Introducción
Hoy en día, la alta disponibilidad es un requisito para muchos sistemas, independientemente de la tecnología que utilice. Esto es especialmente importante para las bases de datos, ya que almacenan datos en los que se basan las aplicaciones y los sistemas críticos. La estrategia más común para lograr una alta disponibilidad es la replicación. Hay diferentes formas de replicar datos en varios servidores y conmutar el tráfico cuando, por ejemplo, un servidor principal deja de responder.
Arquitectura de alta disponibilidad para PostgreSQL
Existen varias arquitecturas para implementar alta disponibilidad en PostgreSQL, pero las básicas son arquitecturas primaria-espera y primaria-primaria.
Arquitecturas Primaria-Standby
Primary-Standby puede ser la arquitectura HA más básica que puede configurar y, a menudo, la más fácil de implementar y mantener. Se basa en una base de datos principal con uno o más servidores en espera. Estas bases de datos Standby permanecerán sincronizadas (o casi sincronizadas) con el nodo Primario, dependiendo de si la replicación es síncrona o asíncrona. Si el servidor principal falla, el servidor en espera contiene casi todos los datos del servidor principal y puede convertirse rápidamente en el nuevo servidor de base de datos principal.
Puede implementar dos tipos de bases de datos en espera, según la naturaleza de la replicación:
- Lógica Standbys:la replicación entre Primaria y Standby se realiza a través de sentencias SQL.
- Suplentes físicos:la replicación entre primario y suplente se realiza a través de modificaciones de la estructura de datos interna.
En el caso de PostgreSQL, se utiliza un flujo de registros de escritura anticipada (WAL) para mantener sincronizadas las bases de datos en espera. Esto puede ser síncrono o asíncrono, y se replica todo el servidor de la base de datos.
A partir de la versión 10, PostgreSQL incluye una opción integrada para configurar la replicación lógica, que construye un flujo de modificaciones de datos lógicos a partir de la información en el registro de escritura anticipada. Este método de replicación permite replicar los cambios de datos de tablas individuales sin necesidad de designar un servidor principal. También permite que los datos fluyan en múltiples direcciones.
Desafortunadamente, una configuración principal-en espera no es suficiente para garantizar una alta disponibilidad de manera efectiva, ya que también debe manejar las fallas. Para manejar las fallas, debe poder detectarlas. Una vez que sepa que hay una falla, por ejemplo, errores en el nodo principal o que el nodo no responde, puede seleccionar un nodo en espera para reemplazar el nodo fallido con la menor demora posible. Este proceso debe ser lo más eficiente posible para restaurar la funcionalidad completa de las aplicaciones. PostgreSQL en sí mismo no incluye un mecanismo de conmutación por error automático, por lo que requerirá algunas secuencias de comandos personalizadas o herramientas de terceros para esta automatización.
Después de que ocurra una conmutación por error, su aplicación debe recibir una notificación correspondiente para comenzar a usar el nuevo Primario. También debe evaluar el estado de su arquitectura después de la conmutación por error porque puede encontrarse con una situación en la que solo se está ejecutando el nuevo principal (por ejemplo, tenía un nodo principal y solo uno en espera antes del problema). En ese caso, deberá agregar un nodo en espera para volver a crear la configuración principal-en espera que tenía originalmente para alta disponibilidad.
Arquitecturas Primaria-Primaria
La arquitectura primaria-primaria proporciona una forma de minimizar el impacto de un error en uno de los nodos, ya que los otros nodos pueden encargarse de todo el tráfico, afectando solo levemente el rendimiento. pero sin perder nunca la funcionalidad. La arquitectura Primaria-Primaria a menudo se usa con el doble propósito de crear un entorno de alta disponibilidad y escalar horizontalmente (en comparación con el concepto de escalabilidad vertical donde se agregan más recursos a un servidor).
PostgreSQL aún no es compatible con esta arquitectura "de forma nativa", por lo que deberá consultar herramientas e implementaciones de terceros. Al elegir una solución, debe tener en cuenta que hay muchos proyectos/herramientas, pero algunos de ellos ya no son compatibles, mientras que otros son nuevos y es posible que no se hayan probado en batalla en producción.
