Continúo con una serie de artículos sobre los conceptos básicos de EXPLAIN en PostgreSQL, que es una breve revisión de Comprensión de EXPLAIN de Guillaume Lelarge.
Para comprender mejor el problema, recomiendo encarecidamente revisar el "Comprensión de EXPLAIN" original de Guillaume Lelarge y lee mi primer y segundo artículo.
ORDENAR POR
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Al principio, ejecuta un escaneo secuencial (Seq Scan) de la tabla de pies y luego, realiza la clasificación (Sort). El signo -> del comando EXPLAIN indica la jerarquía de pasos (nodo). Cuanto antes se ejecuta el paso, mayor sangría tiene.
Clave de clasificación es una condición de clasificación.
Método de ordenación:Disco de combinación externo Se usa un archivo temporal en el disco con una capacidad de 4592 kB al ordenar.
Verifique con la opción BUFFERS:
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;
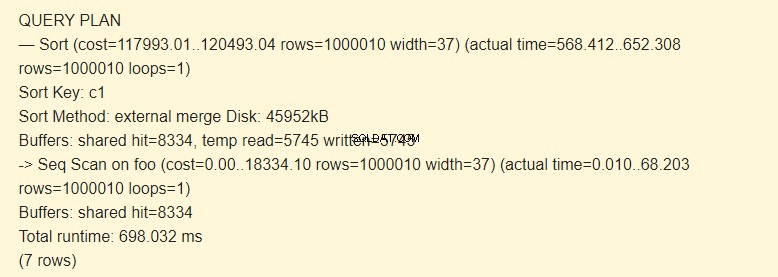
De hecho, la línea temp read=5745 writing=5745 significa que se almacenaron y leyeron 45960 Kb (5745 bloques de 8 Kb cada uno) en el archivo temporal. Las operaciones con 8334 bloques fueron ejecutadas en el caché.
Las operaciones con el sistema de archivos son más lentas que las operaciones en RAM.
Intentemos aumentar la capacidad de memoria de work_mem:
SET work_mem TO '200MB'; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Método de clasificación:Quicksort Memoria:102702kB:toda la clasificación se ejecutó en la RAM.
El índice es el siguiente:
CREATE INDEX ON foo(c1); EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Solo nos queda Index Scan, lo que afectó significativamente la velocidad de la consulta.
LÍMITE
Eliminar el índice creado anteriormente:
DROP INDEX foo_c2_idx1; EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%';
Como era de esperar, se utilizan Seq Scan y Filter.
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%' LIMIT 10;

Seq Scan lee las filas de la tabla y las compara (filtro) con la condición. Tan pronto como haya 10 registros que cumplan con la condición, el escaneo finalizará. En nuestro caso, para obtener 10 filas de resultados, tuvimos que leer solo 3063 registros en lugar de toda la tabla. Se rechazaron 3053 filas de este número (filas eliminadas por filtro).
Lo mismo sucede con Index Scan.
ÚNETE
Cree una nueva tabla y genere estadísticas para ella:
CREATE TABLE bar (c1 integer, c2 boolean); INSERT INTO bar SELECT i, i%2=1 FROM generate_series(1, 500000) AS i; ANALYZE bar;
La consulta de dos tablas es la siguiente:
EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;
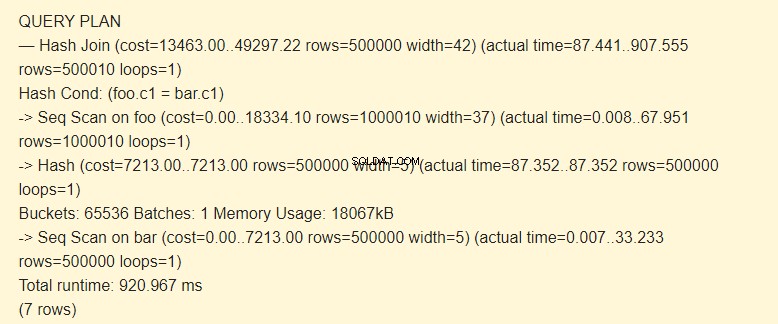
Primero, el escaneo secuencial (Seq Scan) lee la tabla de barras. Se calcula un hash (Hash) para cada fila.
Luego, escanea la tabla foo, y para cada fila, se calcula un hash que se compara (Hash Join) con el hash de la tabla de barras por la condición Hash Cond. Si coinciden, se genera una cadena resultante.
Se utilizan 18067kB de memoria para almacenar hashes para la barra.
Agregue el índice:
CREATE INDEX ON bar(c1); EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;

El hash ya no se usa. Merge Join y Index Scan en los índices de ambas tablas mejoran enormemente el rendimiento.
UNIÓN IZQUIERDA:
EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
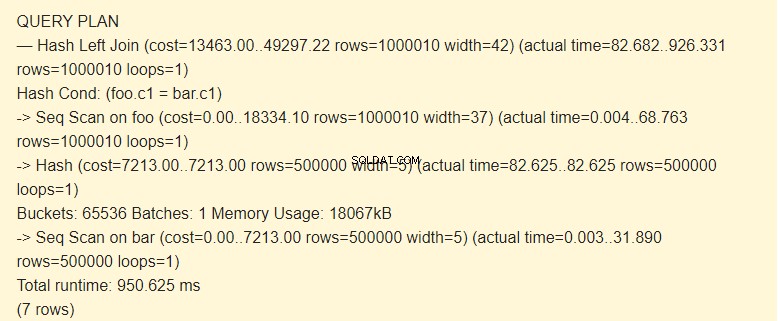
¿Escaneo de secuencia?
Veamos qué resultado tendremos si deshabilitamos Seq Scan.
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Según el programador, usar índices es más costoso que usar hashes. Esto es posible con una cantidad suficientemente grande de memoria asignada. ¿Recuerdas que aumentamos work_mem?
Sin embargo, si no tiene suficiente memoria, el programador se comportará de manera diferente:
SET work_mem TO '15MB'; SET enable_seqscan TO ON; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Si desactivamos Index Scan, ¿qué resultado mostrará EXPLAIN?
SET work_mem TO '15MB'; SET enable_indexscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
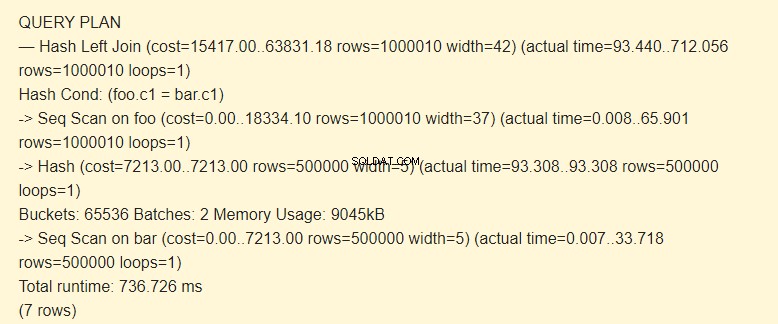
Lotes:2 tiene costo incrementado. El hash completo no cabía en la memoria; tuvimos que dividirlo en dos paquetes de 9045kB.
¡Gracias por leer mis artículos! Espero que hayan sido útiles. Si tiene algún comentario o comentario, no dude en hacérmelo saber.