La gestión de una instalación de PostgreSQL implica la inspección y el control de una amplia gama de aspectos en la pila de software/infraestructura en la que se ejecuta PostgreSQL. Esto debe cubrir:
- Ajuste de la aplicación con respecto al uso/transacciones/conexiones de la base de datos
- Código de base de datos (consultas, funciones)
- Sistema de base de datos (rendimiento, alta disponibilidad, copias de seguridad)
- Hardware/Infraestructura (discos, CPU/Memoria)
El núcleo de PostgreSQL proporciona la capa de la base de datos en la que confiamos para que se almacenen, procesen y sirvan nuestros datos. Además proporciona toda la tecnología para tener un sistema verdaderamente moderno, eficiente, confiable y seguro. Pero, a menudo, esta tecnología no está disponible como un producto refinado de clase comercial/empresarial listo para usar en la distribución principal de PostgreSQL. En cambio, hay muchos productos/soluciones de la comunidad de PostgreSQL u ofertas comerciales que satisfacen esas necesidades. Esas soluciones vienen como refinamientos fáciles de usar de las tecnologías centrales, o extensiones de las tecnologías centrales o incluso como integración entre los componentes de PostgreSQL y otros componentes del sistema. En nuestro blog anterior titulado Diez consejos para entrar en producción con PostgreSQL, analizamos algunas de esas herramientas que pueden ayudar a administrar una instalación de PostgreSQL en producción. En este blog exploraremos con más detalle los aspectos que se deben cubrir al administrar una instalación de PostgreSQL en producción, y las herramientas más utilizadas para tal fin. Cubriremos los siguientes temas:
- Despliegue
- Administración
- Escalado
- Supervisión
Despliegue
En los viejos tiempos, la gente solía descargar y compilar PostgreSQL a mano y luego configurar los parámetros de tiempo de ejecución y el control de acceso de los usuarios. Todavía hay algunos casos en los que esto podría ser necesario, pero a medida que los sistemas maduraron y comenzaron a crecer, surgió la necesidad de formas más estandarizadas de implementar y administrar Postgresql. La mayoría de los sistemas operativos proporcionan paquetes para instalar, implementar y administrar clústeres de PostgreSQL. Debian ha estandarizado su propio diseño de sistema que admite muchas versiones de Postgresql y muchos clústeres por versión al mismo tiempo. El paquete debian postgresql-common proporciona las herramientas necesarias. Por ejemplo, para crear un nuevo clúster (llamado i18n_cluster) para PostgreSQL versión 10 en Debian, podemos hacerlo dando los siguientes comandos:
$ pg_createcluster 10 i18n_cluster -- --encoding=UTF-8 --data-checksumsLuego actualice systemd:
$ sudo systemctl daemon-reloady finalmente inicie y use el nuevo clúster:
$ sudo systemctl start example@sqldat.com_cluster.service
$ createdb -p 5434 somei18ndb(tenga en cuenta que Debian maneja diferentes clústeres mediante el uso de diferentes puertos 5432, 5433, etc.)
A medida que crece la necesidad de implementaciones más automatizadas y masivas, cada vez más instalaciones utilizan herramientas de automatización como Ansible, Chef y Puppet. Además de la automatización y la reproducibilidad de las implementaciones, las herramientas de automatización son excelentes porque son una buena forma de documentar la implementación y la configuración de un clúster. Por otro lado, la automatización ha evolucionado hasta convertirse en un gran campo en sí mismo, que requiere personas capacitadas para escribir, administrar y ejecutar scripts automatizados. Puede encontrar más información sobre el aprovisionamiento de PostgreSQL en este blog:Conviértase en un DBA de PostgreSQL:aprovisionamiento e implementación.
Administración
Administrar un sistema en vivo implica tareas como:programar copias de seguridad y monitorear su estado, recuperación ante desastres, administración de configuración, administración de alta disponibilidad y manejo automático de conmutación por error. La copia de seguridad de un clúster de Postgresql se puede realizar de varias formas. Herramientas de bajo nivel:
- pg_dump tradicional (copia de seguridad lógica)
- copias de seguridad a nivel del sistema de archivos (copia de seguridad física)
- pg_basebackup (copia de seguridad física)
O nivel superior:
- Barman
- PgBackRest
Cada una de esas formas cubre diferentes casos de uso y escenarios de recuperación, y varían en complejidad. La copia de seguridad de PostgreSQL está estrechamente relacionada con las nociones de PITR, archivado WAL y replicación. A lo largo de los años, el procedimiento de tomar, probar y finalmente (¡crucemos los dedos!) Usar copias de seguridad con PostgreSQL ha evolucionado hasta convertirse en una tarea compleja. Puede encontrar una buena descripción general de las soluciones de copia de seguridad para PostgreSQL en este blog:Principales herramientas de copia de seguridad para PostgreSQL.
