Karen Ly, analista junior de renta fija en RBC, me planteó un desafío de T-SQL que consiste en encontrar la coincidencia más cercana, en lugar de encontrar una coincidencia exacta. En este artículo cubro una forma generalizada y simplista del desafío.
El desafío
El desafío consiste en unir filas de dos tablas, T1 y T2. Use el siguiente código para crear una base de datos de muestra llamada testdb, y dentro de ella las tablas T1 y T2:
SET NOCOUNT ON;
IF DB_ID('testdb') IS NULL
CREATE DATABASE testdb;
GO
USE testdb;
DROP TABLE IF EXISTS dbo.T1, dbo.T2;
CREATE TABLE dbo.T1
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T1 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T1_col1 DEFAULT(0xAA)
);
CREATE TABLE dbo.T2
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T2 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T2_col1 DEFAULT(0xBB)
); Como puede ver, tanto T1 como T2 tienen una columna numérica (tipo INT en este ejemplo) llamada val. El desafío es hacer coincidir con cada fila de T1 la fila de T2 donde la diferencia absoluta entre T2.val y T1.val es la más baja. En caso de empates (múltiples filas coincidentes en T2), haga coincidir la fila superior según el orden ascendente de val, keycol ascendente. Es decir, la fila con el valor más bajo en la columna val, y si todavía tiene empates, la fila con el valor keycol más bajo. El desempate se utiliza para garantizar el determinismo.
Use el siguiente código para completar T1 y T2 con pequeños conjuntos de datos de muestra para poder verificar la corrección de sus soluciones:
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 (val)
VALUES(1),(1),(3),(3),(5),(8),(13),(16),(18),(20),(21);
INSERT INTO dbo.T2 (val)
VALUES(2),(2),(7),(3),(3),(11),(11),(13),(17),(19); Verifique el contenido de T1:
SELECT keycol, val, SUBSTRING(othercols, 1, 1) AS othercols FROM dbo.T1 ORDER BY val, keycol;
Este código genera el siguiente resultado:
keycol val othercols ----------- ----------- --------- 1 1 0xAA 2 1 0xAA 3 3 0xAA 4 3 0xAA 5 5 0xAA 6 8 0xAA 7 13 0xAA 8 16 0xAA 9 18 0xAA 10 20 0xAA 11 21 0xAA
Verifique el contenido de T2:
SELECT keycol, val, SUBSTRING(othercols, 1, 1) AS othercols FROM dbo.T2 ORDER BY val, keycol;
Este código genera el siguiente resultado:
keycol val othercols ----------- ----------- --------- 1 2 0xBB 2 2 0xBB 4 3 0xBB 5 3 0xBB 3 7 0xBB 6 11 0xBB 7 11 0xBB 8 13 0xBB 9 17 0xBB 10 19 0xBB
Aquí está el resultado deseado para los datos de muestra dados:
keycol1 val1 othercols1 keycol2 val2 othercols2 ----------- ----------- ---------- ----------- ----------- ---------- 1 1 0xAA 1 2 0xBB 2 1 0xAA 1 2 0xBB 3 3 0xAA 4 3 0xBB 4 3 0xAA 4 3 0xBB 5 5 0xAA 4 3 0xBB 6 8 0xAA 3 7 0xBB 7 13 0xAA 8 13 0xBB 8 16 0xAA 9 17 0xBB 9 18 0xAA 9 17 0xBB 10 20 0xAA 10 19 0xBB 11 21 0xAA 10 19 0xBB
Antes de comenzar a trabajar en el desafío, examine el resultado deseado y asegúrese de comprender la lógica de coincidencia, incluida la lógica de desempate. Por ejemplo, considere la fila en T1 donde keycol es 5 y val es 5. Esta fila tiene múltiples coincidencias más cercanas en T2:
keycol val othercols ----------- ----------- --------- 4 3 0xBB 5 3 0xBB 3 7 0xBB
En todas estas filas, la diferencia absoluta entre T2.val y T1.val (5) es 2. Usando la lógica de desempate basada en el orden val ascendente, keycol ascendente, la fila superior aquí es donde val es 3 y keycol es 4.