Equilibrio de carga
Los balanceadores de carga son herramientas que se pueden usar para administrar el tráfico de su aplicación para aprovechar al máximo la arquitectura de su base de datos.
Estas herramientas no solo son útiles para equilibrar la carga de sus bases de datos, sino que también ayudan a que las aplicaciones se redirijan a los nodos disponibles/en buen estado e incluso especifican puertos con diferentes funciones.
HAProxy es un balanceador de carga que distribuye el tráfico desde un origen a uno o más destinos y puede definir reglas y/o protocolos específicos para esta tarea. Si alguno de los destinos deja de responder, se marca como desconectado y el tráfico se envía al resto de destinos disponibles.
Keepalived es un servicio que le permite configurar una dirección IP virtual dentro de un grupo activo/pasivo de servidores. Esta dirección IP virtual está asignada a un servidor activo. Si este servidor falla, la dirección IP se migra automáticamente al servidor pasivo “Secundario”, lo que le permite seguir trabajando con la misma dirección IP de forma transparente para los sistemas.
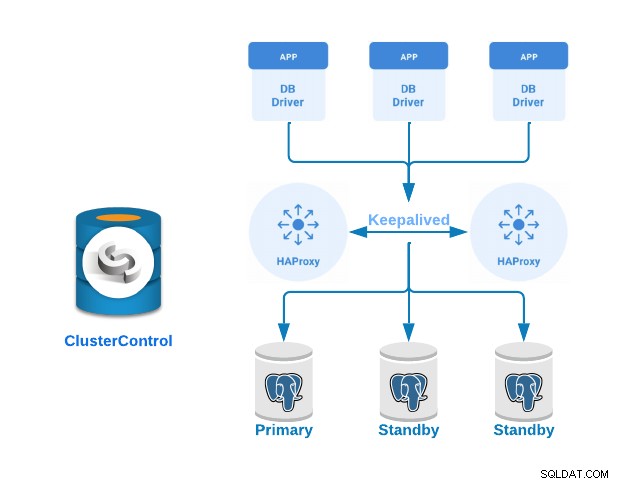
