PostgreSQL 11 se lanzó el 10 de octubre de 2018 y según lo programado, marcando el 23.° aniversario de la cada vez más popular base de datos de código abierto.
Si bien hay disponible una lista completa de cambios en las Notas de la versión habituales, vale la pena consultar la página renovada de Matriz de funciones que, al igual que la documentación oficial, recibió un cambio de imagen desde su primera versión, lo que facilita la detección de cambios antes de profundizar en los detalles. .
Por ejemplo, en la página de notas de la versión, el "enlace de canal para la autenticación SCAM" está oculto bajo el código fuente, mientras que la matriz lo tiene en la sección de seguridad. Para los curiosos aquí hay una captura de pantalla de la interfaz:
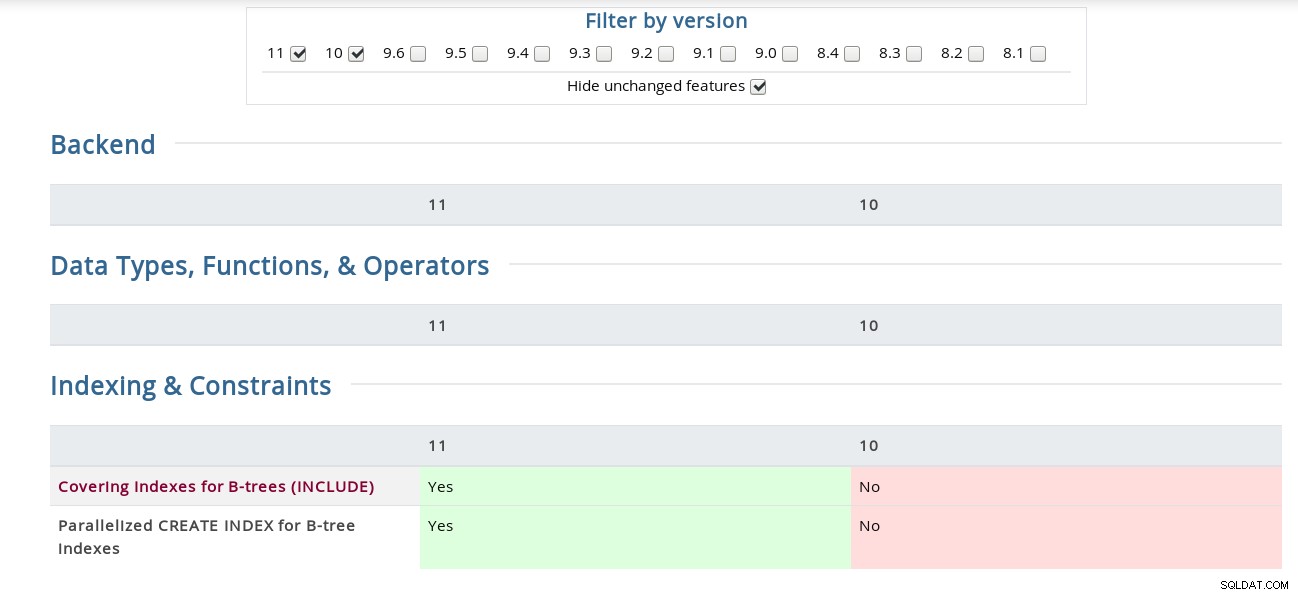 Matriz de características de PostgreSQL
Matriz de características de PostgreSQL Además, la página de notas de la versión de Bucardo Postgres vinculada anteriormente es útil a su manera, lo que facilita la búsqueda de una palabra clave en todas las versiones.
¿Qué hay de nuevo? Con literalmente cientos de cambios, repasaré las diferencias enumeradas en la Matriz de funciones.
Índices de cobertura para árboles B (INCLUYE)
CREATE INDEX recibió la cláusula INCLUDE que permite que los índices incluyan columnas sin clave . Su caso de uso para consultas idénticas frecuentes está bien descrito en la confirmación de Tom Lane del 22 de noviembre, que actualiza la documentación de desarrollo (lo que significa que la documentación actual de PostgreSQL 11 aún no la tiene), por lo que para consultar el texto completo, consulte la sección 11.9. Escaneos de solo índice e índices de cobertura en la versión de desarrollo.
CREAR ÍNDICE en paralelo para índices de árbol B
Como se menciona en el nombre, esta característica solo se implementa para los índices de árbol B, y del registro de confirmación de Robert Haas sabemos que la implementación puede refinarse en el futuro. Como se indica en la documentación de CREATE INDEX, mientras que los métodos de creación de índices paralelos y simultáneos aprovechan múltiples CPU, en el caso de CONCURRENT solo se realizará el primer escaneo de la tabla en paralelo.