En cuanto a la alta disponibilidad y la conmutación por error automática, lo mínimo que debe tener una instalación para implementar esto es:
- Un primario en funcionamiento
- Un modo de espera activo que acepta WAL transmitido desde el principal
- En el caso de un primario fallido, un método para decirle al primario que ya no es el primario (a veces llamado STONITH)
- Un mecanismo de latido para comprobar la conectividad entre los dos servidores y el estado del principal
- Un método para realizar la conmutación por error (por ejemplo, a través de pg_ctl, promoción o archivo de activación)
- Un procedimiento automatizado para la recreación del principal antiguo como un nuevo recurso de reserva:una vez que se detecta una interrupción o una falla en el principal, se debe promocionar un recurso de reserva como el nuevo recurso principal. El antiguo principal ya no es válido ni utilizable. Por lo tanto, el sistema debe tener una forma de manejar este estado entre la conmutación por error y la recreación del antiguo servidor primario como el nuevo servidor de reserva. Este estado se denomina estado degenerado, y PostgreSQL proporciona una herramienta llamada pg_rewind para acelerar el proceso de recuperar el primario antiguo en estado sincronizable desde el nuevo primario.
- Un método para realizar cambios bajo demanda/planificados
Una herramienta ampliamente utilizada que maneja todo lo anterior es Repmgr. Describiremos la configuración mínima que permitirá un cambio exitoso. Comenzamos con un PostgreSQL 10.4 principal en funcionamiento que se ejecuta en FreeBSD 11.1, compilado e instalado manualmente, y repmgr 4.0 también compilado e instalado manualmente para esta versión (10.4). Usaremos dos hosts llamados fbsd (192.168.1.80) y fbsdclone (192.168.1.81) con versiones idénticas de PostgreSQL y repmgr. En el principal (inicialmente fbsd , 192.168.1.80) nos aseguramos de que se establezcan los siguientes parámetros de PostgreSQL:
max_wal_senders = 10
wal_level = 'logical'
hot_standby = on
archive_mode = 'on'
archive_command = '/usr/bin/true'
wal_keep_segments = '1000' Luego creamos el usuario repmgr (como superusuario) y la base de datos:
example@sqldat.com:~ % createuser -s repmgr
example@sqldat.com:~ % createdb repmgr -O repmgry configure el control de acceso basado en host en pg_hba.conf colocando las siguientes líneas en la parte superior:
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.1.0/24 trustNos aseguramos de configurar el inicio de sesión sin contraseña para el usuario repmgr en todos los nodos del clúster, en nuestro caso, fbsd y fbsdclone configurando las claves_autorizadas en .ssh y luego compartiendo .ssh. Luego creamos repmrg.conf en el primario como:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=1
node_name=fbsd
conninfo='host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Luego registramos el primario:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf primary register
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (id: 1) registeredY verifique el estado del clúster:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2Ahora trabajamos en el modo de espera configurando repmgr.conf de la siguiente manera:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=2
node_name=fbsdclone
conninfo='host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'También nos aseguramos de que el directorio de datos especificado en la línea anterior exista, esté vacío y tenga los permisos correctos:
example@sqldat.com:~ % rm -fr data && mkdir data
example@sqldat.com:~ % chmod 700 dataAhora tenemos que clonar a nuestro nuevo modo de espera:
example@sqldat.com:~ % repmgr -h 192.168.1.80 -U repmgr -f /etc/repmgr.conf --force standby clone
NOTICE: destination directory "/usr/local/var/lib/pgsql/data" provided
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /usr/local/var/lib/pgsql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"E iniciar el modo de espera:
example@sqldat.com:~ % pg_ctl -D data startEn este punto, la replicación debería funcionar como se esperaba, verifique esto consultando pg_stat_replication (fbsd) y pg_stat_wal_receiver (fbsdclone). El siguiente paso es registrar el standby:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby registerAhora podemos obtener el estado del clúster en el standly o en el primario y verificar que el standby esté registrado:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | standby | running | fbsd | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Ahora supongamos que deseamos realizar un cambio manual programado para, p. para hacer un poco de trabajo de administración en el nodo fbsd. En el nodo de espera, ejecutamos el siguiente comando:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby switchover
…
