La alta disponibilidad es un requisito para casi todas las empresas del mundo que utilizan PostgreSQL. Es bien sabido que PostgreSQL utiliza Streaming Replication como método de replicación. La replicación de transmisión de PostgreSQL es asíncrona de forma predeterminada, por lo que es posible que se confirmen algunas transacciones en el nodo principal que aún no se han replicado en el servidor de reserva. Esto significa que existe la posibilidad de una posible pérdida de datos.
Se supone que este retraso en el proceso de confirmación es muy pequeño... si el servidor en espera es lo suficientemente potente como para mantenerse al día con la carga. Si este pequeño riesgo de pérdida de datos no es aceptable en la empresa, también puede utilizar la replicación síncrona en lugar de la predeterminada.
En la replicación síncrona, cada confirmación de una transacción de escritura esperará hasta la confirmación de que la confirmación se ha escrito en el registro de escritura anticipada en el disco del servidor primario y en espera.
Este método minimiza la posibilidad de pérdida de datos. Para que se produzca la pérdida de datos, necesitaría que tanto el principal como el de reserva fallaran al mismo tiempo.
La desventaja de este método es la misma para todos los métodos síncronos, ya que con este método aumenta el tiempo de respuesta para cada transacción de escritura. Esto se debe a la necesidad de esperar hasta todas las confirmaciones de que se comprometió la transacción. Afortunadamente, las transacciones de solo lectura no se verán afectadas por esto, pero; solo las transacciones de escritura.
En este blog, se muestra cómo instalar un clúster de PostgreSQL desde cero, convertir la replicación asincrónica (predeterminada) en síncrona. También le mostraré cómo revertir si el tiempo de respuesta no es aceptable, ya que puede volver fácilmente al estado anterior. Verá cómo implementar, configurar y monitorear una replicación síncrona de PostgreSQL fácilmente usando ClusterControl usando una sola herramienta para todo el proceso.
Instalación de un clúster de PostgreSQL
Comencemos a instalar y configurar una replicación asíncrona de PostgreSQL, que es el modo de replicación habitual que se usa en un clúster de PostgreSQL. Usaremos PostgreSQL 11 en CentOS 7.
Instalación de PostgreSQL
Siguiendo la guía de instalación oficial de PostgreSQL, esta tarea es bastante simple.
Primero, instale el repositorio:
$ yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpmInstalar los paquetes de cliente y servidor de PostgreSQL:
$ yum install postgresql11 postgresql11-serverInicializar la base de datos:
$ /usr/pgsql-11/bin/postgresql-11-setup initdb
$ systemctl enable postgresql-11
$ systemctl start postgresql-11En el nodo en espera, puede evitar el último comando (iniciar el servicio de base de datos) ya que restaurará una copia de seguridad binaria para crear la replicación de transmisión.
Ahora, veamos la configuración requerida por una replicación asincrónica de PostgreSQL.
Configuración de la replicación asincrónica de PostgreSQL
Configuración del nodo principal
En el nodo principal de PostgreSQL, debe usar la siguiente configuración básica para crear una replicación asíncrona. Los archivos que se modificarán son postgresql.conf y pg_hba.conf. En general, están en el directorio de datos (/var/lib/pgsql/11/data/) pero puede confirmarlo en el lado de la base de datos:
postgres=# SELECT setting FROM pg_settings WHERE name = 'data_directory';
setting
------------------------
/var/lib/pgsql/11/data
(1 row)Postgresql.conf
Cambie o agregue los siguientes parámetros en el archivo de configuración postgresql.conf.
