Sufres de "doble codificación".
Esto es lo que sucedió.
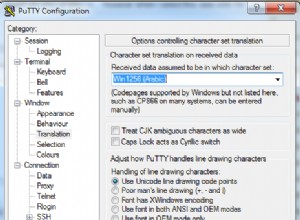
- El cliente tenía caracteres codificados como utf8; y
SET NAMES latin1mintió al afirmar que el cliente tenía codificación latin1; y- La columna en la tabla declarada
CHARACTER SET utf8.
Veamos qué sucede con e-acute:é .
- El hexadecimal para eso, en utf8 es de 2 bytes:
C3A9. SET NAMES latin1lo vio como 2 caracteres codificados en latin1Ãy©(hexadecimal:C3yA9)- Dado que el objetivo era
CHARACTER SET utf8, esos 2 caracteres debían convertirse.Ãse convirtió a utf8 (hexC383) y©(hexC2A9) - Entonces, se almacenaron 4 bytes (hex
C383C2A9)
Al volver a leerlo, se realizaron los pasos inversos y el usuario final posiblemente no notó nada malo. Qué está mal:
- Los datos almacenados son 2 veces más grandes de lo que deberían ser (3x para idiomas asiáticos).
- Es posible que las comparaciones de igual, mayor que, etc. no funcionen como se esperaba.
ORDER BYpuede que no funcione como se esperaba.
Algo como esto reparará sus datos:
UPDATE ... SET col = CONVERT(BINARY(CONVERT(
CONVERT(UNHEX(col) USING utf8)
USING latin1)) USING utf8);
Más discusión y Más ejemplos de cómo solucionarlo