En mi artículo anterior, comenzamos a describir los conceptos básicos del comando EXPLAIN y analizamos lo que sucede en PostgreSQL al ejecutar una consulta.
Voy a seguir escribiendo sobre los conceptos básicos de EXPLAIN en PostgreSQL. La información es una breve reseña de Comprender EXPLAIN de Guillaume Lelarge. Recomiendo encarecidamente leer el original, ya que se pierde parte de la información.
Caché
¿Qué sucede a nivel físico al ejecutar nuestra consulta? Averigüémoslo. Implementé mi servidor en Ubuntu 13.10 y usé cachés de disco del nivel del sistema operativo.
Detengo PostgreSQL, confirmo cambios en el sistema de archivos, borro la memoria caché y ejecuto PostgreSQL:
> sudo service postgresql-9.3 stop > sudo sync > sudo su - # echo 3 > /proc/sys/vm/drop_caches # exit > sudo service postgresql-9.3 start
Cuando se borre la memoria caché, ejecute la consulta con la opción BUFFERS
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Leemos la tabla por bloques. El caché está vacío. Tuvimos que acceder a 8334 bloques para leer toda la tabla del disco.
Búferes:la lectura compartida es la cantidad de bloques que PostgreSQL lee del disco.
Ejecutar la consulta anterior
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Búferes:el hit compartido es el número de bloques recuperados de la caché de PostgreSQL.
Con cada consulta, PostgreSQL toma más y más datos del caché, llenando así su propio caché.
Las operaciones de lectura de caché son más rápidas que las operaciones de lectura de disco. Puede ver esta tendencia siguiendo el valor del tiempo de ejecución total.
El tamaño del almacenamiento en caché se define mediante la constante shared_buffers en el archivo postgresql.conf.
DÓNDE
Agregue la condición a la consulta
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
No hay índices en la tabla. Al ejecutar la consulta, cada registro de la tabla se escanea secuencialmente (Seq Scan) y se compara con la condición c1> 500. Si se cumple la condición, el registro se agrega al resultado. De lo contrario, se descarta. El filtro indica este comportamiento, así como los aumentos del valor del costo.
El número estimado de filas disminuye.
El artículo original explica por qué el costo toma este valor y cómo se calcula el número estimado de filas.
Es hora de crear índices.
CREATE INDEX ON foo(c1); EXPLAIN SELECT * FROM foo WHERE c1 > 500;

El número estimado de filas ha cambiado. ¿Qué pasa con el índice?
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

Solo se filtran 510 filas de más de 1 millón. PostgreSQL tuvo que leer más del 99,9 % de la tabla.
Forzaremos el uso del índice deshabilitando Seq Scan:
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

En Index Scan e Index Cond, se utiliza el índice foo_c1_idx en lugar de Filter.
Al seleccionar toda la tabla, usar el índice aumentará el costo y el tiempo para ejecutar la consulta.
Habilitar exploración secuencial:
SET enable_seqscan TO on;
Modificar la consulta:
EXPLAIN SELECT * FROM foo WHERE c1 < 500;
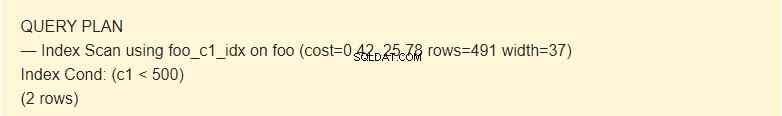
Aquí el planificador usa el índice.
Ahora, compliquemos el valor agregando el campo de texto.
EXPLAIN SELECT * FROM foo
WHERE c1 < 500 AND c2 LIKE 'abcd%';

Como puede ver, el índice foo_c1_idx se usa para c1 <500. Para realizar c2 ~~ ‘abcd%’::text, use el filtro.
Cabe señalar que el formato POSIX del operador LIKE se utiliza en la salida de los resultados. Si solo hay el campo de texto en la condición:
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Se aplica Seq Scan.
Construya el índice por c2:
CREATE INDEX ON foo(c2); EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

El índice no se aplica porque mi base de datos para campos de prueba usa la codificación UTF-8.
Al construir el índice, es necesario especificar la clase del operador text_pattern_ops:
CREATE INDEX ON foo(c2 text_pattern_ops); EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';

¡Estupendo! ¡Funcionó!
Bitmap Index Scan utiliza el índice foo_c2_idx1 para determinar los registros que necesitamos. Luego, PostgreSQL va a la tabla (Bitmap Heap Scan) para asegurarse de que estos registros realmente existan. Este comportamiento se refiere al control de versiones de PostgreSQL.
Si selecciona solo el campo en el que se construye el índice, en lugar de toda la fila:
EXPLAIN SELECT c1 FROM foo WHERE c1 < 500;

Index Only Scan se realizará más rápido que Index Scan debido al hecho de que no es necesario leer la fila de la tabla:ancho =4.
Conclusión
- Seq Scan lee toda la tabla
- Index Scan usa el índice para las declaraciones WHERE y lee la tabla al seleccionar filas
- La exploración del índice de mapa de bits utiliza la exploración del índice y el control de selección a través de la tabla. Eficaz para un gran número de filas.
- Index Only Scan es el bloque más rápido, que solo lee el índice.
Lecturas adicionales:
Optimización de consultas en PostgreSQL. EXPLAIN Fundamentos - Parte 3