para verificar sus palabras. Puede que no sea demasiado fácil cumplir con todos los objetivos deseados, como la similitud de sonido. Por lo tanto, sugiero dividir su problema en otros problemas.
Por ejemplo, puede crear un verificador personalizado que utilizará la entrada invocable pasada que toma dos cadenas y luego responde la pregunta sobre si son iguales (para levenshtein esa será una distancia menor que algún valor, para similar_text - algún porcentaje de similitud e t.c. - depende de usted definir las reglas).
Similitud, basada en palabras
Bueno, todas las funciones integradas fallarán si estamos hablando de un caso cuando busca una coincidencia parcial, especialmente si se trata de una coincidencia no ordenada. Por lo tanto, deberá crear una herramienta de comparación más compleja. Tienes:
- Cadena de datos (que estará en DB, por ejemplo). Parece D =D0 D1 D2 ... Dn
- Cadena de búsqueda (que será entrada del usuario). Parece que S =S0 S1 ... Pm
Aquí los símbolos de espacio significan cualquier espacio (supongo que los símbolos de espacio no afectarán la similitud). También n > m . Con esta definición, su problema es:encontrar un conjunto de m palabras en D que será similar a S . Por set Me refiero a cualquier secuencia desordenada. Por lo tanto, si encontramos cualquier secuencia de este tipo en D , luego S es similar a D .
Obviamente, si n < m entonces la entrada contiene más palabras que la cadena de datos. En este caso, puede pensar que no son similares o actuar como arriba, pero cambiar los datos y la entrada (eso, sin embargo, parece un poco extraño, pero es aplicable en algún sentido)
Implementación
Para hacer las cosas, deberá poder crear un conjunto de cadenas que sean partes de m palabras de D . Basado en mi esta pregunta
puedes hacer esto con:
protected function nextAssoc($assoc)
{
if(false !== ($pos = strrpos($assoc, '01')))
{
$assoc[$pos] = '1';
$assoc[$pos+1] = '0';
return substr($assoc, 0, $pos+2).
str_repeat('0', substr_count(substr($assoc, $pos+2), '0')).
str_repeat('1', substr_count(substr($assoc, $pos+2), '1'));
}
return false;
}
protected function getAssoc(array $data, $count=2)
{
if(count($data)<$count)
{
return null;
}
$assoc = str_repeat('0', count($data)-$count).str_repeat('1', $count);
$result = [];
do
{
$result[]=array_intersect_key($data, array_filter(str_split($assoc)));
}
while($assoc=$this->nextAssoc($assoc));
return $result;
}
-así que para cualquier arreglo, getAssoc() devolverá una matriz de selecciones desordenadas que consisten en m artículos cada uno.
El siguiente paso es sobre el orden en la selección producida. Deberíamos buscar tanto Niels Andersen y Andersen Niels en nuestro D cuerda. Por lo tanto, deberá poder crear permutaciones para la matriz. Es un problema muy común, pero también pondré mi versión aquí:
protected function getPermutations(array $input)
{
if(count($input)==1)
{
return [$input];
}
$result = [];
foreach($input as $key=>$element)
{
foreach($this->getPermutations(array_diff_key($input, [$key=>0])) as $subarray)
{
$result[] = array_merge([$element], $subarray);
}
}
return $result;
}
Después de esto, podrá crear selecciones de m palabras y luego, permutando cada una de ellas, obtenga todas las variantes para compararlas con la cadena de búsqueda S . Esa comparación cada vez se realizará a través de alguna devolución de llamada, como levenshtein . Aquí hay una muestra:
public function checkMatch($search, callable $checker=null, array $args=[], $return=false)
{
$data = preg_split('/\s+/', strtolower($this->data), -1, PREG_SPLIT_NO_EMPTY);
$search = trim(preg_replace('/\s+/', ' ', strtolower($search)));
foreach($this->getAssoc($data, substr_count($search, ' ')+1) as $assoc)
{
foreach($this->getPermutations($assoc) as $ordered)
{
$ordered = join(' ', $ordered);
$result = call_user_func_array($checker, array_merge([$ordered, $search], $args));
if($result<=$this->distance)
{
return $return?$ordered:true;
}
}
}
return $return?null:false;
}
Esto verificará la similitud, según la devolución de llamada del usuario, que debe aceptar al menos dos parámetros (es decir, cadenas comparadas). También es posible que desee devolver la cadena que activó el retorno positivo de devolución de llamada. Tenga en cuenta que este código no diferirá entre mayúsculas y minúsculas, pero es posible que no desee tal comportamiento (entonces simplemente reemplace strtolower() ).
La muestra del código completo está disponible en esta lista (No utilicé sandbox ya que no estoy seguro de cuánto tiempo estará disponible la lista de códigos allí). Con esta muestra de uso:
$data = 'Niels Faurskov Andersen';
$search = [
'Niels Andersen',
'Niels Faurskov',
'Niels Faurskov Andersen',
'Nils Faurskov Andersen',
'Nils Andersen',
'niels faurskov',
'niels Faurskov',
'niffddels Faurskovffre'//I've added this crap
];
$checker = new Similarity($data, 2);
echo(sprintf('Testing "%s"'.PHP_EOL.PHP_EOL, $data));
foreach($search as $name)
{
echo(sprintf(
'Name "%s" has %s'.PHP_EOL,
$name,
($result=$checker->checkMatch($name, 'levenshtein', [], 1))
?sprintf('matched with "%s"', $result)
:'mismatched'
)
);
}
obtendrá resultados como:
Testing "Niels Faurskov Andersen" Name "Niels Andersen" has matched with "niels andersen" Name "Niels Faurskov" has matched with "niels faurskov" Name "Niels Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Andersen" has matched with "niels andersen" Name "niels faurskov" has matched with "niels faurskov" Name "niels Faurskov" has matched with "niels faurskov" Name "niffddels Faurskovffre" has mismatched
-aquí es una demostración de este código, por si acaso.
Complejidad
Dado que le interesan no solo los métodos, sino también qué tan bueno es, puede notar que dicho código producirá operaciones bastante excesivas. Me refiero, al menos, a la generación de partes de cuerdas. La complejidad aquí consta de dos partes:
- Parte de generación de partes de cuerdas. Si desea generar todas las partes de la cadena, tendrá que hacer esto como lo describí anteriormente. Posible punto a mejorar:generación de conjuntos de cadenas desordenadas (que viene antes de la permutación). Pero aún dudo que se pueda hacer porque el método en el código provisto los generará no con "fuerza bruta", sino como se calculan matemáticamente (con cardinalidad de
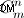 )
) - Parte de verificación de similitud. Aquí su complejidad depende del verificador de similitud dado. Por ejemplo,
similar_text()tiene una complejidad O(N), por lo que con grandes conjuntos de comparación será extremadamente lento.
Pero aún puede mejorar la solución actual con la verificación sobre la marcha. Ahora, este código generará primero todas las subsecuencias de cadenas y luego comenzará a verificarlas una por una. En el caso común, no necesita hacer eso, por lo que es posible que desee reemplazarlo con el comportamiento, cuando después de generar la siguiente secuencia se verificará de inmediato. Luego, aumentará el rendimiento de las cadenas que tienen una respuesta positiva (pero no de las que no tienen ninguna coincidencia).