Aquí estamos. Casi dos décadas en el siglo XXI y la necesidad de más poder de cómputo sigue siendo un problema. Las empresas de tecnología están golpeando el pavimento para abordar este problema masivo de frente. Los ingenieros de hardware han encontrado una solución alterando la forma en que diseñan y fabrican la unidad central de procesamiento (CPU) de una computadora. Ahora contienen varios núcleos, lo que permite que se produzca la simultaneidad. A su vez, los desarrolladores de software han ajustado la forma en que escriben los programas para adaptarse a este cambio en el hardware.
La comunidad de PostgreSQL ha aprovechado al máximo estas CPU multinúcleo para mejorar el rendimiento de las consultas. Simplemente actualizando a las versiones 9.6 o superiores, puede utilizar una característica llamada paralelismo de consultas para realizar varias operaciones. Divide las tareas en partes más pequeñas y distribuye cada tarea entre múltiples núcleos de CPU. Cada núcleo puede procesar las tareas al mismo tiempo. Debido a las limitaciones del hardware, esta es la única forma de mejorar el rendimiento de la computadora a medida que avanzamos hacia el futuro.
Antes de usar la función de paralelismo en la base de datos de PostgreSQL, es esencial reconocer cómo hace que una consulta sea paralela. Podrás depurar y resolver cualquier problema que surja.
¿Cómo funciona el paralelismo de consultas?
Para tener una mejor comprensión de cómo se ejecuta el paralelismo, es una buena idea comenzar en el nivel del cliente. Para acceder a PostgreSQL, un cliente debe enviar una solicitud de conexión al servidor de la base de datos llamado postmaster. El postmaster completará la autenticación y luego se bifurcará para crear un nuevo proceso de servidor para cada conexión. También es responsable de crear un área de memoria compartida que contiene un grupo de búfer. El grupo de búfer supervisa la transferencia de datos entre la memoria compartida y el almacenamiento. Por lo tanto, en el momento en que se establece una conexión, el grupo de búfer transferirá datos y permitirá que se lleve a cabo el paralelismo de consultas.
No es necesario que todas las consultas sean paralelas. Hay casos en los que solo se necesita una pequeña cantidad de datos, y solo un núcleo puede procesarlos rápidamente. Esta característica solo se usa cuando una consulta tomará una cantidad considerable de tiempo para completarse. El optimizador de base de datos determina si se debe ejecutar el paralelismo. Si es necesario, la base de datos utilizará una porción adicional de memoria denominada memoria compartida dinámica (DSM). Esto permite que el proceso líder y los procesos de trabajo paralelos dividan la consulta entre varios núcleos y recopilen los datos pertinentes.
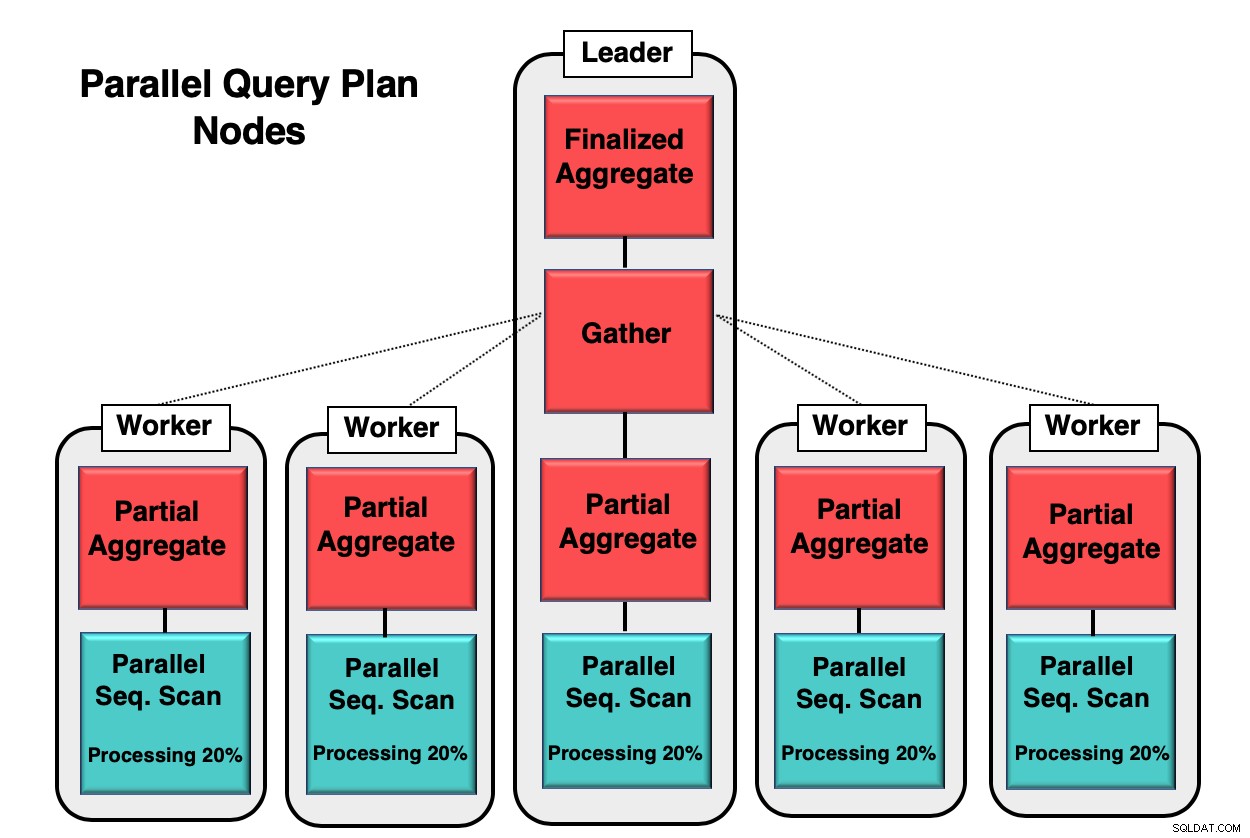