Veamos ahora cómo implementar un clúster de PostgreSQL principal-en espera con servidores equilibradores de carga y mantenimiento configurado entre ellos. Demostraremos esto usando la interfaz fácil de usar de ClusterControl.
Para este ejemplo, crearemos:
- 3 servidores PostgreSQL (uno principal y dos en espera).
- 2 balanceadores de carga HAProxy.
- Keepalived configurado entre los servidores del balanceador de carga.
Despliegue de base de datos
Para implementar una base de datos usando ClusterControl, simplemente seleccione la opción "Implementar" y siga las instrucciones que aparecen.
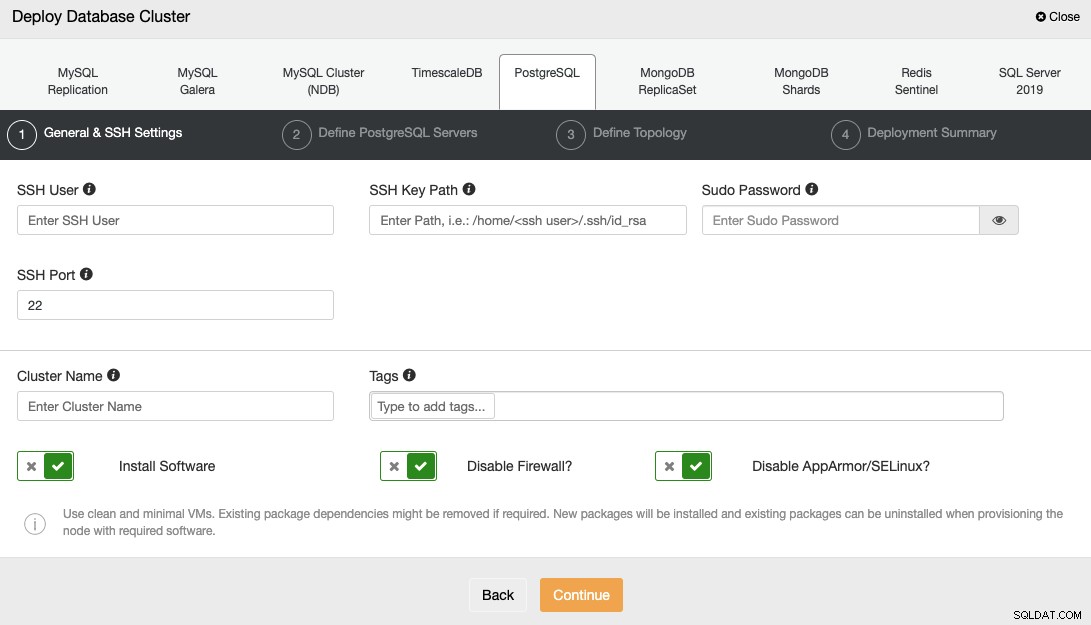
Al seleccionar PostgreSQL, debe especificar el Usuario, Clave o Contraseña, y Puerto para conectarse por SSH a sus servidores. También necesita el nombre de su nuevo clúster y elegir si desea que ClusterControl instale el software y las configuraciones correspondientes por usted.
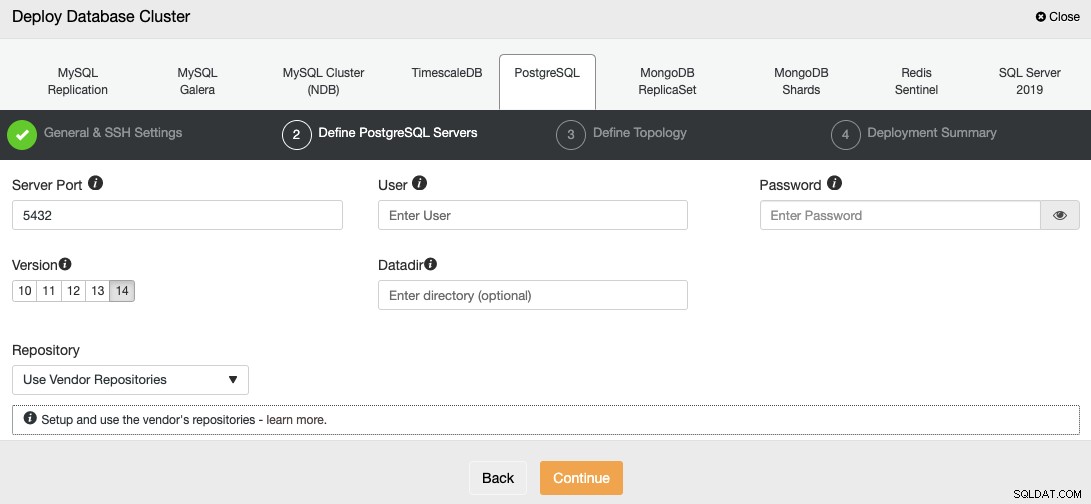
Después de configurar la información de acceso SSH, debe definir el usuario de la base de datos, versión y datadir (opcional). También puede especificar qué repositorio usar; el repositorio oficial de proveedores se utilizará de forma predeterminada.
En el siguiente paso, debe agregar sus servidores al clúster que creará.
