Este blog es una breve presentación sobre Jenkins y le muestra cómo usar esta herramienta para ayudarlo con algunas de sus tareas diarias de administración y gestión de PostgreSQL.
Acerca de Jenkins
Jenkins es un software de código abierto para la automatización. Está desarrollado en java y es una de las herramientas más populares para la Integración Continua (CI) y la Entrega Continua (CD).
En 2010, después de la adquisición de Sun Microsystems por parte de Oracle, el software "Hudson" estaba en disputa con su comunidad de código abierto. Esta disputa se convirtió en la base para el lanzamiento del proyecto Jenkins.
Actualmente, "Hudson” (licencia pública de Eclipse) y “Jenkins” (licencia MIT) son dos proyectos activos e independientes con un propósito muy similar.
Jenkins tiene miles de complementos que puede usar para acelerar la fase de desarrollo a través de la automatización durante todo el ciclo de vida del desarrollo; crear, documentar, probar, empaquetar, organizar e implementar.
¿Qué hace Jenkins?
Aunque el principal uso de Jenkins podría ser la Integración Continua (CI) y la Entrega Continua (CD), este código abierto tiene un conjunto de funcionalidades y puede ser utilizado sin ningún compromiso o dependencia de CI o CD, por lo que Jenkins presenta algunas funcionalidades interesantes para explorar:
- Programación de trabajos de períodos (en lugar de usar el crontab tradicional )
- Monitoreo de trabajos, sus registros y actividades mediante una vista limpia (ya que tienen una opción para agrupar)
- El mantenimiento de los trabajos se puede realizar fácilmente; asumiendo que Jenkins tiene un conjunto de opciones para ello
- Instalación del software de configuración y programación (mediante el uso de Puppet) en el mismo host o en otro.
- Publicación de informes y envío de notificaciones por correo electrónico
Ejecución de tareas de PostgreSQL en Jenkins
Hay tres tareas comunes que un desarrollador de PostgreSQL o un administrador de base de datos deben realizar a diario:
- Programación y ejecución de scripts de PostgreSQL
- Ejecutar un proceso de PostgreSQL compuesto por tres o más scripts
- Integración Continua (CI) para desarrollos PL/pgSQL
Para la ejecución de estos ejemplos, se supone que los servidores Jenkins y PostgreSQL (al menos la versión 9.5) están instalados y funcionando correctamente.
Programación y ejecución de un script PostgreSQL
En la mayoría de los casos, la implementación de scripts PostgreSQL diarios (o periódicos) para la ejecución de una tarea habitual como...
- Generación de copias de seguridad
- Probar la restauración de una copia de seguridad
- Ejecución de una consulta con fines de generación de informes
- Limpiar y archivar archivos de registro
- Llamar a un procedimiento PL/pgSQL para purgar tablas
t está definido en crontab :
0 5,17 * * * /filesystem/scripts/archive_logs.sh
0 2 * * * /db/scripts/db_backup.sh
0 6 * * * /db/data/scripts/backup_client_tables.sh
0 4 * * * /db/scripts/Test_db_restore.sh
*/10 * * * * /db/scripts/monitor.sh
0 4 * * * /db/data/scripts/queries.sh
0 4 * * * /db/scripts/data_extraction.sh
0 5 * * * /db/scripts/data_import.sh
0 */4 * * * /db/data/scripts/report.shComo el crontab no es la mejor herramienta fácil de usar para administrar este tipo de programación, se puede hacer en Jenkins con las siguientes ventajas...
- Interfaz muy amigable para monitorear su progreso y estado actual
- Los registros están disponibles de inmediato y no se necesita ninguna concesión especial para acceder a ellos
- El trabajo podría ejecutarse manualmente en Jenkins en lugar de tener una programación
- Para algunos tipos de trabajos, no es necesario definir usuarios y contraseñas en archivos de texto sin formato, ya que Jenkins lo hace de forma segura
- Los trabajos podrían definirse como una ejecución de API
Por lo tanto, podría ser una buena solución para migrar los trabajos relacionados con las tareas de PostgreSQL a Jenkins en lugar de crontab.
Por otro lado, la mayoría de los administradores y desarrolladores de bases de datos tienen habilidades sólidas en lenguajes de secuencias de comandos y sería fácil para ellos desarrollar pequeñas interfaces para manejar estas secuencias de comandos para implementar los procesos automatizados con el objetivo de mejorar sus tareas. Pero recuerde, lo más probable es que Jenkins ya tenga un conjunto de funciones para hacerlo y estas funcionalidades pueden facilitar la vida de los desarrolladores que decidan usarlas.
