Tu pregunta es realmente impreciso. Siga las sugerencias de @RiggsFolly y lea las referencias sobre cómo hacer una buena pregunta.
Además, como sugiere @DuduMarkovitz, debe comenzar simplificando el problema y limpiando sus datos. Algunos recursos para empezar:
- Tutorial básico de procesamiento de texto por Matt Deny
- Manejo y procesamiento de cadenas en R por Gastón Sánchez
Una vez que esté satisfecho con los resultados, puede proceder a identificar un grupo para cada Var1 entrada (esto lo ayudará en el camino para realizar más análisis / manipulaciones en entradas similares) Esto podría hacerse de muchas maneras diferentes, pero según lo mencionado por @GordonLinoff, una posiblemente sea la Distancia de Levenshtein.
Nota :para 50 000 entradas, el resultado no será 100 % preciso, ya que no siempre categorizar los términos en el grupo apropiado, pero esto debería reducir considerablemente los esfuerzos manuales.
En R, podría hacer esto usando adist()
Usando sus datos de ejemplo:
d <- adist(df$Var1)
# add rownames (this will prove useful later on)
rownames(d) <- df$Var1
> d
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
#125 Hollywood St. 0 1 1 16 15 16 15 15 15 15
#125 Hllywood St. 1 0 2 15 14 15 15 14 14 14
#125 Hollywood St 1 2 0 15 15 15 14 14 15 15
#Target Store 16 15 15 0 2 1 2 10 10 9
#Trget Stre 15 14 15 2 0 3 4 9 10 8
#Target. Store 16 15 15 1 3 0 3 11 11 10
#T argetStore 15 15 14 2 4 3 0 10 11 9
#Walmart 15 14 14 10 9 11 10 0 5 2
#Walmart Inc. 15 14 15 10 10 11 11 5 0 6
#Wal marte 15 14 15 9 8 10 9 2 6 0
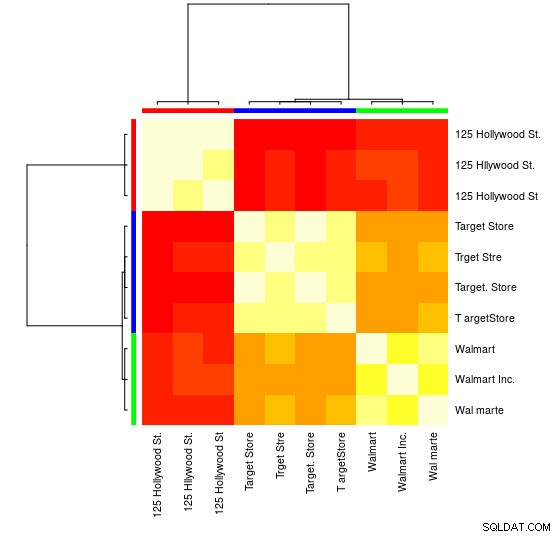
Para esta pequeña muestra, puede ver los 3 grupos distintos (los grupos de valores bajos de distancia de Levensthein) y podría asignarlos fácilmente de forma manual, pero para conjuntos más grandes, es probable que necesite un algoritmo de agrupación.
Ya te señalé en los comentarios uno de mis respuesta anterior
mostrando cómo hacer esto usando hclust() y el método de variación mínima de Ward, pero creo que aquí sería mejor usar otras técnicas (uno de mis recursos favoritos sobre el tema para obtener una descripción general rápida de algunos de los métodos más utilizados en R es este respuesta detallada
)
Aquí hay un ejemplo que usa el agrupamiento de propagación de afinidad:
library(apcluster)
d_ap <- apcluster(negDistMat(r = 1), d)
Encontrará en el objeto APResult d_ap los elementos asociados a cada clúster y el número óptimo de clústeres, en este caso:3.
> example@sqldat.com
#[[1]]
#125 Hollywood St. 125 Hllywood St. 125 Hollywood St
# 1 2 3
#
#[[2]]
# Target Store Trget Stre Target. Store T argetStore
# 4 5 6 7
#
#[[3]]
# Walmart Walmart Inc. Wal marte
# 8 9 10
También puede ver una representación visual:
> heatmap(d_ap, margins = c(10, 10))
Luego, puede realizar más manipulaciones para cada grupo. Como ejemplo, aquí uso hunspell para buscar cada palabra separada de Var1 en un diccionario en_US en busca de errores ortográficos e intente encontrar, dentro de cada group , cuyo id no tiene errores ortográficos (potential_id )
library(dplyr)
library(tidyr)
library(hunspell)
tibble(Var1 = sapply(example@sqldat.com, names)) %>%
unnest(.id = "group") %>%
group_by(group) %>%
mutate(id = row_number()) %>%
separate_rows(Var1) %>%
mutate(check = hunspell_check(Var1)) %>%
group_by(id, add = TRUE) %>%
summarise(checked_vars = toString(Var1),
result_per_word = toString(check),
potential_id = all(check))
Lo que da:
#Source: local data frame [10 x 5]
#Groups: group [?]
#
# group id checked_vars result_per_word potential_id
# <int> <int> <chr> <chr> <lgl>
#1 1 1 125, Hollywood, St. TRUE, TRUE, TRUE TRUE
#2 1 2 125, Hllywood, St. TRUE, FALSE, TRUE FALSE
#3 1 3 125, Hollywood, St TRUE, TRUE, TRUE TRUE
#4 2 1 Target, Store TRUE, TRUE TRUE
#5 2 2 Trget, Stre FALSE, FALSE FALSE
#6 2 3 Target., Store TRUE, TRUE TRUE
#7 2 4 T, argetStore TRUE, FALSE FALSE
#8 3 1 Walmart FALSE FALSE
#9 3 2 Walmart, Inc. FALSE, TRUE FALSE
#10 3 3 Wal, marte FALSE, FALSE FALSE
Nota :Aquí, dado que no hemos realizado ningún procesamiento de texto, los resultados no son muy concluyentes, pero te haces una idea.
Datos
df <- tibble::tribble(
~Var1,
"125 Hollywood St.",
"125 Hllywood St.",
"125 Hollywood St",
"Target Store",
"Trget Stre",
"Target. Store",
"T argetStore",
"Walmart",
"Walmart Inc.",
"Wal marte"
)