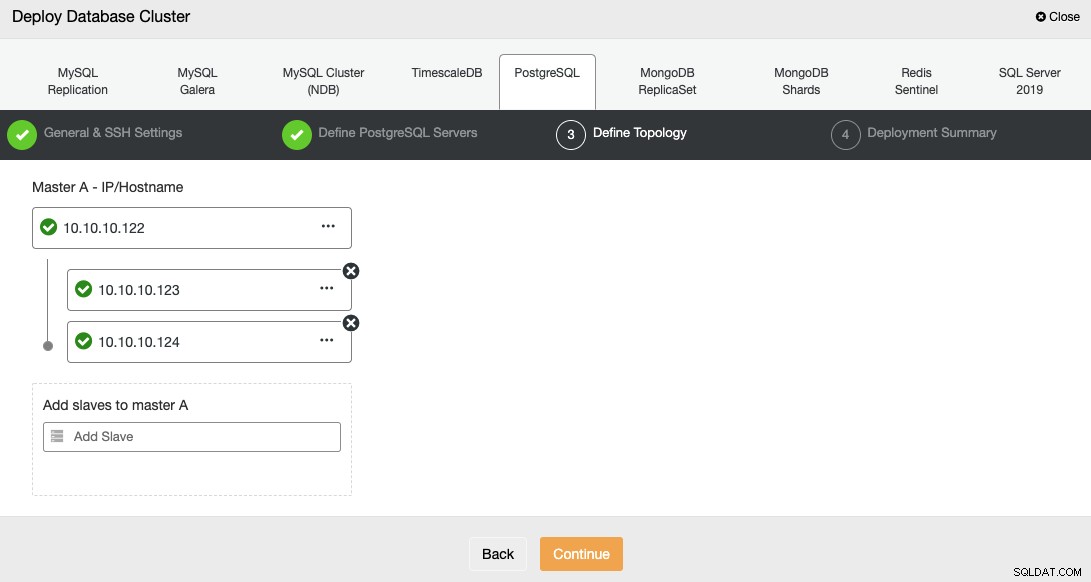
Al agregar sus servidores, puede ingresar la IP o el nombre de host.
En el último paso, puede elegir si su replicación será Sincrónica o Asincrónica.
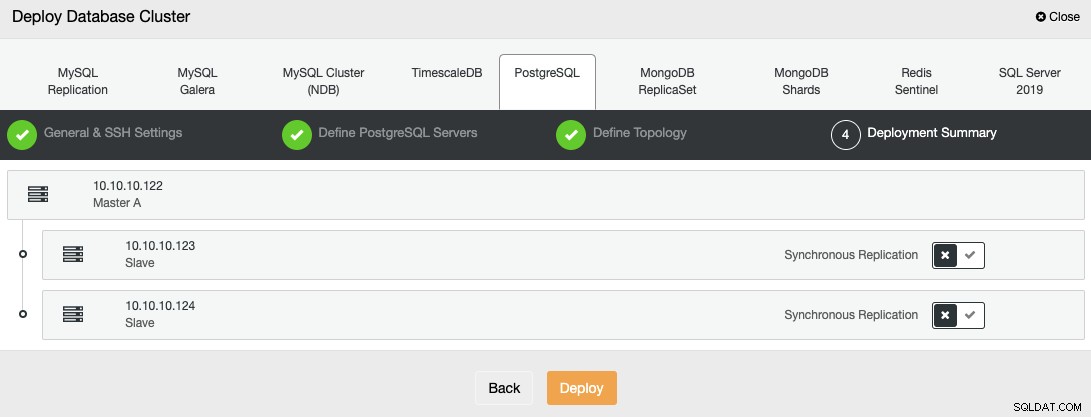
Puede monitorear el estado de la creación de su nuevo clúster desde el ClusterControl monitor de actividad.
Una vez finalizada la tarea, puede ver su clúster en el ClusterControl principal pantalla.
Una vez creado su clúster, puede realizar varias tareas, como agregar un equilibrador de carga (HAProxy) o una nueva réplica.