Por lo tanto, para definir la ejecución del script, es necesario crear un nuevo trabajo, seleccionando la opción "Nuevo elemento".
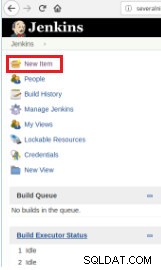 Figura 1 – "Nuevo elemento" para definir un trabajo para ejecutar un script PostgreSQL
Figura 1 – "Nuevo elemento" para definir un trabajo para ejecutar un script PostgreSQL Luego, después de nombrarlo, elija el tipo "Proyectos FreeStyle" y haga clic en Aceptar.
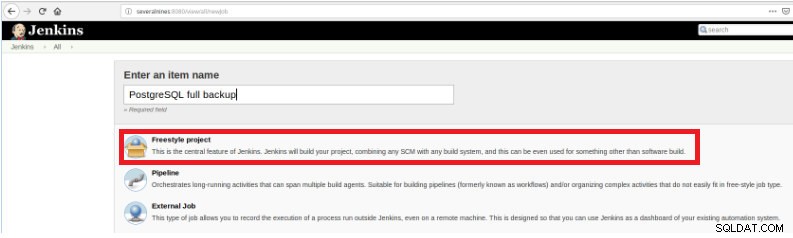 Figura 2:selección del tipo de trabajo (elemento)
Figura 2:selección del tipo de trabajo (elemento) Para finalizar la creación de este nuevo trabajo, en la sección “Build” se debe seleccionar la opción “Execute script” y en el cuadro de línea de comando la ruta y parametrización del script que se ejecutará:
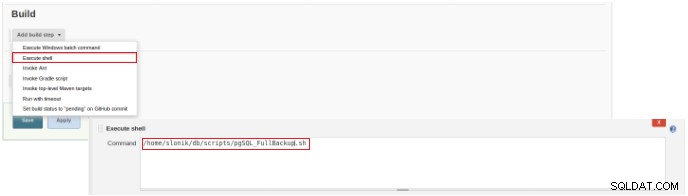 Figura 3 – Especificación del comando a ejecutar
Figura 3 – Especificación del comando a ejecutar Para este tipo de trabajo, es recomendable verificar los permisos del script, porque al menos se debe configurar la ejecución para el grupo al que pertenece el archivo y para todos.
En este ejemplo, el script query.sh tiene permisos de lectura y ejecución para todos, permisos de lectura y ejecución para el grupo y permisos de lectura, escritura y ejecución para el usuario:
example@sqldat.com:~/db/scripts$ ls -l query.sh
-rwxr-xr-x 1 slonik slonik 365 May 11 20:01 query.sh
example@sqldat.com:~/db/scripts$ Este script tiene un conjunto de declaraciones muy simple, básicamente solo llama a la utilidad psql para ejecutar consultas:
#!/bin/bash
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl" > /home/slonik/db/scripts/appl.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_users" > /home/slonik/db/scripts/appl_user.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_rights" > /home/slonik/db/scripts/appl_rights.datEjecución de un proceso de PostgreSQL compuesto por tres o más scripts
En este ejemplo, describiré lo que necesita para ejecutar tres secuencias de comandos diferentes para ocultar datos confidenciales y, para eso, seguiremos los pasos a continuación...
