Al implementar un clúster de base de datos en diferentes servidores, habrá logrado la ventaja de replicación de mejorar la disponibilidad de datos. Sin embargo, es necesario realizar un seguimiento de los procesos y ver si se están ejecutando o no. Uno de los programas utilizados en este proceso es Heartbeat, que tiene la capacidad de verificar y verificar la presencia de recursos en uno o más sistemas en un clúster determinado. Además de PostgreSQL y los sistemas de archivos para los que se almacenan los datos de PostgreSQL, el DRBD es uno de los recursos que discutiremos en este artículo sobre cómo se puede usar el programa Heartbeat.
HA Heartbeat
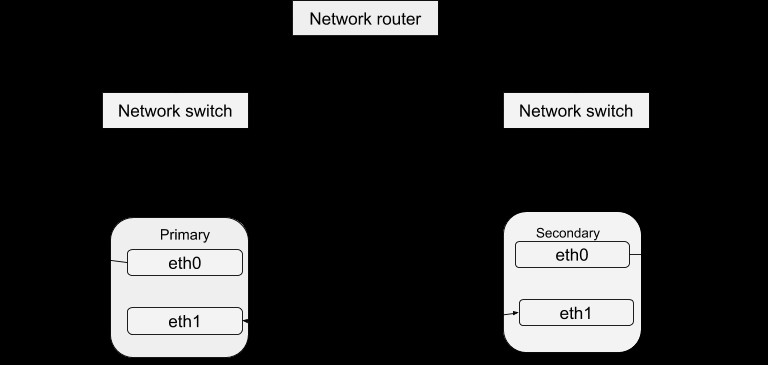
Como se discutió anteriormente en el blog de DRBD, tener una alta disponibilidad de datos se logra mediante la ejecución de diferentes instancias del servidor pero sirviendo los mismos datos. Estas instancias de servidor en ejecución se pueden definir como un clúster en relación con un Heartbeat. Básicamente, cada una de las instancias del servidor es físicamente capaz de proporcionar el mismo servicio que las demás dentro de ese clúster. Sin embargo, solo una instancia puede brindar activamente el servicio a la vez con el fin de garantizar una alta disponibilidad de los datos. Por lo tanto, podemos definir las otras instancias como "repuestos dinámicos" que pueden ponerse en servicio en caso de falla del maestro. El paquete Heartbeat se puede descargar desde este enlace. Después de instalar este paquete, puede configurarlo para que funcione con su sistema con el siguiente procedimiento. Una estructura simple de la configuración de Heartbeat es:
Configuración de Heartbeat
Buscando en este directorio /etc/ha.d encontrará algunos archivos que se utilizan en el proceso de configuración. El archivo ha.cf forma la configuración principal de latidos. Incluye la lista de todos los nodos y tiempos para identificar fallas además de dirigir el latido sobre qué tipo de rutas de medios usar y cómo configurarlas. La información de seguridad del clúster se registra en el archivo authkeys. La información registrada en estos archivos debe ser idéntica para todos los hosts del clúster y esto se puede lograr fácilmente sincronizando todos los hosts. Esto quiere decir que cualquier cambio de información en un host debe copiarse en todos los demás.
Archivo Ha.cf
El esquema básico del archivo ha.cf es
logfacility local0
keepalive 3
Deadtime 7
warntime 3
initdead 30
mcast eth0 225.0.0.1 694 2 0
mcast eth1 225.0.0.2 694 1 0
auto_failback off
node drbd1
node drbd2
node drbd3-
Logfacility:este se usa para dirigir el Heartbeat en qué instalación de registro de syslog debe usar para grabar mensajes. Los valores más utilizados son auth, authpriv, user, local0, syslog y daemon. También puede decidir no tener ningún registro, por lo que puede establecer el valor en ninguno, es decir,
logfacility none - Keepalive:este es el tiempo entre latidos, es decir, la frecuencia con la que se envía la señal del latido a los otros hosts. En el código de muestra anterior, se establece en 3 segundos.
- Tiempo muerto:es el retraso en segundos después del cual se declara que un nodo ha fallado.
- Tiempo de advertencia:es el retraso en segundos después del cual se registra una advertencia en un registro que indica que ya no se puede contactar con un nodo.
- Initdead:este es el tiempo en segundos de espera durante el inicio del sistema antes de que se considere que el otro host está inactivo.
- Mcast:es un procedimiento de método definido para enviar una señal de latido. Para el código de muestra anterior, la dirección de red de multidifusión se usa en un dispositivo de red limitada. Para un clúster múltiple, la dirección de multidifusión debe ser única para cada clúster. También puede elegir una conexión en serie sobre la multidifusión o, si la configura de tal manera que haya múltiples interfaces de red, use ambas para la conexión de latido como en el ejemplo. La ventaja de usar ambos es superar las posibilidades de fallas transitorias que, en consecuencia, pueden causar un evento de falla no válido.