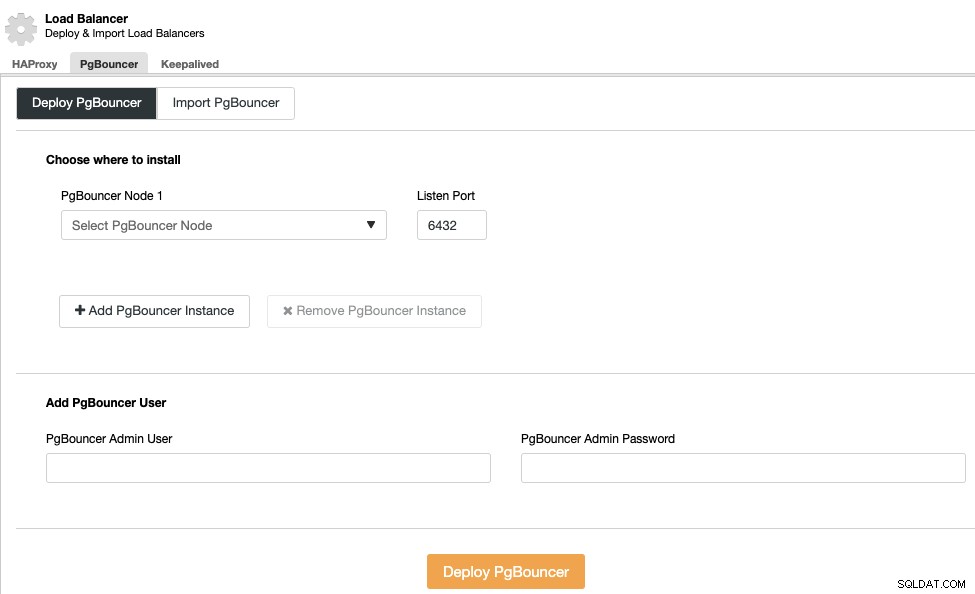
Implementación del equilibrador de carga
Para realizar una implementación del balanceador de carga, seleccione la opción "Agregar balanceador de carga" en las acciones del clúster y complete la información solicitada.
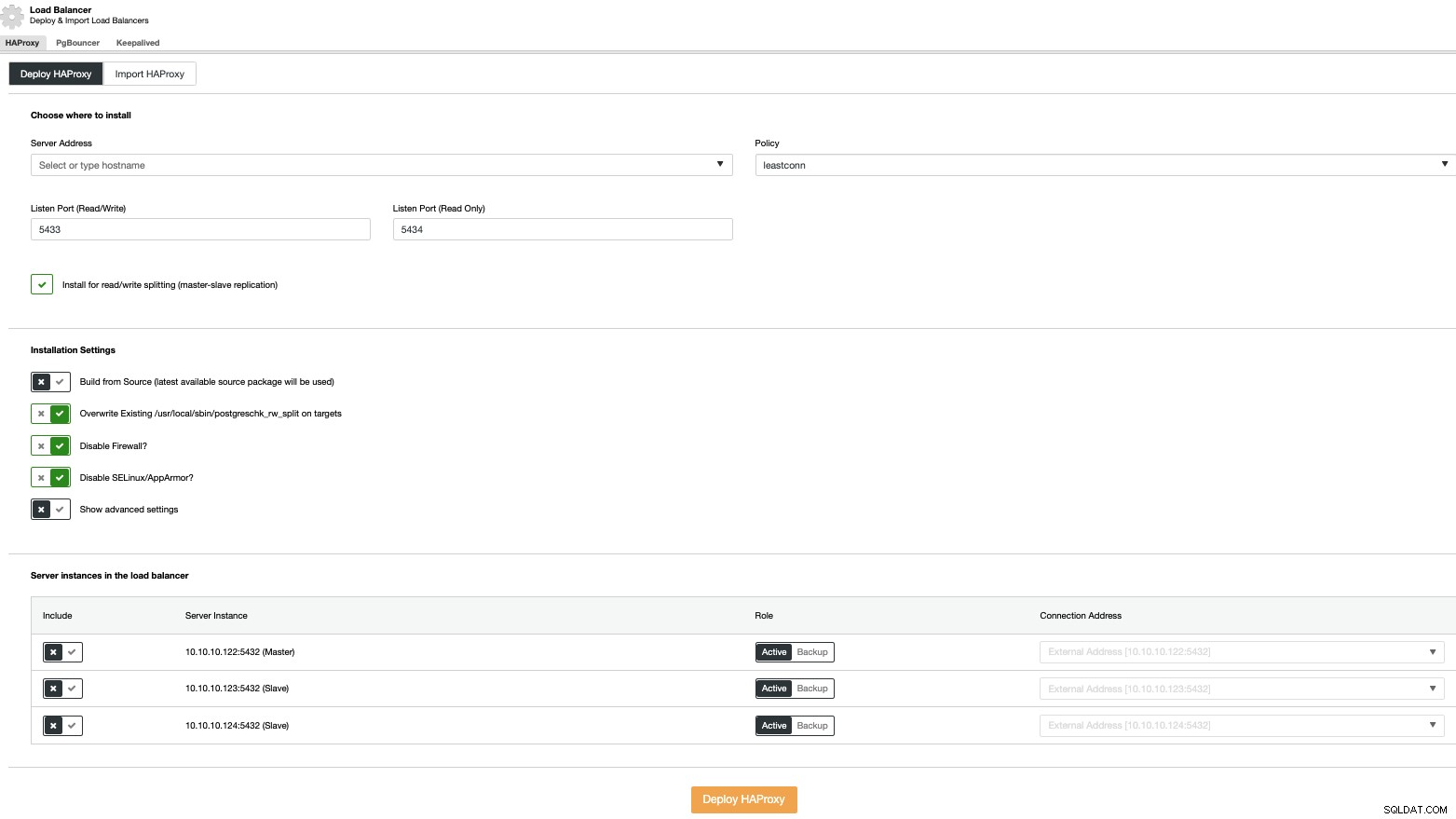
Solo necesita agregar la dirección IP o nombre de host, puerto, política, y los nodos que configurarás en tus balanceadores de carga.