Utilizará los pequeños conjuntos de datos de muestra para comprobar la validez de sus soluciones. Para comprobar el rendimiento, necesita conjuntos más grandes. Use el siguiente código para crear una función auxiliar llamada GetNums, que genera una secuencia de enteros en un rango solicitado:
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE OR ALTER FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO Use el siguiente código para completar T1 y T2 con grandes conjuntos de datos de muestra:
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; Las variables @numrowsT1 y @numrowsT2 controlan el número de filas con las que desea que se completen las tablas. Las variables @maxvalT1 y @maxvalT2 controlan el rango de valores distintos en la columna val y, por lo tanto, afectan la densidad de la columna. El código anterior llena las tablas con 1 000 000 de filas cada una y usa el rango de 1 a 10 000 000 para la columna val en ambas tablas. Esto da como resultado una baja densidad en la columna (gran cantidad de valores distintos, con una pequeña cantidad de duplicados). El uso de valores máximos más bajos dará como resultado una mayor densidad (menor número de valores distintos y, por lo tanto, más duplicados).
Solución 1, usando una subconsulta TOP
La solución más simple y obvia es probablemente la que consulta T1, y usando el operador CROSS APPLY aplica una consulta con un filtro TOP (1), ordenando las filas por la diferencia absoluta entre T1.val y T2.val, usando T2.val , T2.keycol como desempate. Aquí está el código de la solución:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) T2.*
FROM dbo.T2
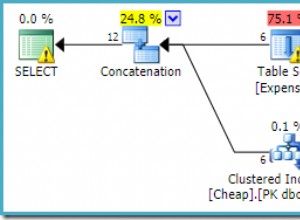
ORDER BY ABS(T2.val - T1.val), T2.val, T2.keycol ) AS A; Recuerde, hay 1.000.000 de filas en cada una de las tablas. Y la densidad de la columna val es baja en ambas tablas. Desafortunadamente, dado que no hay un predicado de filtrado en la consulta aplicada y el orden implica una expresión que manipula columnas, aquí no hay potencial para crear índices de soporte. Esta consulta genera el plan de la Figura 1.
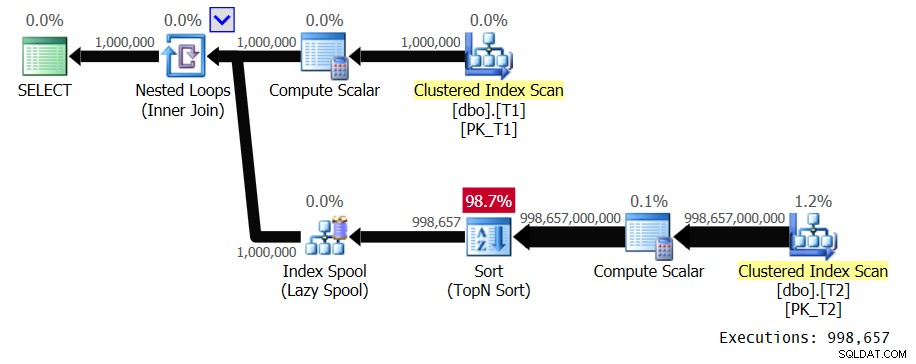 Figura 1:Plan para la Solución 1
Figura 1:Plan para la Solución 1
La entrada exterior del bucle escanea 1 000 000 de filas desde T1. La entrada interna del ciclo realiza un escaneo completo de T2 y una clasificación TopN para cada valor distinto de T1.val. En nuestro plan esto sucede 998.657 veces ya que tenemos muy baja densidad. Coloca las filas en una cola de índice, codificada por T1.val, para que pueda reutilizarlas para ocurrencias duplicadas de valores T1.val, pero tenemos muy pocos duplicados. Este plan tiene complejidad cuadrática. Entre todas las ejecuciones esperadas de la rama interna del bucle, se espera que procese cerca de un billón de filas. Cuando se habla de un gran número de filas para procesar una consulta, una vez que comienza a mencionar miles de millones de filas, la gente ya sabe que se trata de una consulta costosa. Normalmente, las personas no pronuncian términos como billones, a menos que estén discutiendo la deuda nacional de los EE. UU. o las caídas del mercado de valores. Por lo general, no trata con tales números en el contexto de procesamiento de consultas. Pero los planes con complejidad cuadrática pueden terminar rápidamente con tales números. Ejecutar la consulta en SSMS con Incluir estadísticas de consultas en vivo habilitadas tomó 39,6 segundos para procesar solo 100 filas de T1 en mi computadora portátil. Esto significa que esta consulta debería tardar unos 4,5 días en completarse. La pregunta es, ¿realmente te gustan los planes de consultas en vivo? Podría ser un récord Guinness interesante para tratar de establecer.