NOTICE: STANDBY SWITCHOVER has completed successfully¡La conmutación se ha ejecutado con éxito! Veamos qué programa de clúster da:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+-----------+----------+---------------------------------------------------------------
1 | fbsd | standby | running | fbsdclone | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | primary | * running | | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2¡Los dos servidores han intercambiado roles! Repmgr proporciona el demonio repmgrd que proporciona supervisión, conmutación por error automática, así como notificaciones/alertas. Al combinar repmgrd con pgbouncer, es posible implementar la actualización automática de la información de conexión de la base de datos, lo que proporciona una protección para el primario fallido (evitando que la aplicación utilice el nodo fallido) y proporciona un tiempo de inactividad mínimo para la aplicación. En esquemas más complejos, otra idea es combinar Keepalived con HAProxy además de pgbouncer y repmgr, para lograr:
- equilibrio de carga (escalado)
- alta disponibilidad
Tenga en cuenta que ClusterControl también administra la conmutación por error de las configuraciones de replicación de PostgreSQL e integra HAProxy y VirtualIP para redirigir automáticamente las conexiones del cliente al maestro de trabajo. Puede encontrar más información en este documento técnico sobre la automatización de PostgreSQL.
Descargue el documento técnico hoy Gestión y automatización de PostgreSQL con ClusterControl Obtenga información sobre lo que necesita saber para implementar, monitorear, administrar y escalar PostgreSQLDescargar el documento técnicoEscalado
A partir de PostgreSQL 10 (y 11), todavía no hay forma de tener replicación multimaestro, al menos no desde el núcleo de PostgreSQL. Esto significa que solo se puede ampliar la actividad de selección (solo lectura). El escalado en PostgreSQL se logra agregando más esperas activas, lo que proporciona más recursos para la actividad de solo lectura. Con repmgr, es fácil agregar un nuevo modo de espera como vimos anteriormente a través de clonación en espera y registro en espera comandos Los recursos de reserva agregados (o eliminados) deben informarse a la configuración del balanceador de carga. HAProxy, como se mencionó anteriormente en el tema de administración, es un equilibrador de carga popular para PostgreSQL. Por lo general, se combina con Keepalived, que proporciona IP virtual a través de VRRP. Puede encontrar una buena descripción general del uso de HAProxy y Keepalived junto con PostgreSQL en este artículo:Equilibrio de carga de PostgreSQL con HAProxy y Keepalived.
Monitoreo
Puede encontrar una descripción general de qué monitorear en PostgreSQL en este artículo:Cosas clave para monitorear en PostgreSQL:análisis de su carga de trabajo. Hay muchas herramientas que pueden proporcionar monitoreo del sistema y postgresql a través de complementos. Algunas herramientas cubren el área de presentación de gráficos de valores históricos (munin), otras herramientas cubren el área de monitoreo de datos en vivo y brindan alertas en vivo (nagios), mientras que algunas herramientas cubren ambas áreas (zabbix). Puede encontrar una lista de dichas herramientas para PostgreSQL aquí:https://wiki.postgresql.org/wiki/Monitoring. Una herramienta popular para el monitoreo fuera de línea (basado en archivos de registro) es pgBadger. pgBadger es un script de Perl que funciona analizando el registro de PostgreSQL (que generalmente cubre la actividad de un día), extrayendo información, calculando estadísticas y finalmente produciendo una elegante página html que presenta los resultados. pgBadger no es restrictivo en la configuración de log_line_prefix, puede adaptarse a su formato ya existente. Por ejemplo, si ha configurado en su postgresql.conf algo como:
log_line_prefix = '%r [%p] %c %m %a %example@sqldat.com%d line:%l 'luego, el comando pgbadger para analizar el archivo de registro y producir los resultados puede verse así:
./pgbadger --prefix='%r [%p] %c %m %a %example@sqldat.com%d line:%l ' -Z +2 -o pgBadger_$today.html $yesterdayfile.log && rm -f $yesterdayfile.logpgBadger proporciona informes para:
- Estadísticas generales (principalmente tráfico de SQL)
- Conexiones (por segundo, por base de datos/usuario/host)
- Sesiones (número, tiempos de sesión, por base de datos/usuario/host/aplicación)
- Puntos de control (búferes, archivos wal, actividad)
- Uso de archivos temporales
- Vacío/Analizar actividad (por tabla, tuplas/páginas eliminadas)
- Cerraduras
- Consultas (por tipo/base de datos/usuario/host/aplicación, duración por usuario)
- Principales (Consultas:más lento, lento, más frecuente, normalizado más lento)
- Eventos (Errores, Advertencias, Fatales, etc.)