Implementación mantenida
Para realizar una implementación de mantenimiento, seleccione el clúster, vaya al menú "Administrar" y a la sección "Balanceador de carga", y luego seleccione la opción "Mantener vivo".
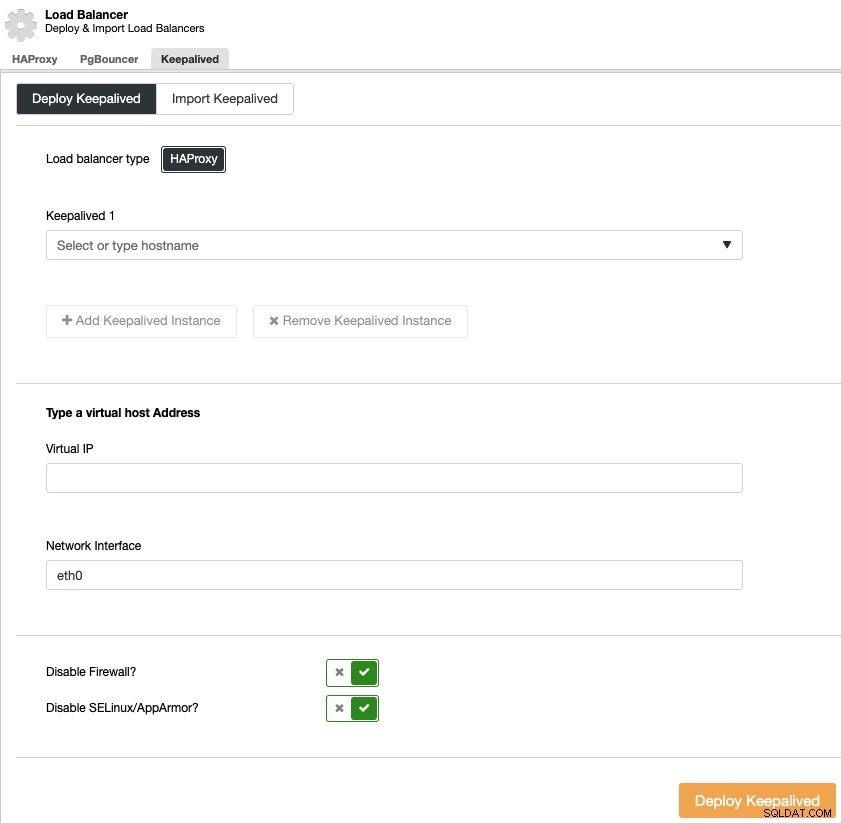
Debe seleccionar los servidores del balanceador de carga y la dirección IP virtual para su alta entorno de disponibilidad.