Aquí debe agregar la(s) dirección(es) IP donde escuchar. El valor predeterminado es 'localhost' y, para este ejemplo, usaremos '*' para todas las direcciones IP en el servidor.
listen_addresses = '*' Establezca el puerto del servidor donde escuchar. Por defecto 5432.
port = 5432 Determinar cuánta información se escribe en los WAL. Los valores posibles son mínimo, réplica o lógico. El valor hot_standby se asigna a réplica y se utiliza para mantener la compatibilidad con versiones anteriores.
wal_level = hot_standbyEstablezca el número máximo de procesos walsender, que administran la conexión con un servidor en espera.
max_wal_senders = 16Establezca la cantidad mínima de archivos WAL que se mantendrán en el directorio pg_wal.
wal_keep_segments = 32Cambiar estos parámetros requiere reiniciar el servicio de la base de datos.
$ systemctl restart postgresql-11Pg_hba.conf
Cambie o agregue los siguientes parámetros en el archivo de configuración pg_hba.conf.
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user IP_STANDBY_NODE/32 md5
host replication replication_user IP_PRIMARY_NODE/32 md5Como puede ver, aquí debe agregar el permiso de acceso del usuario. La primera columna es el tipo de conexión, que puede ser host o local. Luego, debe especificar la base de datos (replicación), el usuario, la dirección IP de origen y el método de autenticación. Cambiar este archivo requiere una recarga del servicio de base de datos.
$ systemctl reload postgresql-11Debe agregar esta configuración en los nodos principal y en espera, ya que la necesitará si el nodo en espera asciende a maestro en caso de falla.
Ahora, debe crear un usuario de replicación.
Rol de replicación
El ROL (usuario) debe tener el privilegio de REPLICACIÓN para usarlo en la replicación de transmisión.
postgres=# CREATE ROLE replication_user WITH LOGIN PASSWORD 'PASSWORD' REPLICATION;
CREATE ROLEDespués de configurar los archivos correspondientes y la creación del usuario, debe crear una copia de seguridad coherente desde el nodo principal y restaurarla en el nodo en espera.
Configuración de nodo en espera
En el nodo en espera, vaya al directorio /var/lib/pgsql/11/ y mueva o elimine el directorio de datos actual:
$ cd /var/lib/pgsql/11/
$ mv data data.bkLuego, ejecute el comando pg_basebackup para obtener el directorio de datos principal actual y asigne el propietario correcto (postgres):
$ pg_basebackup -h 192.168.100.145 -D /var/lib/pgsql/11/data/ -P -U replication_user --wal-method=stream
$ chown -R postgres.postgres dataAhora, debe usar la siguiente configuración básica para crear una replicación asíncrona. El archivo que se modificará es postgresql.conf y debe crear un nuevo archivo recovery.conf. Ambos estarán ubicados en /var/lib/pgsql/11/.
Recuperación.conf
Especifique que este servidor será un servidor en espera. Si está activado, el servidor continuará recuperándose obteniendo nuevos segmentos WAL cuando se alcance el final del WAL archivado.
standby_mode = 'on'Especifique una cadena de conexión para que el servidor en espera se conecte al nodo principal.
primary_conninfo = 'host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'Especifique la recuperación en una línea de tiempo particular. El valor predeterminado es recuperar a lo largo de la misma línea de tiempo que estaba vigente cuando se realizó la copia de seguridad base. Establecer esto en "más reciente" recupera la última línea de tiempo encontrada en el archivo.
recovery_target_timeline = 'latest'Especifique un archivo desencadenante cuya presencia termine la recuperación en el modo de espera.
trigger_file = '/tmp/failover_5432.trigger'Postgresql.conf
Cambie o agregue los siguientes parámetros en el archivo de configuración postgresql.conf.
Determinar cuánta información se escribe en los WAL. Los valores posibles son mínimo, réplica o lógico. El valor hot_standby se asigna a réplica y se utiliza para mantener la compatibilidad con versiones anteriores. Cambiar este valor requiere reiniciar el servicio.
wal_level = hot_standbyPermitir las consultas durante la recuperación. Cambiar este valor requiere reiniciar el servicio.
hot_standby = onInicio del nodo en espera
Ahora que tiene toda la configuración requerida en su lugar, solo necesita iniciar el servicio de base de datos en el nodo en espera.
