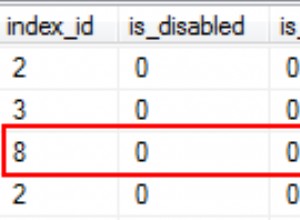
-
...general_cies simple. No equipara combinaciones de 2 caracteres (como con una marca sin espacio) con el equivalente de un solo carácter. -
...unicode_520_ciproviene de la versión 5.20 de Unicode, la última versión disponible cuando MySQL la detectó. Maneja cosas como tener un pedido de Emoji, que las versiones anteriores no tenían. -
Con MySQL 8.0, la intercalación preferida es
utf8mb4_0900_ai_ci, basado en Unicode 9.0. -
...<language>_cimaneja las variaciones encontradas en el idioma dado. Por ejemplo, deberíachyllen español se tratarán como "letras" y se ordenarán entreczydylzym. -
Para uso general, no use
...general_ci, use la última versión derivada de Unicode. Para situaciones específicas del idioma, elija una de las otras intercalaciones. -
Sé cómo (o incluso si) el chino y el árabe se clasifican de manera diferente en las diferentes intercalaciones. Sin embargo, veo
...persion_ci, por lo que sospecho que hay un problema. -
Usa
utf8mb4, noutf8, especialmente porque necesitas chino.