Keepalived usa la dirección IP virtual y la migra de un balanceador de carga a otro en caso de falla, para que sus sistemas puedan continuar funcionando normalmente.
Si siguió los pasos anteriores, debería tener la siguiente topología:
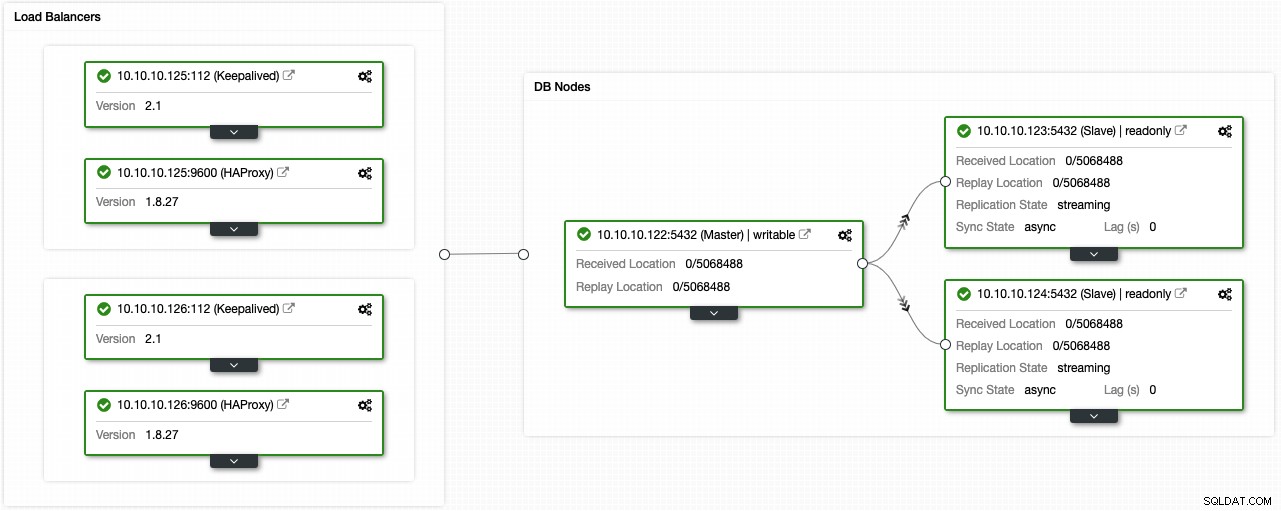
Puede mejorar este entorno de alta disponibilidad agregando un agrupador de conexiones como PgBouncer. No es obligatorio, pero podría ser útil para mejorar el rendimiento y manejar las conexiones activas en caso de falla, y lo mejor es que también puede implementarlo mediante ClusterControl.
Conmutación por error del control de clúster
Suponga que la opción "Recuperación automática" está activada en su servidor ClusterControl. En caso de una falla principal, ClusterControl promoverá el Standby más avanzado (si no está en la lista negra) a Principal, y también le notificará el problema. También conmutará por error el resto de los nodos en espera para replicar desde el nuevo principal.
HAProxy está configurado por defecto con dos puertos diferentes; puertos de lectura-escritura y solo lectura.
En su puerto de lectura y escritura, tiene su servidor principal en línea y el resto de sus nodos fuera de línea, y en el puerto de solo lectura, tiene en línea tanto el servidor principal como el de reserva.
Cuando HAProxy detecta que uno de sus nodos, ya sea principal o en espera, no está accesible, automáticamente lo marca como fuera de línea. No lo tiene en cuenta para enviarle tráfico. La detección se realiza mediante scripts de verificación de estado que ClusterControl configura en el momento de la implementación. Estos comprueban si las instancias están activas, si se están recuperando o si son de solo lectura.
Cuando ClusterControl promueve un Standby a Primario, su HAProxy marca el Primario anterior como fuera de línea para ambos puertos y pone el nodo promovido en línea en el puerto de lectura y escritura.
