¿Por qué lleva tanto tiempo ejecutar una consulta? ¿Por qué no hay índices? Es probable que haya oído hablar de EXPLAIN en PostgreSQL. Sin embargo, todavía hay muchas personas que no tienen idea de cómo usarlo. Espero que este artículo ayude a los usuarios a manejar esta gran herramienta.
Este artículo es la revisión del autor de Understanding EXPLAIN de Guillaume Lelarge. Como me he perdido algo de información, te recomiendo que te familiarices con el original.
El diablo no es tan negro como lo pintan
Es importante comprender la lógica del kernel de PostgreSQL para optimizar las consultas. Trataré de explicar. Realmente no es tan complicado.
EXPLAIN muestra la información necesaria que explica lo que hace el kernel para cada consulta específica.
Echemos un vistazo a lo que muestra el comando EXPLAIN y comprendamos qué sucede exactamente dentro de PostgreSQL. Puede aplicar esta información a PostgreSQL 9.2 y versiones superiores.
Nuestras tareas:
- Aprenda a leer y comprender el resultado del comando EXPLAIN
- Comprenda lo que sucede en PostgreSQL cuando se ejecuta una consulta
Primeros pasos
Practicaremos en una mesa de prueba con un millón de filas.
CREATE TABLE foo (c1 integer, c2 text); INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 1000000) AS i;
Intenta leer los datos
EXPLAIN SELECT * FROM foo;
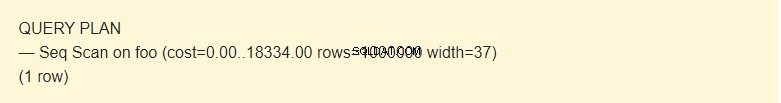
Es posible leer datos de una tabla de varias maneras. En nuestro caso, EXPLAIN notifica que se utiliza un Seq Scan, una lectura secuencial, bloque por bloque, de los datos de la tabla Foo.
¿Qué es el costo? ?
Bueno, no es un tiempo, sino un concepto diseñado para estimar el costo de una operación. El primer valor 0.00 es el costo de obtener la primera fila. El segundo valor 18334.00 es el costo de obtener todas las filas.
Filas son el número aproximado de filas devueltas cuando se realiza una operación Seq Scan. El planificador devuelve este valor. En mi caso, coincide con el número real de filas de la tabla.
Ancho es un tamaño promedio de una fila en bytes.
Intentemos agregar 10 filas.
INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 10) AS i; EXPLAIN SELECT * FROM foo;

El valor de las filas no ha cambiado. Las estadísticas de la tabla son antiguas. Para actualizar las estadísticas, llame al comando ANALIZAR.
Ahora, filas mostrar el número correcto de filas.
¿Qué sucede al ejecutar ANALYZE?
- Al azar, se seleccionan varias filas y se leen de la tabla.
- Se recopilan las estadísticas de valores por cada columna.
El número de filas que ANALYZE lee depende del parámetro default_statistics_target.
Datos reales
Todo lo que vimos arriba en la salida del comando EXPLAIN es lo que el planificador espera obtener. Intentemos compararlos con los resultados de los datos reales. Para hacer esto, use EXPLICAR (ANALIZAR).
EXPLAIN (ANALYZE) SELECT * FROM foo;

Tal consulta se realizará de hecho. Por lo tanto, si ejecuta EXPLAIN (ANALYZE) para las declaraciones INSERT, DELETE o UPDATE, sus datos cambiarán. ¡Ten cuidado! En estos casos, utilice el comando ROLLBACK.
El comando muestra los siguientes parámetros adicionales:
- tiempo real es el tiempo real en milisegundos empleado para obtener la primera fila y todas las filas, respectivamente.
- rows es el número real de filas recibidas con Seq Scan.
- bucles es el número de veces que se tuvo que realizar la operación Seq Scan.
- El tiempo de ejecución total es el tiempo total de ejecución de la consulta.
Lecturas adicionales:
Optimización de consultas en PostgreSQL. EXPLIQUE Conceptos básicos - Parte 2
Optimización de consultas en PostgreSQL. EXPLAIN Fundamentos - Parte 3