- Importar datos desde archivos
- Preparar los datos para enmascararlos
- Copia de seguridad de la base de datos con datos enmascarados
Entonces, para definir este nuevo trabajo, es necesario seleccionar la opción "Nuevo elemento" en la página principal de Jenkins y luego, luego de asignarle un nombre, se debe elegir la opción "Pipeline":
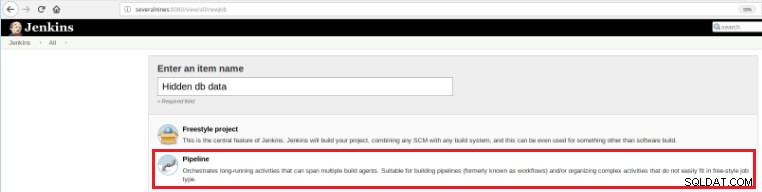 Figura 5:Elemento de canalización en Jenkins
Figura 5:Elemento de canalización en Jenkins Una vez que el trabajo se guarda en la sección "Pipeline", en la pestaña "Opciones avanzadas de proyecto", el campo "Definición" debe establecerse en "Guión de Pipeline", como se muestra a continuación:
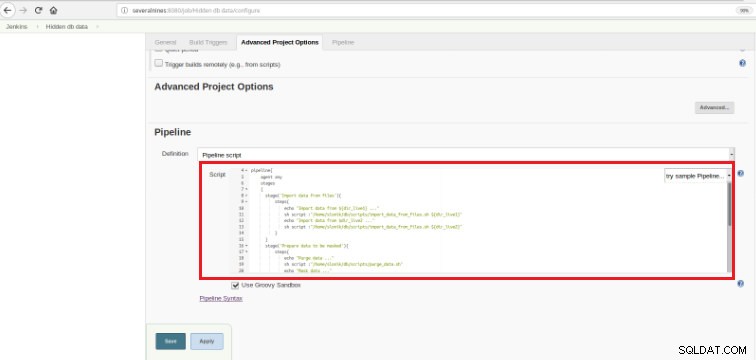 Figura 6:secuencia de comandos Groovy en la sección de canalización
Figura 6:secuencia de comandos Groovy en la sección de canalización Como mencioné al principio del capítulo, el guión Groovy utilizado está compuesto por tres etapas, es decir, tres partes (etapas) bien diferenciadas, tal como se presenta en el siguiente guión:
def dir_live1='/data/ftp/server1'
def dir_live2='/data/ftp/server2'
pipeline{
agent any
stages
{
stage('Import data from files'){
steps{
echo "Import data from ${dir_live1} ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live1}"
echo "Import data from $dir_live2 ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live2}"
}
}
stage('Prepare data to be masked'){
steps{
echo "Purge data ..."
sh script :"/home/slonik/db/scripts/purge_data.sh"
echo "Mask data ..."
sh script :"/home/slonik/db/scripts/mask_data.sh"
}
}
stage('Backup of database with data masked'){
steps{
echo "Backup database after masking ..."
sh script :"/home/slonik/db/scripts/backup_db.sh"
}
}
}
}Groovy es un lenguaje de programación orientado a objetos compatible con la sintaxis Java para la plataforma Java. Es un lenguaje tanto estático como dinámico con características similares a las de Python, Ruby, Perl y Smalltalk.
Es fácil de entender ya que este tipo de guión se basa en unas pocas declaraciones...
Escenario
Significa los 3 procesos que se ejecutarán:"Importar datos de archivos", "Preparar datos para enmascararlos"
y “Copia de seguridad de la base de datos con datos enmascarados”.
Paso
Un "paso" (a menudo llamado "paso de construcción") es una sola tarea que forma parte de una secuencia. Cada etapa podría estar compuesta por varios pasos. En este ejemplo, la primera etapa tiene dos pasos.
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server1'
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server2'Los datos se importan de dos fuentes distintas.
En el ejemplo anterior, es importante notar que hay dos variables definidas al principio y con un alcance global:
dir_live1
dir_live2Los scripts usados en estos tres pasos están llamando al psql , pg_restore y pg_dump utilidades.
Una vez definido el trabajo, es hora de ejecutarlo y para ello, solo es necesario hacer clic en la opción “Construir Ahora”:
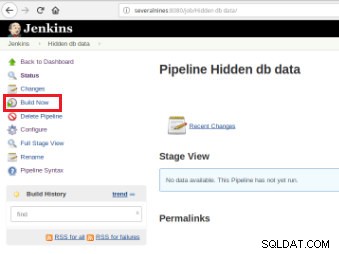 Figura 7:trabajo de ejecución
Figura 7:trabajo de ejecución Una vez que comienza la compilación, es posible verificar su progreso.
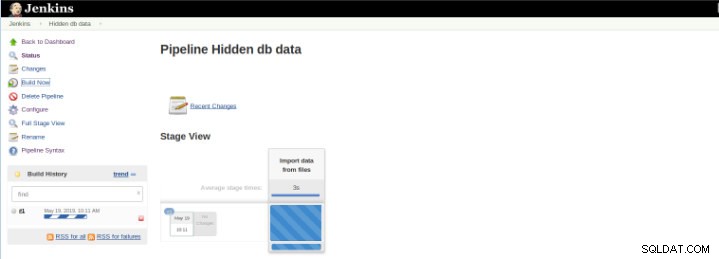 Figura 8:Inicio de "Creación"
Figura 8:Inicio de "Creación" El complemento Pipeline Stage View incluye una visualización ampliada del historial de compilación de Pipeline en la página de índice de un proyecto de flujo en Stage View. Esta vista se construye tan pronto como se completan las tareas y cada tarea está representada por una columna de izquierda a derecha y es posible ver y comparar el tiempo transcurrido para las ejecuciones de serval (conocido como Build en Jenkins).