Si su HAProxy activo, que ha asignado la dirección IP virtual a la que se conectan sus sistemas, falla, Keepalived migra esta dirección IP a su HAProxy pasivo automáticamente. Esto significa que sus sistemas podrán continuar funcionando normalmente.
De esta manera, sus sistemas continúan funcionando como se espera y sin su intervención manual.
Consideraciones
Si logra recuperar su antiguo nodo principal fallido, NO se volverá a introducir automáticamente en el clúster de forma predeterminada. Tienes que hacerlo manualmente. Una razón para esto es que si su réplica se retrasó en el momento de la falla y ClusterControl agrega el principal anterior al clúster, significaría pérdida de información o inconsistencia de datos entre los nodos. También es posible que desee analizar el problema en detalle. Si ClusterControl acaba de volver a introducir el nodo fallido en el clúster, es posible que pierda la información de diagnóstico.
Además, si falla la conmutación por error, no se realizan más intentos. Se requiere intervención manual para analizar el problema y realizar las acciones correspondientes. Esto es para evitar la situación en la que ClusterControl, como administrador de alta disponibilidad, intenta promocionar el siguiente Standby y el siguiente. Es posible que haya un problema y deberá comprobarlo.
Seguridad
Una cosa importante que no puede olvidar antes de entrar en producción con su entorno de alta disponibilidad es garantizar su seguridad.
Varios aspectos de seguridad a considerar incluyen el cifrado, la gestión de funciones y la restricción de acceso por dirección IP, que hemos tratado en profundidad en un blog anterior.
En su base de datos PostgreSQL, tiene el archivo pg_hba.conf, que maneja la autenticación del cliente. Puede limitar el tipo de conexión, la dirección IP de origen o la red, a qué base de datos puede conectarse y con qué usuarios. Por lo tanto, este archivo es una pieza fundamental para la seguridad de PostgreSQL.
Puede configurar su base de datos PostgreSQL desde el archivo postgresql.conf, para que solo escuche en una interfaz de red específica y en un puerto diferente al predeterminado (5432), evitando así intentos de conexión básicos de fuentes no deseadas .
La administración adecuada de usuarios, ya sea usando contraseñas seguras o limitando el acceso y los privilegios, es otra pieza vital de su configuración de seguridad. Se recomienda que asigne la menor cantidad de privilegios posible a todos los usuarios y especifique, si es posible, la fuente de la conexión.
También puede habilitar el cifrado de datos, ya sea en tránsito o en reposo, evitando el acceso a la información a personas no autorizadas.
Un registro de auditoría es útil para comprender lo que sucede o ha sucedido en su base de datos. PostgreSQL le permite configurar varios parámetros para iniciar sesión o incluso usar la extensión pgAudit para esta tarea.
Por último, pero no menos importante, se recomienda mantener su base de datos y servidores actualizados con los últimos parches para evitar riesgos de seguridad. Para ello, ClusterControl te permite generar informes operativos para verificar si tienes actualizaciones disponibles e incluso ayudarte a actualizar tus servidores de bases de datos.
Conclusión
Las implementaciones de alta disponibilidad pueden parecer difíciles de lograr, especialmente cuando se trata de comprender las diferentes arquitecturas y los componentes necesarios para configurarlas correctamente.
Si está administrando HA manualmente, asegúrese de consultar Realización de cambios en la topología de replicación para PostgreSQL. Muchos buscarán herramientas como ClusterControl para ayudar a administrar la implementación, los balanceadores de carga, la conmutación por error, la seguridad y más para un entorno completo de alta disponibilidad. Puede descargar ClusterControl gratis durante 30 días para ver cómo puede aliviar la carga de administrar una infraestructura de base de datos de alta disponibilidad.
Independientemente de cómo elija administrar sus bases de datos PostgreSQL de alta disponibilidad, asegúrese de seguirnos en Twitter o LinkedIn, o suscríbase a nuestro boletín para obtener las últimas actualizaciones y las mejores prácticas para administrar las configuraciones de su base de datos.