Analizar un poco más la consulta de población clave
En la parte 3 de nuestra serie de seguimiento de ODBC, vamos a obtener más información sobre las claves de administración de acceso para las tablas vinculadas de ODBC y cómo clasifica y agrupa las consultas SELECT. En el artículo anterior aprendimos cómo un conjunto de registros de tipo dynaset es, de hecho, 2 consultas separadas con la primera consulta obteniendo solo las claves de la tabla vinculada ODBC que luego se usa para completar los datos. En este artículo, estudiaremos un poco más sobre cómo Access administra las claves y cómo infiere cuál es la clave a usar para una tabla vinculada ODBC entre las ramificaciones que tiene. Comenzaremos con la clasificación.
Agregar una clasificación a la consulta
Viste en el artículo anterior que comenzamos con un simple SELECT sin ningún orden en particular. También vio cómo Access obtuvo por primera vez el CityID y use el resultado de la primera consulta para luego completar las consultas subsiguientes para proporcionar la apariencia de ser rápido para el usuario al abrir un conjunto de registros grande. Si alguna vez ha experimentado una situación en la que agregar una ordenación o agrupación a una consulta, la cosa se ralentiza repentinamente, esto explicará por qué.
Agreguemos una clasificación en el StateProvinceID en una consulta de Access:
SELECT Cities.* FROM Cities ORDER BY Cities.StateProvinceID;Ahora, si rastreamos el SQL de ODBC, deberíamos ver el resultado:
SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" ORDER BY "Application"."Cities"."StateProvinceID" SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? SQLExecute: (GOTO BOOKMARK) SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)Si compara con el seguimiento del artículo anterior, puede ver que son iguales excepto por la primera consulta. Access coloca la ordenación en la primera consulta donde se utiliza para obtener las claves. Eso tiene sentido, ya que al hacer cumplir la clasificación en las claves que utiliza para recorrer los registros, se garantiza que Access tendrá una correspondencia uno a uno entre la posición ordinal de un registro y cómo debe clasificarse. Luego llena los registros exactamente de la misma manera. La única diferencia es la secuencia de teclas que utiliza para completar las otras consultas.
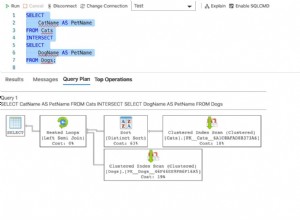
Consideremos lo que sucede cuando agregamos un GROUP BY haciendo un conteo de las ciudades por estado:
SELECT Cities.StateProvinceID ,Count(Cities.CityID) AS CountOfCityID FROM Cities GROUP BY Cities.StateProvinceID;El seguimiento debe generar:
SQLExecDirect:
SELECT
"StateProvinceID"
,COUNT("CityID" )
FROM "Application"."Cities"
GROUP BY "StateProvinceID" Es posible que también haya notado que la consulta ahora se abre lentamente y, aunque puede configurarse como un conjunto de registros de tipo dynaset, Access optó por ignorarlo y básicamente lo trató como un conjunto de registros de tipo instantánea. Esto tiene sentido porque la consulta no es actualizable y porque realmente no puede navegar a una posición arbitraria en una consulta como esta. Por lo tanto, debe esperar hasta que se hayan obtenido todas las filas antes de poder navegar libremente. El StateProvinceID no se puede usar para ubicar un registro ya que habría varios registros en las Cities mesa. Aunque usé un GROUP BY en este ejemplo, no es necesario que sea una agrupación lo que haga que Access use un conjunto de registros de tipo instantánea en su lugar. Usando DISTINCT por ejemplo tendría el mismo efecto. Una regla general útil para predecir si Access usará un conjunto de registros de tipo dynaset es preguntar si una fila dada en el conjunto de registros resultante se asigna exactamente a una fila en la fuente de datos ODBC. Si ese no es el caso, entonces Access usará el comportamiento de instantánea incluso si se suponía que la consulta usaría dynaset. En consecuencia, el hecho de que el valor predeterminado sea un conjunto de registros de tipo dynaset no garantiza que, de hecho, será un conjunto de registros de tipo dynaset. Es simplemente una solicitud , no una demanda.
Determinación de la tecla a usar para seleccionar
Es posible que haya notado en el SQL rastreado anterior tanto en este artículo como en los anteriores, Access usó el CityID como la clave. Esa columna se obtuvo en la primera consulta y luego se usó en consultas preparadas posteriores. Pero, ¿cómo sabe Access qué columna(s) de una tabla vinculada debe usar? La primera inclinación sería decir que busca una clave principal y la usa. Sin embargo, eso sería incorrecto. De hecho, el motor de base de datos de Access hará uso de SQLStatistics de ODBC. durante la vinculación o revinculación de la tabla para examinar qué índices están disponibles. Esta función devolverá un conjunto de resultados con una fila para cada columna que participa en un índice para todos los índices. Este conjunto de resultados siempre está ordenado y, por convención, siempre ordenará índices agrupados, índices hash y luego otros tipos de índices. Dentro de cada tipo de índice, los índices se ordenarán alfabéticamente por sus nombres. El motor de la base de datos de Access seleccionará el primer índice único que encuentre, incluso si no es la clave principal real. Para probar esto, crearemos una tabla tonta con algunos índices extraños:
CREATE TABLE dbo.SillyTable ( ID int CONSTRAINT PK_SillyTable PRIMARY KEY NONCLUSTERED, OtherStuff int CONSTRAINT UQ_SillyTable_OtherStuff UNIQUE CLUSTERED, SomeValue nvarchar(255) );Si luego completamos la tabla con algunos datos y la vinculamos en Access y abrimos una vista de hoja de datos en la tabla vinculada, veremos esto en el SQL ODBC rastreado. Para abreviar, solo se incluyen los primeros 2 comandos.
