Consulta
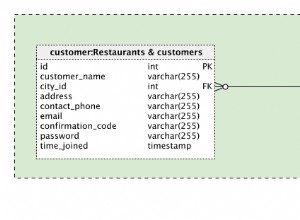
Falta la definición de su tabla. Suponiendo:
CREATE TABLE configuration (
config_id serial PRIMARY KEY
, config jsonb NOT NULL
);
Para encontrar el value y su fila para oid dado y instance :
SELECT c.config_id, d->>'value' AS value
FROM configuration c
, jsonb_array_elements(config->'data') d -- default col name is "value"
WHERE d->>'oid' = '1.3.6.1.4.1.7352.3.10.2.5.35.3'
AND d->>'instance' = '0'
AND d->>'value' <> '1'
Eso es un LATERAL implícito entrar. Comparar:
- Consulta de elementos de matriz dentro del tipo JSON
2) ¿Cuál es la forma más rápida de obtener una tabla con 3 columnas de oid? , instance y value.
Supongo que debo usar jsonb_populate_recordset() , puede proporcionar tipos de datos en la definición de la tabla. Asumiendo text para todos:
CREATE TEMP TABLE data_pattern (oid text, value text, instance text);
También podría ser una tabla persistente (no temporal). Este es solo para la sesión actual. Entonces:
SELECT c.config_id, d.*
FROM configuration c
, jsonb_populate_recordset(NULL::data_pattern, c.config->'data') d
Eso es todo. La primera consulta reescrita:
SELECT c.config_id, d.*
FROM configuration c
, jsonb_populate_recordset(NULL::data_pattern, c.config->'data') d
WHERE d.oid = '1.3.6.1.4.1.7352.3.10.2.5.35.3'
AND d.instance = '0'
AND d.value <> '1';
Pero eso es más lento que la primera consulta. La clave del rendimiento con una tabla más grande es la compatibilidad con índices:
Índice
Puede indexar fácilmente la tabla normalizada (traducida) o el diseño alternativo que propuso en la pregunta. Indexación de su diseño actual no es tan obvio, pero también posible. Para obtener el mejor rendimiento, sugiero un índice funcional solo en los data tecla con jsonb_path_ops clase de operador. Por documentación:
La diferencia técnica entre un jsonb_ops y un jsonb_path_ops GINindex es que el primero crea elementos de índice independientes para cada clave y valor en los datos, mientras que el segundo crea elementos de índice solo para cada valor en los datos.
Esto debería hacer maravillas por rendimiento:
CREATE INDEX configuration_my_idx ON configuration
USING gin ((config->'data') jsonb_path_ops);
Uno podría esperar que solo funcione una coincidencia completa para un elemento de matriz JSON, como:
SELECT * FROM configuration
WHERE (config->'data') @> '[{"oid": "1.3.6.1.4.1.7352.3.10.2.5.35.3"
, "instance": "0", "value": "1234"}]';
Tenga en cuenta la notación de matriz JSON (con encerrando [] ) del valor proporcionado, eso es obligatorio.
Pero los elementos de matriz con un subconjunto de claves trabajar también:
SELECT * FROM configuration
WHERE (config->'data') @> '[{"oid": "1.3.6.1.4.1.7352.3.10.2.5.35.3"
, "instance": "0"}]'
La parte difícil es incorporar su predicado agregado aparentemente no sospechoso value <> '1' . Se debe tener cuidado de aplicar todos los predicados al mismo elemento de matriz Puede combinar esto con la primera consulta:
SELECT c.*, d->>'value' AS value
FROM configuration c
, jsonb_array_elements(config->'data') d
WHERE (config->'data') @> '[{"oid": "1.3.6.1.4.1.7352.3.10.2.5.35.3", "instance": "0"}]'
AND d->>'oid' = '1.3.6.1.4.1.7352.3.10.2.5.35.3' -- must be repeated
AND d->>'instance' = '0' -- must be repeated
AND d->>'value' <> '1' -- here we can rule out
Voilá.
Índice especial
Si su tabla es enorme, el tamaño del índice puede ser un factor decisivo. Puede comparar el rendimiento de esta solución especial con un índice funcional:
Esta función extrae una matriz de Postgres de oid-instance combinaciones de un jsonb dado valor:
CREATE OR REPLACE FUNCTION f_config_json2arr(_j jsonb)
RETURNS text[] LANGUAGE sql IMMUTABLE AS
$func$
SELECT ARRAY(
SELECT (elem->>'oid') || '-' || (elem->>'instance')
FROM jsonb_array_elements(_j) elem
)
$func$
Podemos construir un índice funcional basado en esto:
CREATE INDEX configuration_conrfig_special_idx ON configuration
USING gin (f_config_json2arr(config->'data'));
Y base la consulta en ello:
SELECT * FROM configuration
WHERE f_config_json2arr(config->'data') @> '{1.3.6.1.4.1.7352.3.10.2.5.35.3-0}'::text[]
La idea es que el índice sea sustancialmente más pequeño porque solo almacena los valores combinados sin claves. La matriz operador de contención @> en sí mismo debería funcionar de manera similar al operador de contención jsonb @> . No espero una gran diferencia, pero me interesaría mucho cuál es más rápido.
Similar a la primera solución en esta respuesta relacionada (pero más especializada):
- Índice para encontrar un elemento en una matriz JSON
Aparte:
- Yo no usaría
oidcomo nombre de columna, ya que también se usa para fines internos en Postgres. - Si es posible, usaría una tabla simple y normalizada sin JSON.