Una vez que finaliza la ejecución (también llamada Build), es posible obtener detalles adicionales, haciendo clic en el hilo terminado (cuadro rojo).
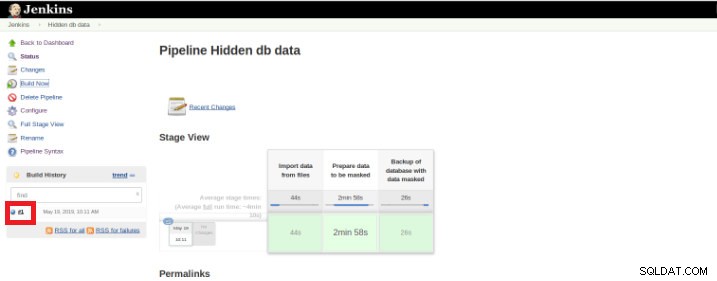 Figura 9:Inicio de “Creación”
Figura 9:Inicio de “Creación” y luego en la opción "Salida de consola".
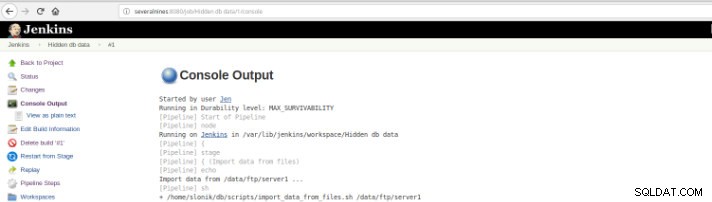 Figura 10:salida de la consola
Figura 10:salida de la consola Las vistas anteriores son de suma utilidad ya que permiten tener una percepción del tiempo de ejecución requerido de cada etapa.
Pipelines, también conocido como flujo de trabajo, es un complemento que permite la definición del ciclo de vida de la aplicación y es una funcionalidad utilizada en Jenkins para la entrega continua (CD). en mente.
Este ejemplo es para ocultar datos confidenciales, pero seguro que hay muchos otros ejemplos diarios del administrador de la base de datos de PostgreSQL que se pueden ejecutar en un trabajo de canalización.
Pipeline ha estado disponible en Jenkins desde la versión 2.0 y es una solución increíble.

Integración Continua (CI) para Desarrollos PL/pgSQL
La integración continua para el desarrollo de la base de datos no es tan fácil como en otros lenguajes de programación debido a los datos que se pueden perder, por lo que no es fácil mantener la base de datos en control de código fuente y desplegarla en un servidor dedicado, especialmente cuando hay scripts. que contienen sentencias DDL (lenguaje de definición de datos) y DML (lenguaje de manipulación de datos). Esto se debe a que este tipo de declaraciones modifican el estado actual de la base de datos y, a diferencia de otros lenguajes de programación, no hay código fuente para compilar.
Por otro lado, hay un conjunto de declaraciones de bases de datos para las cuales es posible la integración continua como para otros lenguajes de programación.
Este ejemplo se basa únicamente en el desarrollo de procedimientos e ilustrará la activación de un conjunto de pruebas (escritas en Python) por Jenkins una vez que los scripts de PostgreSQL, en los que se almacena el código de las siguientes funciones, se confirman en un repositorio de código.
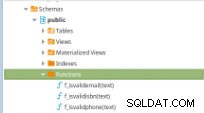 Figura 11:funciones PLpg/SQL
Figura 11:funciones PLpg/SQL Estas funciones son simples y su contenido solo tiene una lógica o una consulta en PLpg/SQL o plperlu idioma como la función f_IsValidEmail :
CREATE OR REPLACE FUNCTION f_IsValidEmail(email text) RETURNS bool
LANGUAGE plperlu
AS $$
use Email::Address;
my @addresses = Email::Address->parse($_[0]);
return scalar(@addresses) > 0 ? 1 : 0;
$$;Todas las funciones aquí presentadas no dependen unas de otras, por lo que no hay precedencia ni en su desarrollo ni en su despliegue. Además, como se comprobará más adelante, no existe dependencia de sus validaciones.