Relacionados con esta nueva característica están los parámetros de configuración maintenance_work_mem y maintenance_parallel_maintenance_workers .
Por último, la cantidad de trabajadores paralelos se puede establecer por tabla usando el comando ALTER TABLE y especificando un valor para parallel_workers .
Descargue el documento técnico hoy Gestión y automatización de PostgreSQL con ClusterControl Obtenga información sobre lo que necesita saber para implementar, monitorear, administrar y escalar PostgreSQLDescargar el documento técnicoCompilación Just-In-Time (JIT) para evaluación de expresiones y deformación de tuplas
Con su propio capítulo JIT en la documentación, esta nueva función se basa en la compilación de PostgreSQL con compatibilidad con LLVM (use pg_config para verificar).
El tema de JIT en PostgreSQL es lo suficientemente complejo (consulte la referencia JIT README en la documentación) como para requerir un blog dedicado; mientras tanto, el blog de CitusData sobre JIT es una muy buena lectura para aquellos interesados en profundizar en el tema.
Uniones hash paralelas
Esta mejora en el rendimiento de las consultas paralelas es el resultado de agregar una tabla hash compartida que, como explica Thomas Munro en su blog Parallel Hash for PostgreSQL, evita particionar la tabla hash siempre que encaje en work_mem. , que hasta ahora para PostgreSQL parece ser una mejor solución que el algoritmo de partición primero. El mismo blog describe los obstáculos de la arquitectura PostgreSQL que el autor tuvo que superar en su búsqueda para agregar paralelización a las uniones hash que hablan de la complejidad del trabajo que se requirió para implementar esta característica.
Partición predeterminada
Esta es una partición catch all para almacenar filas que no coinciden con ninguna otra partición definida. En los casos en que se agrega una nueva partición, se recomienda una restricción CHECK para evitar un análisis de la partición predeterminada que puede ser lento cuando la partición predeterminada contiene una gran cantidad de filas.
El comportamiento predeterminado de la partición se explica en la documentación de ALTER TABLE y CREATE TABLE.
División mediante una clave hash
También llamada partición hash, y como se indica en el mensaje de confirmación, la función permite la partición de tablas de tal manera que las particiones contengan un número similar de filas. Esto se logra proporcionando un módulo, que en el escenario más simple se recomienda que sea igual al número de particiones, y el resto debe ser diferente para cada partición.
Para obtener más detalles y un ejemplo, consulte la página de documentación CREATE TABLE.
Compatibilidad con PRIMARY KEY, FOREIGN KEY, Indexes y Triggers en tablas particionadas
El particionamiento de tablas ya es un gran paso para mejorar el rendimiento de las tablas grandes, y la adición de estas características soluciona las limitaciones que han tenido las tablas particionadas desde PostgreSQL 10 cuando se introdujo el "particionamiento declarativo" de estilo moderno.
El trabajo de Alvaro Herrera está en marcha para permitir que las claves foráneas hagan referencia a las claves primarias, y está programado para la próxima versión principal 12 de PostgreSQL.
ACTUALIZAR en una clave de partición
Como se explica en el registro de confirmación del parche, esta actualización evita que PostgreSQL arroje un error cuando una actualización de la clave de partición invalida una fila y, en su lugar, la fila se moverá a una partición adecuada.
Enlace de canales para la autenticación SCRAM
Esta es una medida de seguridad destinada a prevenir ataques de intermediarios en la autenticación SASL y se detalla detalladamente en el blog del autor. La característica requiere un mínimo de OpenSSL 1.0.2.
Sintaxis CREATE PROCEDURE y CALL para procedimientos almacenados de SQL
PostgreSQL ha tenido CREATE FUNCTION desde 1996, con la versión 1.0.1 , sin embargo, las funciones no pueden manejar transacciones. Como se menciona en la documentación, el comando CREATE PROCEDURE no es totalmente compatible con el estándar SQL.
Nota:Estén atentos a un próximo blog que profundiza en esta función
Conclusión
Las principales actualizaciones de PostgreSQL 11 se centran en las mejoras de rendimiento a través de la ejecución paralela, el particionamiento y la compilación Just-In-Time. Los procedimientos almacenados permiten un control total de las transacciones y se pueden escribir en una variedad de lenguajes PL.