La Figura 1 le brinda un ejemplo de cómo se produce el paralelismo dentro de la base de datos. El proceso líder ejecuta la consulta inicial, mientras que los procesos de trabajo individuales inician una copia del mismo proceso. El nodo agregado parcial, o núcleo de la CPU, es responsable de implementar el escaneo secuencial paralelo de la tabla de la base de datos.
En este caso, cada nodo de exploración secuencial procesa el 20 % de los datos en bloques de 8 kb. Estos mismos nodos pueden coordinar su actividad usando una técnica llamada paralelo consciente. Cada nodo tiene pleno conocimiento de qué datos ya se han procesado y qué datos deben escanearse en la tabla para completar la consulta. Una vez que las tuplas se recopilan por completo, se envían al nodo de recopilación para compilarlas y finalizarlas.
Operaciones Paralelas
Se pueden usar varios tipos de consultas para obtener datos de una base de datos para producir conjuntos de resultados. Aquí hay operaciones específicas que le brindan la capacidad de aprovechar el uso de múltiples núcleos de manera efectiva.
Escaneo secuencial
Esta es una operación que lee datos en una tabla desde el principio hasta el final para recopilar datos. Distribuye uniformemente la carga de trabajo entre múltiples núcleos para aumentar la velocidad de procesamiento de consultas. Es consciente de la actividad de cada núcleo, lo que facilita determinar si se ha completado toda la consulta. El nodo de recopilación luego recibe los datos extraídos en función de la consulta.
Agregación
Una operación estándar, que toma una gran cantidad de datos y los condensa en un número menor de filas. Esto sucede durante el procesamiento paralelo al extraer solo de una tabla o índices, la información adecuada según la consulta. Realizar un promedio de datos específicos es un excelente ejemplo de agregación.
Unión hash
Una técnica que se utiliza para unir los datos entre dos tablas. Es el algoritmo de unión más rápido, que normalmente se realiza con una tabla pequeña y una grande. Primero crea una tabla hash y carga todos los datos de una tabla allí. Luego puede escanear todos los datos del hash y la segunda tabla, usando un escaneo secuencial paralelo. Cada tupla que se extrae del escaneo se compara con la tabla hash para ver si hay una coincidencia. Si se identifica una coincidencia, los datos se unen. Con el lanzamiento de PostgreSQL 11, el uso del paralelismo para completar una unión hash requiere aproximadamente un tercio del tiempo de procesamiento anterior.
Fusionar unirse
Si el optimizador determina que una combinación hash va a exceder la capacidad de la memoria, realizará una combinación de combinación en su lugar. El proceso implica escanear a través de dos listas ordenadas al mismo tiempo y une los mismos elementos. Si los elementos no son iguales, los datos no se unirán.