$ systemctl start postgresql-11Y verifique los registros de la base de datos en /var/lib/pgsql/11/data/log/. Deberías tener algo como esto:
2019-11-18 20:23:57.440 UTC [1131] LOG: entering standby mode
2019-11-18 20:23:57.447 UTC [1131] LOG: redo starts at 0/3000028
2019-11-18 20:23:57.449 UTC [1131] LOG: consistent recovery state reached at 0/30000F8
2019-11-18 20:23:57.449 UTC [1129] LOG: database system is ready to accept read only connections
2019-11-18 20:23:57.457 UTC [1135] LOG: started streaming WAL from primary at 0/4000000 on timeline 1También puede verificar el estado de replicación en el nodo principal ejecutando la siguiente consulta:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1467 | replication_user | walreceiver | streaming | async
(1 row)Como puede ver, estamos usando una replicación asíncrona.
Convertir la replicación asíncrona de PostgreSQL en replicación síncrona
Ahora, es el momento de convertir esta replicación asíncrona en una sincronizada y, para ello, deberá configurar tanto el nodo principal como el de reserva.
Nodo principal
En el nodo principal de PostgreSQL, debe usar esta configuración básica además de la configuración asíncrona anterior.
Postgresql.conf
Especifique una lista de servidores en espera que puedan admitir la replicación síncrona. Este nombre de servidor en espera es la configuración nombre_aplicación en el archivo recovery.conf en espera.
synchronous_standby_names = 'pgsql_0_node_0'synchronous_standby_names = 'pgsql_0_node_0'Especifica si la confirmación de la transacción esperará a que los registros WAL se escriban en el disco antes de que el comando devuelva una indicación de "éxito" al cliente. Los valores válidos son on, remote_apply, remote_write, local y off. El valor predeterminado es activado.
synchronous_commit = onConfiguración de nodo en espera
En el nodo de espera de PostgreSQL, debe cambiar el archivo recovery.conf agregando el valor 'application_name en el parámetro primary_conninfo.
Recuperación.conf
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_0_node_0 host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover_5432.trigger'Reinicie el servicio de la base de datos tanto en el nodo primario como en el standby:
$ service postgresql-11 restartAhora, debe tener su replicación de transmisión de sincronización en funcionamiento:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1561 | replication_user | pgsql_0_node_0 | streaming | sync
(1 row)Reversión de replicación sincrónica a asincrónica de PostgreSQL
Si necesita volver a la replicación asincrónica de PostgreSQL, solo necesita deshacer los cambios realizados en el archivo postgresql.conf en el nodo principal:
Postgresql.conf
#synchronous_standby_names = 'pgsql_0_node_0'
#synchronous_commit = onY reinicie el servicio de la base de datos.
$ service postgresql-11 restartAsí que ahora debería volver a tener replicación asincrónica.
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1625 | replication_user | pgsql_0_node_0 | streaming | async
(1 row)Cómo implementar una replicación síncrona de PostgreSQL mediante ClusterControl
Con ClusterControl puede realizar las tareas de implementación, configuración y monitoreo todo en uno desde el mismo trabajo y podrá administrarlo desde la misma interfaz de usuario.
Supondremos que tiene instalado ClusterControl y puede acceder a los nodos de la base de datos a través de SSH. Para obtener más información sobre cómo configurar el acceso a ClusterControl, consulte nuestra documentación oficial.
Vaya a ClusterControl y use la opción "Implementar" para crear un nuevo clúster de PostgreSQL.
