SELECT m.id, sum(m1.verbosity) AS total
FROM messages m
JOIN messages m1 ON m1.id <= m.id
WHERE m.verbosity < 70 -- optional, to avoid pointless evaluation
GROUP BY m.id
HAVING SUM(m1.verbosity) < 70
ORDER BY total DESC
LIMIT 1;
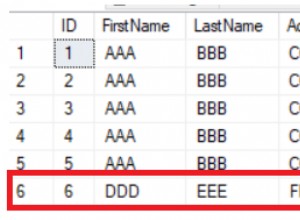
Esto supone un id único y ascendente como lo tienes en tu ejemplo.
En Postgres moderno, o generalmente con SQL estándar moderno (pero no en SQLite):
CET sencillo
WITH cte AS (
SELECT *, sum(verbosity) OVER (ORDER BY id) AS total
FROM messages
)
SELECT *
FROM cte
WHERE total <= 70
ORDER BY id;
CTE recursivo
Debería ser más rápido para mesas grandes en las que solo recuperas un conjunto pequeño.
WITH RECURSIVE cte AS (
( -- parentheses required
SELECT id, verbosity, verbosity AS total
FROM messages
ORDER BY id
LIMIT 1
)
UNION ALL
SELECT c1.id, c1.verbosity, c.total + c1.verbosity
FROM cte c
JOIN LATERAL (
SELECT *
FROM messages
WHERE id > c.id
ORDER BY id
LIMIT 1
) c1 ON c1.verbosity <= 70 - c.total
WHERE c.total <= 70
)
SELECT *
FROM cte
ORDER BY id;
Todas las funciones estándar, excepto LIMIT .
Estrictamente hablando, no existe tal cosa como "independiente de la base de datos". Hay varios estándares SQL, pero ninguno RDBMS cumple completamente. LIMIT funciona para PostgreSQL y SQLite (y algunos otros). Usa TOP 1 para SQL Server, rownum para oráculo. Aquí hay una lista completa en Wikipedia.
El estándar SQL:2008 sería:
...
FETCH FIRST 1 ROWS ONLY
... que admite PostgreSQL, pero casi ningún otro RDBMS.
La alternativa pura que funciona con más sistemas sería envolverlo en una subconsulta y
SELECT max(total) FROM <subquery>
Pero eso es lento y difícil de manejar.
Violín SQL.