Solución 2, usando dos subconsultas TOP
Suponiendo que busca una solución que tarde segundos, no días, en completarse, aquí tiene una idea. En la expresión de tabla aplicada, unifique dos consultas TOP (1) internas:una que filtre una fila donde T2.val
Estos son los índices recomendados para respaldar esta solución:
CREATE INDEX idx_val_key ON dbo.T1(val, keycol) INCLUDE(othercols); CREATE INDEX idx_val_key ON dbo.T2(val, keycol) INCLUDE(othercols); CREATE INDEX idx_valD_key ON dbo.T2(val DESC, keycol) INCLUDE(othercols);
Aquí está el código completo de la solución:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; Recuerde que tenemos 1 000 000 de filas en cada tabla, con la columna val con valores en el rango de 1 a 10 000 000 (densidad baja) e índices óptimos en su lugar.
El plan para esta consulta se muestra en la Figura 2.
Figura 2:Plan para la Solución 2
Observe el uso óptimo de los índices en T2, lo que da como resultado un plan con escalado lineal. Este plan utiliza un carrete de índice de la misma manera que lo hizo el plan anterior, es decir, para evitar repetir el trabajo en la rama interna del ciclo para valores duplicados de T1.val. Aquí están las estadísticas de rendimiento que obtuve para la ejecución de esta consulta en mi sistema:
Elapsed: 27.7 sec, CPU: 27.6 sec, logical reads: 17,304,674
Solución 2, con spooling deshabilitado
No puede evitar preguntarse si el carrete de índice es realmente beneficioso aquí. El punto es evitar repetir el trabajo para valores T1.val duplicados, pero en una situación como la nuestra donde tenemos una densidad muy baja, hay muy pocos duplicados. Esto significa que lo más probable es que el trabajo involucrado en el spooling sea mayor que simplemente repetir el trabajo para los duplicados. Hay una manera simple de verificar esto:usando el indicador de rastreo 8690 puede deshabilitar el spooling en el plan, así:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A
OPTION(QUERYTRACEON 8690); Obtuve el plan que se muestra en la Figura 3 para esta ejecución:
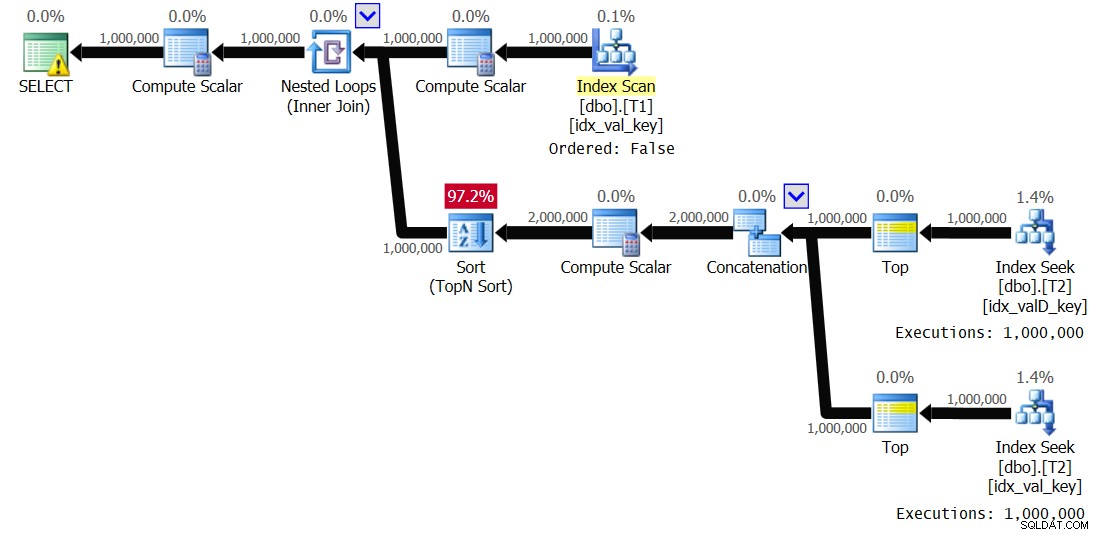 Figura 3:Plan para la solución 2, con la cola de impresión deshabilitada
Figura 3:Plan para la solución 2, con la cola de impresión deshabilitada
Observe que el carrete de índice desapareció, y esta vez la rama interna del ciclo se ejecuta 1,000,000 de veces. Estas son las estadísticas de rendimiento que obtuve para esta ejecución:
Elapsed: 19.18 sec, CPU: 19.17 sec, logical reads: 6,042,148
Eso es una reducción del 44 por ciento en el tiempo de ejecución.