Entonces, para ejecutar un conjunto de scripts de validación una vez que se realiza una confirmación en un repositorio de código, es necesario crear un trabajo de compilación (nuevo elemento) en Jenkins:
 Figura 12:proyecto "Freestyle" para integración continua
Figura 12:proyecto "Freestyle" para integración continua Este nuevo trabajo de compilación debe crearse como proyecto "Freestyle" y en la sección "Repositorio de código fuente" debe definirse la URL del repositorio y sus credenciales (recuadro naranja):
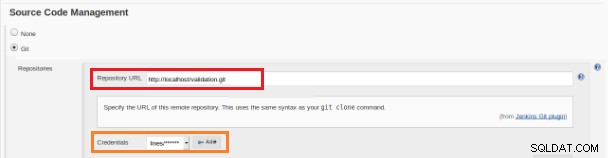 Figura 13:Repositorio de código fuente
Figura 13:Repositorio de código fuente En la sección "Build Triggers" se debe marcar la opción "GitHub hook trigger for GITScm polling":
 Figura 14:sección "Desencadenadores de compilación"
Figura 14:sección "Desencadenadores de compilación" Finalmente en la sección “Build” se debe seleccionar la opción “Execute Shell” y en la caja de comandos los scripts que harán la validación de las funciones desarrolladas:
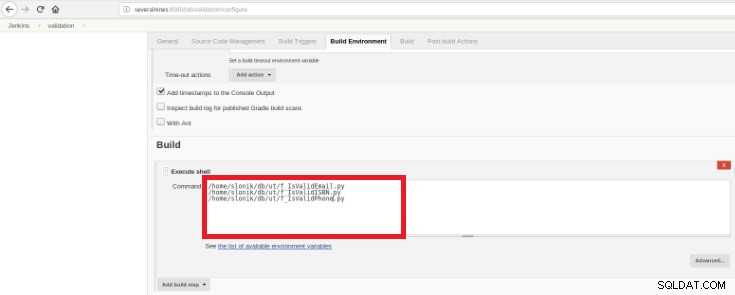 Figura 15:sección "Entorno de compilación"
Figura 15:sección "Entorno de compilación" El propósito es tener un script de validación para cada función desarrollada.
Este script de Python tiene un conjunto simple de declaraciones que llamarán a estos procedimientos desde una base de datos con algunos resultados esperados predefinidos:
#!/usr/bin/python
import psycopg2
con = psycopg2.connect(database="db_deploy", user="postgres", password="postgres10", host="localhost", port="5432")
cur = con.cursor()
email_list = { 'example@sqldat.com' : True,
'tintinmail.com' : False,
'example@sqldat.com' : False,
'director#mail.com': False,
'example@sqldat.com' : True
}
result_msg= "f_IsValidEmail -> OK"
for key in email_list:
cur.callproc('f_IsValidEmail', (key,))
row = cur.fetchone()
if email_list[key]!=row[0]:
result_msg= "f_IsValidEmail -> Nok"
print result_msg
cur.close()
con.close()Este script probará el PLpg/SQL presentado o plperlu funciones y se ejecutará después de cada compromiso en el repositorio de código para evitar regresiones en los desarrollos.
Una vez que se ejecuta la creación de este trabajo, se pueden verificar las ejecuciones de registro.
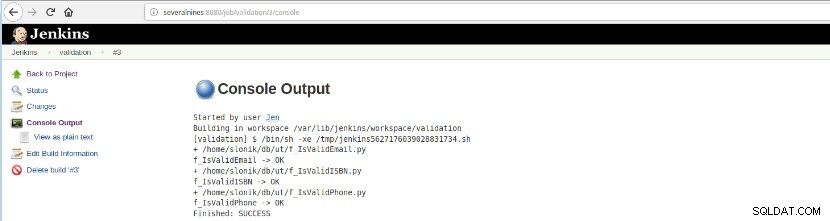 Figura 16:“Salida de la consola”
Figura 16:“Salida de la consola” Esta opción presenta el estado final:¡ÉXITO o FALLO, el espacio de trabajo, los archivos/script ejecutados, los archivos temporales creados y los mensajes de error (para los que fallan)!
Conclusión
En resumen, Jenkins es conocida como una gran herramienta para la integración continua (CI) y la entrega continua (CD), sin embargo, se puede usar para varias funcionalidades como,
- Programación de tareas
- Ejecución de scripts
- Procesos de seguimiento
Para todos estos propósitos en cada ejecución (Vocabulario Build on Jenkins) se pueden analizar los registros y el tiempo transcurrido.
Debido a la gran cantidad de complementos disponibles, podría evitar algunos desarrollos con un objetivo específico, probablemente haya un complemento que haga exactamente lo que está buscando, solo es cuestión de buscar en el centro de actualización o Administrar Jenkins>>Administrar complementos dentro la aplicación web.