SQLExecDirect: SELECT "dbo"."SillyTable"."OtherStuff" FROM "dbo"."SillyTable" SQLPrepare: SELECT "ID" ,"OtherStuff" ,"SomeValue" FROM "dbo"."SillyTable" WHERE "OtherStuff" = ?Porque las
OtherStuff participa en un índice agrupado, vino antes de la clave principal real y, por lo tanto, fue seleccionado por el motor de la base de datos de Access para ser utilizado en un conjunto de registros de tipo dynaset para seleccionar una fila individual. Eso también es a pesar del hecho de que el nombre del índice agrupado único habría venido después del nombre del índice principal. Una táctica para obligar al motor de base de datos de Access a seleccionar un índice particular para una tabla sería modificar su tipo o cambiar el nombre para que se ordene alfabéticamente dentro del grupo del tipo de índice. En el caso de SQL Server, las claves primarias generalmente están agrupadas, y solo puede haber un índice agrupado, por lo que es un feliz accidente que generalmente sea el índice correcto para que lo use el motor de base de datos de Access. Sin embargo, si la base de datos de SQL Server contiene tablas con claves primarias no agrupadas y hay un índice único agrupado, es posible que no sea la opción óptima. En los casos en los que no hay índices agrupados, puede influir en qué índices únicos se utilizan nombrando el índice para que se clasifique antes que otros índices. Eso puede ser útil con otro software RDBMS donde la creación de un índice agrupado para la clave principal no es práctico ni posible. Índice del lado de acceso para vista SQL vinculada o tabla sin índices
Al vincular a una vista SQL o una tabla SQL que no tiene ningún índice o clave principal definida, no habrá índices disponibles para que los use el motor de la base de datos de Access. Si ha utilizado el administrador de tablas vinculadas para vincular una tabla o una vista SQL sin índices, es posible que haya visto un cuadro de diálogo como este:
 Si seleccionamos el
Si seleccionamos el ID , complete la vinculación, abra la tabla vinculada en la vista de diseño y luego el cuadro de diálogo de índices, deberíamos ver esto:
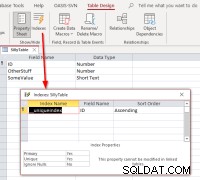 Muestra que la tabla tiene un índice llamado
Muestra que la tabla tiene un índice llamado __uniqueindex pero no existe en la fuente de datos original. ¿Qué está sucediendo? La respuesta es que Access creó un Acceso-lado index para ayudar a identificar qué se puede usar como identificador de registro para dichas tablas o vistas. Si vuelve a vincular las tablas mediante programación en lugar de utilizar el Administrador de tablas vinculadas, encontrará necesario replicar el comportamiento para que dichas tablas vinculadas sean actualizables. Esto se puede hacer ejecutando un comando de Access SQL:
CREATE UNIQUE INDEX [__uniqueindex] ON SillyTable (ID);Puede usar, por ejemplo,
CurrentDb.Execute para ejecutar Access SQL para crear el índice en la tabla vinculada. Sin embargo, no debe ejecutarlo como una consulta de transferencia porque el índice no se crea realmente en el servidor. Es solo para los beneficios de Access permitir la actualización en esa tabla vinculada. Vale la pena señalar que Access solo permitirá exactamente un índice para dicha tabla vinculada y solo si aún no tiene índices. No obstante, puede ver que usar una vista SQL puede ser una opción deseable para los casos en los que el diseño de la base de datos no le permite usar índices agrupados y no quiere jugar con el nombre del índice para persuadir al motor de la base de datos de Access para que use este índice. no ese índice. Puede controlar explícitamente el índice y las columnas que debe incluir al vincular la vista SQL.
Conclusiones
Del artículo anterior vimos que un conjunto de registros de tipo dynaset generalmente emite 2 consultas. La primera consulta por lo general se trata de llenar el archivo. Examinamos más de cerca cómo Access maneja la población de claves que usará para un conjunto de registros de tipo dynaset. Vimos cómo Access en realidad convertirá cualquier clasificación de la consulta de Access original y luego la usará en la consulta de población clave. Vimos que el orden de la consulta de población clave afecta directamente cómo se ordenarán y presentarán al usuario los datos en el conjunto de registros. Esto le permite al usuario hacer cosas como saltar a un registro arbitrario basado en la posición ordinal de la lista.
Luego vimos que la agrupación y otras operaciones de SQL que impiden la asignación uno a uno entre la fila devuelta y la fila original harán que Access trate la consulta de Access como si fuera un conjunto de registros de tipo instantánea a pesar de solicitar un conjunto de registros de tipo dynaset.
Luego analizamos cómo Access determina la clave que se usará para administrar las actualizaciones con una tabla vinculada ODBC. Al contrario de lo que podríamos esperar, no necesariamente seleccionará la clave primaria de la tabla sino el primer índice único que encuentre, dependiendo del tipo de índice y el nombre del índice. Discutimos estrategias para garantizar que Access seleccionará el índice único correcto. Examinamos la vista SQL que normalmente no tiene índices y discutimos un método para informar a Access cómo ingresar una vista SQL o una tabla que no tiene ninguna clave principal, lo que nos permite un mayor control sobre cómo Access manejará las actualizaciones para esas tablas vinculadas ODBC.
En el próximo artículo, veremos cómo Access ejecuta actualizaciones en los datos cuando los usuarios realizan cambios a través de la consulta de Access o el origen de registros.
Nuestros expertos en acceso están disponibles para ayudar. Llámenos al 773-809-5456 o envíenos un correo electrónico a sales@itimpact.com.