Solución 2, con rango de valores e indexación modificados
Deshabilitar el spooling tiene mucho sentido cuando tiene baja densidad en los valores T1.val; sin embargo, el spooling puede ser muy beneficioso cuando se tiene una alta densidad. Por ejemplo, ejecute el siguiente código para volver a llenar T1 y T2 con la configuración de datos de muestra @maxvalT1 y @maxvalT2 en 1000 (1000 valores distintos máximos):
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 1000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 1000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; Vuelva a ejecutar la Solución 2, primero sin el indicador de rastreo:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; El plan para esta ejecución se muestra en la Figura 4:
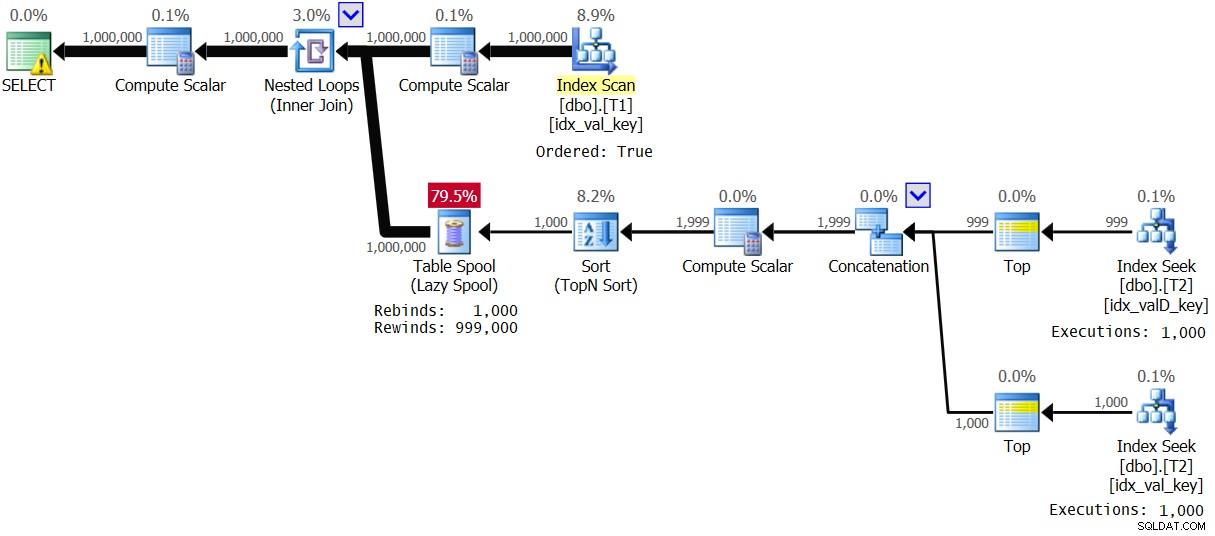 Figura 4:Plan para la solución 2, con un rango de valores de 1 a 1000
Figura 4:Plan para la solución 2, con un rango de valores de 1 a 1000
El optimizador decidió usar un plan diferente debido a la alta densidad en T1.val. Observe que el índice en T1 se escanea en orden clave. Por lo tanto, para cada primera aparición de un valor T1.val distinto, se ejecuta la rama interna del bucle y el resultado se pone en cola en una cola de tabla normal (reenlace). Luego, para cada aparición no primera del valor, se aplica un rebobinado. Con 1000 valores distintos, la rama interna se ejecuta solo 1000 veces. Esto da como resultado excelentes estadísticas de rendimiento:
Elapsed: 1.16 sec, CPU: 1.14 sec, logical reads: 23,278
Ahora intente ejecutar la solución con el spooling deshabilitado:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A
OPTION(QUERYTRACEON 8690); Obtuve el plan que se muestra en la Figura 5.