Unión de bucle anidado
Esta operación se usa cuando tenía que unir dos tablas que contenían diferentes lenguajes de programación, como Quick Basic, Python, etc. Cada tabla se escanea y procesa usando múltiples núcleos. Si los datos coinciden, se envían al nodo de recopilación para que se unan. Los índices también se escanean, razón por la cual este proceso contiene múltiples bucles para recuperar los datos. En promedio, tomará solo un tercio del tiempo completar la unión usando el proceso paralelo.
Exploración de índice de árbol B
Esta operación explora un árbol de datos ordenados para localizar información específica. Este proceso lleva más tiempo que el escaneo secuencial típico porque hay mucha espera mientras se buscan registros. Sin embargo, el trabajo de buscar los datos adecuados se divide entre varios procesadores.
Exploración de montón de mapa de bits
Puede fusionar varios índices utilizando esta operación. Primero desea crear el número equivalente de mapas de bits, ya que tiene índices. Por ejemplo, si tiene tres índices, primero debe crear tres mapas de bits. Cada mapa de bits buscará y compilará tuplas según la consulta.
Descargue el documento técnico hoy Administración y automatización de PostgreSQL con ClusterControlObtenga información sobre lo que necesita saber para implementar, monitorear, administrar y escalar PostgreSQLDescargar el documento técnicoParalelismo de partición
Hay otra forma de paralelismo que puede tener lugar dentro de la base de datos PostgreSQL. Sin embargo, no proviene de escanear tablas y dividir las tareas. Puede particionar o dividir los datos por valores específicos. Por ejemplo, puede tomar los compradores de valor y hacer que un solo núcleo procese los datos solo dentro de ese valor. De esa forma, sabrá con precisión qué está procesando cada núcleo en un momento dado.
Partición hash
Esta operación se utiliza para dividir las filas de la tabla en subtablas. Nuevamente, la división generalmente está determinada por un valor distinto o una lista de valores de una tabla. Este es un método excelente para usar si no tiene una técnica de administración de almacenamiento eficiente en todos sus dispositivos. Le gustaría usar la partición para distribuir aleatoriamente los datos para evitar cuellos de botella de E/S.
Unión por partición
Una técnica utilizada para desglosar tablas por particiones y unirlas haciendo coincidir particiones similares. Por ejemplo, puede tener una tabla grande de compradores de todos los Estados Unidos. Primero puede desglosar la tabla por diferentes ciudades y luego unir algunas ciudades según la región en cada estado. La unión por partición simplifica sus datos y permite la manipulación de tablas.
Paralelo inseguro
PostgreSQL 11 ejecuta automáticamente el paralelismo de consultas si el optimizador determina que esta es la forma más rápida de completar la consulta. Cuanto mayor sea la versión de PostgreSQL que esté utilizando, más capacidad paralela tendrá su base de datos. Desafortunadamente, no todas las consultas deben ejecutarse de manera paralela, incluso si tiene la capacidad. El tipo de consulta que está realizando puede tener limitaciones específicas y requerirá que solo un núcleo complete todo el procesamiento. Esto ralentizará el rendimiento de su sistema, pero garantizará que los datos recibidos estén completos.
Para asegurarse de que sus consultas nunca se pongan en riesgo, los desarrolladores han creado una función llamada paralela insegura. Puede anular manualmente el optimizador de la base de datos y solicitar que la consulta nunca sea paralela. No se realizará el proceso de paralelismo.
El paralelismo dentro de la base de datos PostgreSQL es una característica que solo mejora con cada versión de la base de datos. Aunque el futuro de la tecnología es incierto, parece que el uso de esta función llegó para quedarse.
Para obtener más información, puede consultar lo siguiente...
- https://www.postgresql.org/docs/10/parallel-query.html
- https://www.postgresql.org/docs/10/how-parallel-query-works.html
- https://www.bbc.com/news/business-42797846
- https://www.technologyreview.com/s/421186/why-cpus-arent-getting-any-rapider/
- https://www.percona.com/blog/2019/02/21/consultas-paralelas-en-postgresql/
- https://malisper.me/postgres-merge-joins/
- https://www.enterprisedb.com/blog/partition-wise-joins-“divide-and-conquer-joins- between-partitioned-table