- Auto_failback:esto vuelve a conectar un servidor que había fallado al clúster si vuelve a estar disponible. Sin embargo, puede causar confusión si el servidor está encendido y luego vuelve a estar en línea en un momento diferente. En relación con el DRBD, si no está bien configurado, puede terminar con más de un conjunto de datos en el mismo servidor. Por lo tanto, es recomendable configurarlo siempre en apagado.
- Nodo:describe el nodo dentro del grupo de clústeres Heartbeat. Debe tener al menos 1 nodo para cada uno.
Configuraciones adicionales
También puede establecer información de configuración adicional como:
ping 10.0.0.1
respawn hacluster /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=haclient uid=hacluster
deadping 5- Ping:esto es importante para garantizar que tenga conectividad en la interfaz pública para los servidores y conexión a otro host. Es importante considerar la dirección IP en lugar del nombre de host para la máquina de destino.
- Respawn:este es el comando que se ejecuta cuando ocurre una falla.
- Apiauth:es la autoridad para el fallo. Debe configurar el ID de usuario y grupo con el que se ejecutará el comando. El archivo authkeys contiene la información de autorización para el clúster de Heartbeat y esta clave es única para verificar máquinas dentro de un clúster de Heartbeat determinado.
- Deadping:define el tiempo de espera antes de que una falta de respuesta desencadene un error.
Integración de Heartbeat con Postgres y DRBD
Como se mencionó anteriormente, cuando falla un servidor maestro, otro servidor con un clúster determinado entrará en acción para brindar el mismo servicio. Heartbeat ayuda en la configuración de recursos que mejoran la selección de un servidor en caso de falla. Por ejemplo, define qué servidores individuales deben activarse o descartarse en caso de falla. Al ingresar al archivo haresources en el directorio /etc/ha.d, obtenemos un resumen de los recursos que se pueden administrar. La ruta del archivo de recursos es /etc/ha.d/resource.d y la definición de recursos está en una línea que es:
drbd1 drbddisk Filesystem::/dev/drbd0::/drbd::ext3 postgres 10.0.0.1(tenga en cuenta los espacios en blanco).
- Drbd1:se refiere al nombre del host preferido para ser más secante que el servidor que normalmente se usa como maestro predeterminado para manejar el servicio. Como se menciona en el blog de DRBD, necesitamos recursos para nuestro servidor y estos se definen en la línea como drbddisk, filesystem y postgres. El último campo es una dirección IP virtual que debe usarse para compartir el servicio, es decir, conectarse al servidor de Postgres. De forma predeterminada, se asignará al servidor que esté activo cuando comience Heartbeat. Cuando ocurre una falla, estos recursos se iniciarán en el servidor de respaldo en orden de disposición cuando se llame al script correspondiente. En la configuración, la secuencia de comandos cambiará el disco DRBD en el host secundario al modo principal, haciendo que el dispositivo lea/escriba.
- Sistema de archivos:administrará los recursos del sistema de archivos y, en este caso, se ha seleccionado DRBD, por lo que se montará durante la llamada del script de recursos.
- Postgres:esto iniciará o administrará el servidor de Postgres
A veces querrás recibir notificaciones por correo electrónico. Para hacerlo, agregue esta línea al archivo de recursos con su correo electrónico para recibir los textos de advertencia:
MailTo:: example@sqldat.com::DRBDFailurePara iniciar el latido del corazón, puede ejecutar el comando
/etc/ha.d/heartbeat starto reinicie los servidores principal y secundario. Ahora si ejecutas el comando
$ /usr/lib64/heartbeat/hb_standbyEl nodo actual se activará para ceder sus recursos limpiamente al otro nodo.
Descargue el documento técnico hoy Gestión y automatización de PostgreSQL con ClusterControl Obtenga información sobre lo que necesita saber para implementar, monitorear, administrar y escalar PostgreSQLDescargar el documento técnicoManejo de errores a nivel del sistema
A veces, el kernel del servidor puede estar dañado, lo que indica un problema potencial con su servidor. Deberá configurar el servidor para que se elimine del clúster en caso de que surja un problema. Este problema a menudo se conoce como kernel panic y, en consecuencia, provoca un reinicio completo en su máquina. Puede forzar un reinicio configurando kernel.panic y kernel.panic_on_oop del archivo de control del kernel /etc/sysctl.conf. Es decir
kernel.panic_on_oops = 1
kernel.panic = 1Otra opción es hacerlo desde la línea de comandos usando el comando sysctl, es decir:
$ sysctl -w kernel.panic=1También puede editar el archivo sysctl.conf y recargar la información de configuración usando este comando.
sysctl -pEl valor indica el número de segundos de espera antes de reiniciar. El segundo nodo de latido debería detectar que el servidor está inactivo y luego cambiar el host de conmutación por error.
Conclusión
Heartbeat es un subsistema que permite la selección de un servidor secundario en el primario y un sistema de respaldo cuando falla un servidor activo. También determina si todos los demás servidores están activos. También asegura la transferencia de recursos al nuevo nodo primario