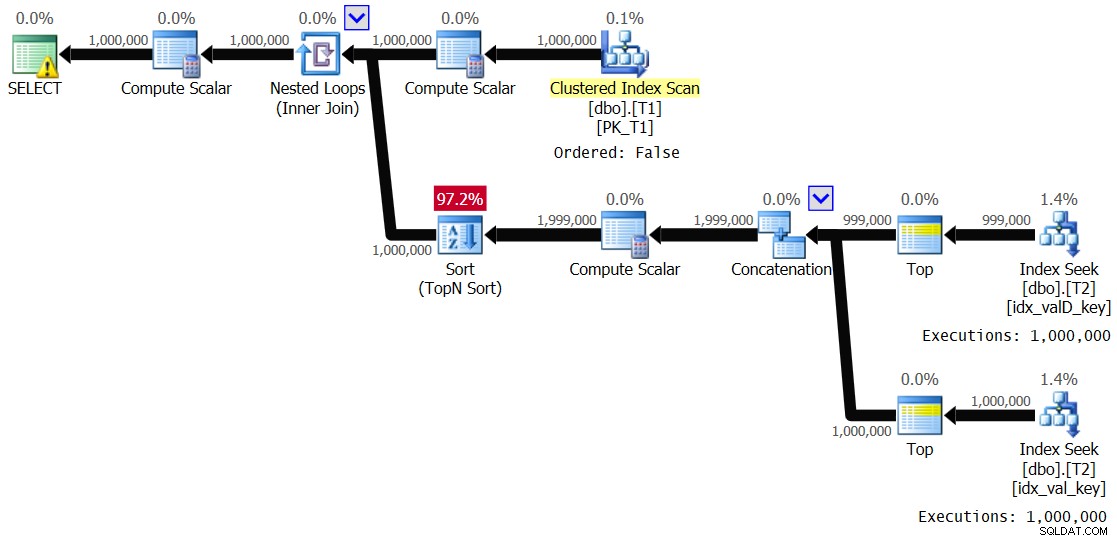 Figura 5:Plan para la solución 2, con rango de valores de 1 a 1000 y cola de impresión deshabilitada
Figura 5:Plan para la solución 2, con rango de valores de 1 a 1000 y cola de impresión deshabilitada
Es esencialmente el mismo plan que se muestra anteriormente en la Figura 3. La rama interna del ciclo se ejecuta 1,000,000 de veces. Estas son las estadísticas de rendimiento que obtuve para esta ejecución:
Elapsed: 24.5 sec, CPU: 24.2 sec, logical reads: 8,012,548
Claramente, debe tener cuidado de no deshabilitar el spooling cuando tiene alta densidad en T1.val.
La vida es buena cuando su situación es lo suficientemente simple como para poder crear índices de apoyo. La realidad es que, en algunos casos, en la práctica, hay suficiente lógica adicional en la consulta que impide la capacidad de crear índices de soporte óptimos. En tales casos, la Solución 2 no funcionará bien.