La pantalla que muestra las sesiones se ve así:
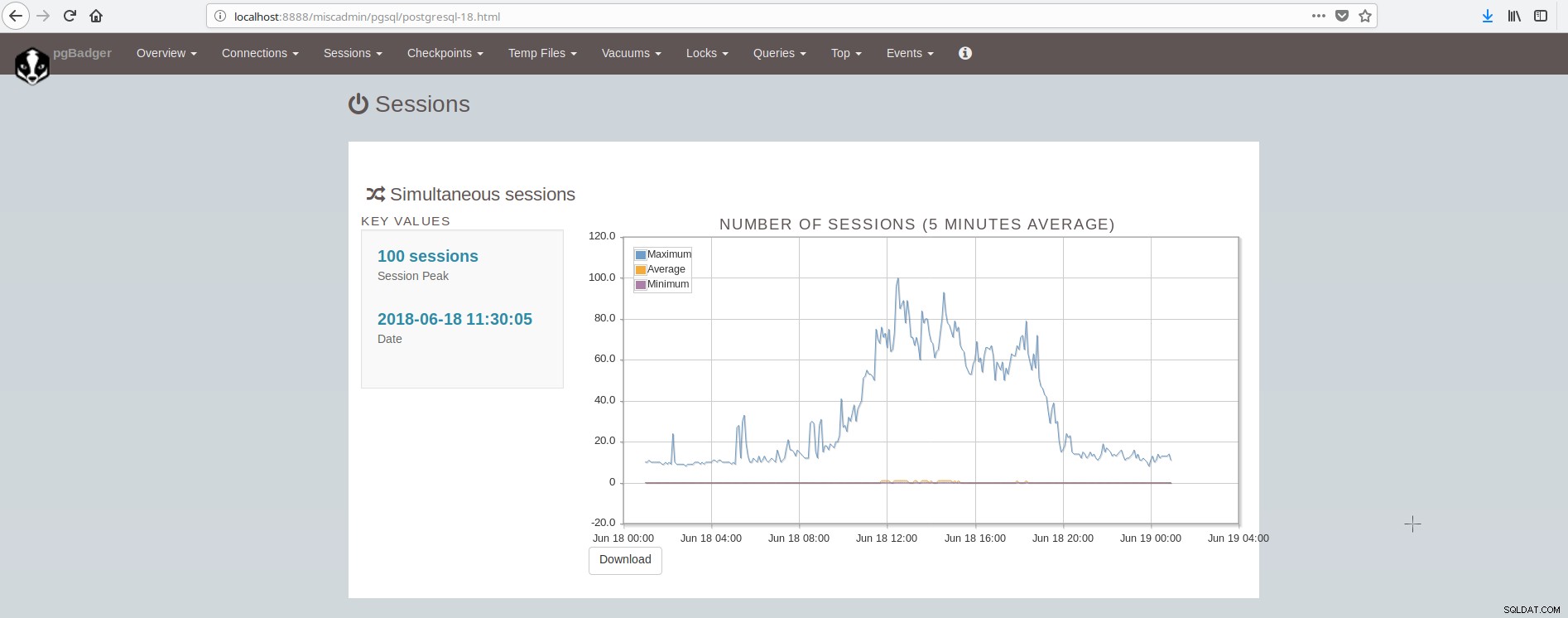
Como podemos concluir, la instalación promedio de PostgreSQL tiene que integrar y cuidar muchas herramientas para tener una infraestructura moderna, confiable y rápida, y esto es bastante complejo de lograr, a menos que haya grandes equipos involucrados en postgresql y la administración del sistema. Una excelente suite que hace todo lo anterior y más es ClusterControl.