Para demostrar el rendimiento de la Solución 2 sin índices compatibles, vuelva a llenar T1 y T2 con la configuración de datos de muestra @maxvalT1 y @maxvalT2 en 10000000 (rango de valores 1 - 10M), y también elimine los índices compatibles:
DROP INDEX IF EXISTS idx_val_key ON dbo.T1;
DROP INDEX IF EXISTS idx_val_key ON dbo.T2;
DROP INDEX IF EXISTS idx_valD_key ON dbo.T2;
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; Vuelva a ejecutar la Solución 2, con Incluir estadísticas de consultas en vivo habilitadas en SSMS:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; Obtuve el plan que se muestra en la Figura 6 para esta consulta:
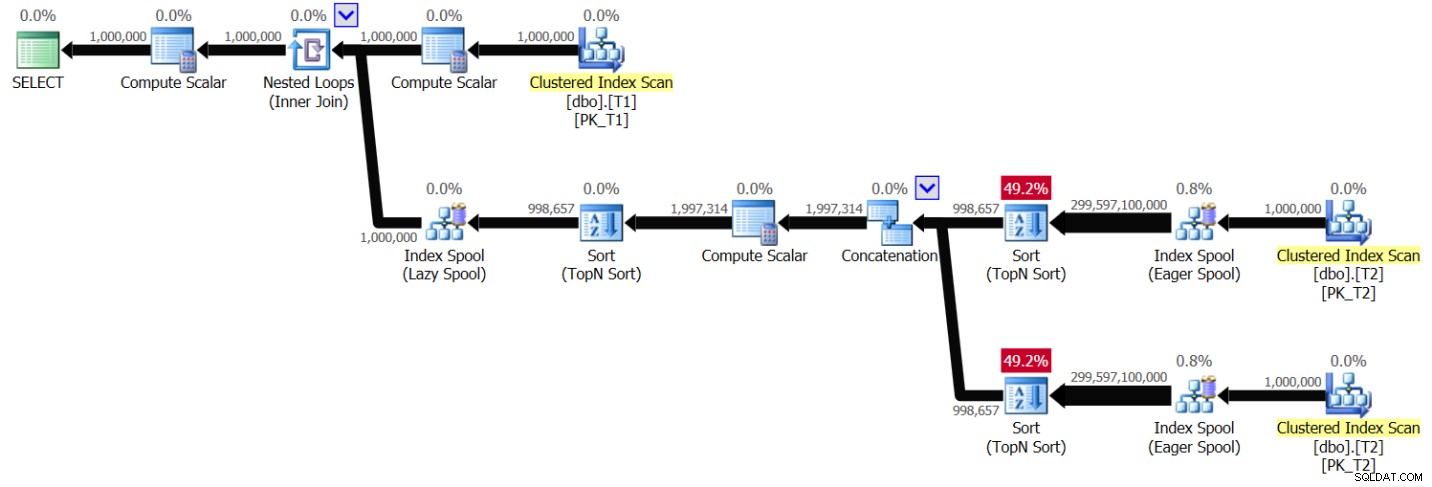 Figura 6:Plan para la Solución 2, sin indexación, con rango de valores 1 – 1,000,000
Figura 6:Plan para la Solución 2, sin indexación, con rango de valores 1 – 1,000,000
Puede ver un patrón muy similar al que se muestra anteriormente en la Figura 1, solo que esta vez el plan escanea T2 dos veces por valor distinto de T1.val. Una vez más, la complejidad del plan se vuelve cuadrática. Ejecutar la consulta en SSMS con Incluir estadísticas de consultas en vivo habilitadas tomó 49,6 segundos para procesar 100 filas de T1 en mi computadora portátil, lo que significa que esta consulta debería demorar aproximadamente 5,7 días en completarse. Por supuesto, esto podría significar buenas noticias si está tratando de romper el récord mundial Guinness por ver un plan de consulta en vivo.
Conclusión
Me gustaría agradecer a Karen Ly de RBC por presentarme este agradable desafío de coincidencia más cercana. Me impresionó mucho su código para manejarlo, que incluía mucha lógica adicional que era específica de su sistema. En este artículo, mostré soluciones con un rendimiento razonable cuando puede crear índices de soporte óptimos. Pero como puede ver, en los casos en que esta no es una opción, obviamente los tiempos de ejecución que obtiene son abismales. ¿Puede pensar en soluciones que funcionarán bien incluso sin índices de soporte óptimos? Continuará…