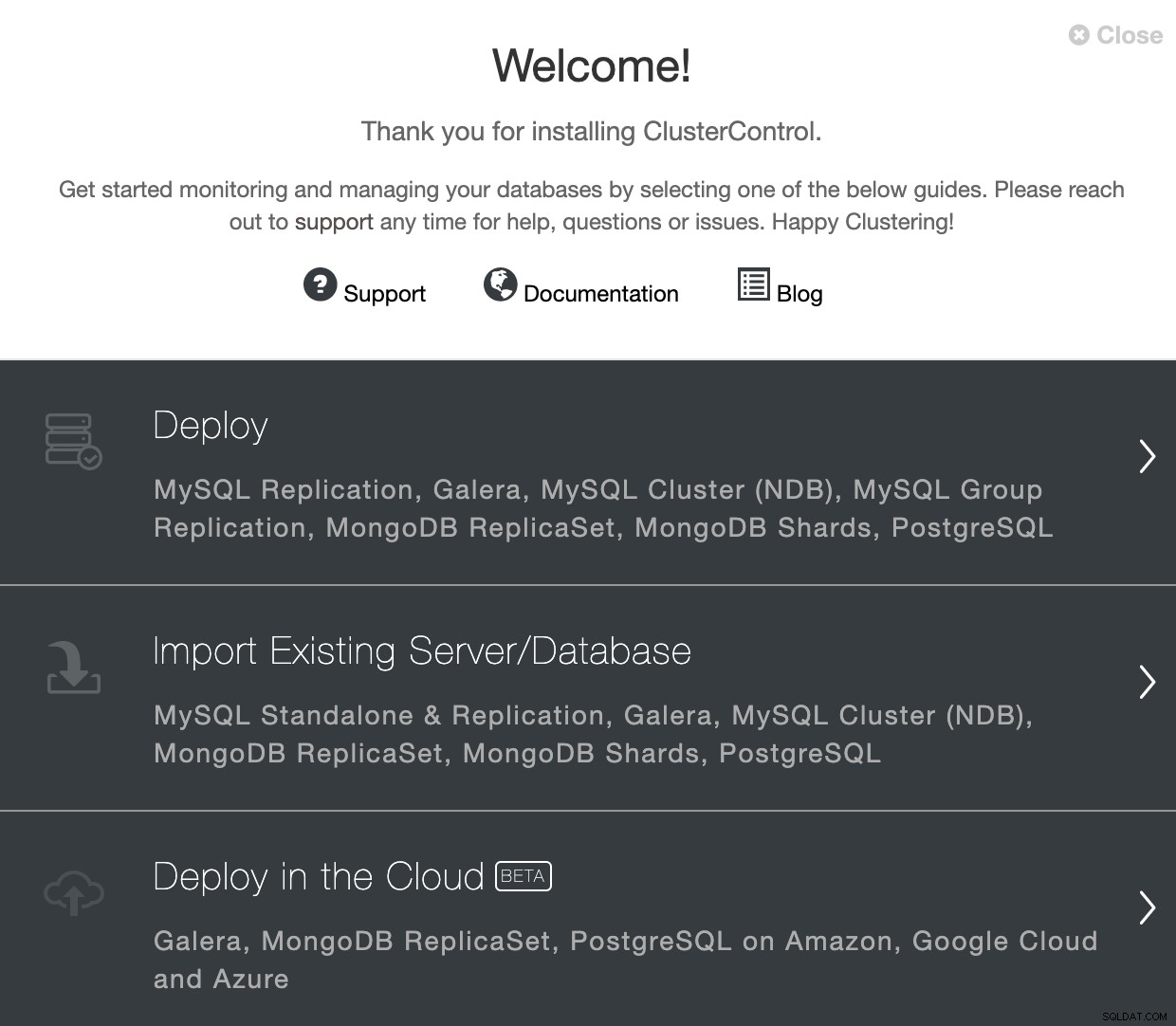
Al seleccionar PostgreSQL, debe especificar Usuario, Clave o Contraseña y un puerto para conectarse por SSH a nuestros servidores. También necesita un nombre para su nuevo clúster y si desea que ClusterControl instale el software y las configuraciones correspondientes por usted.
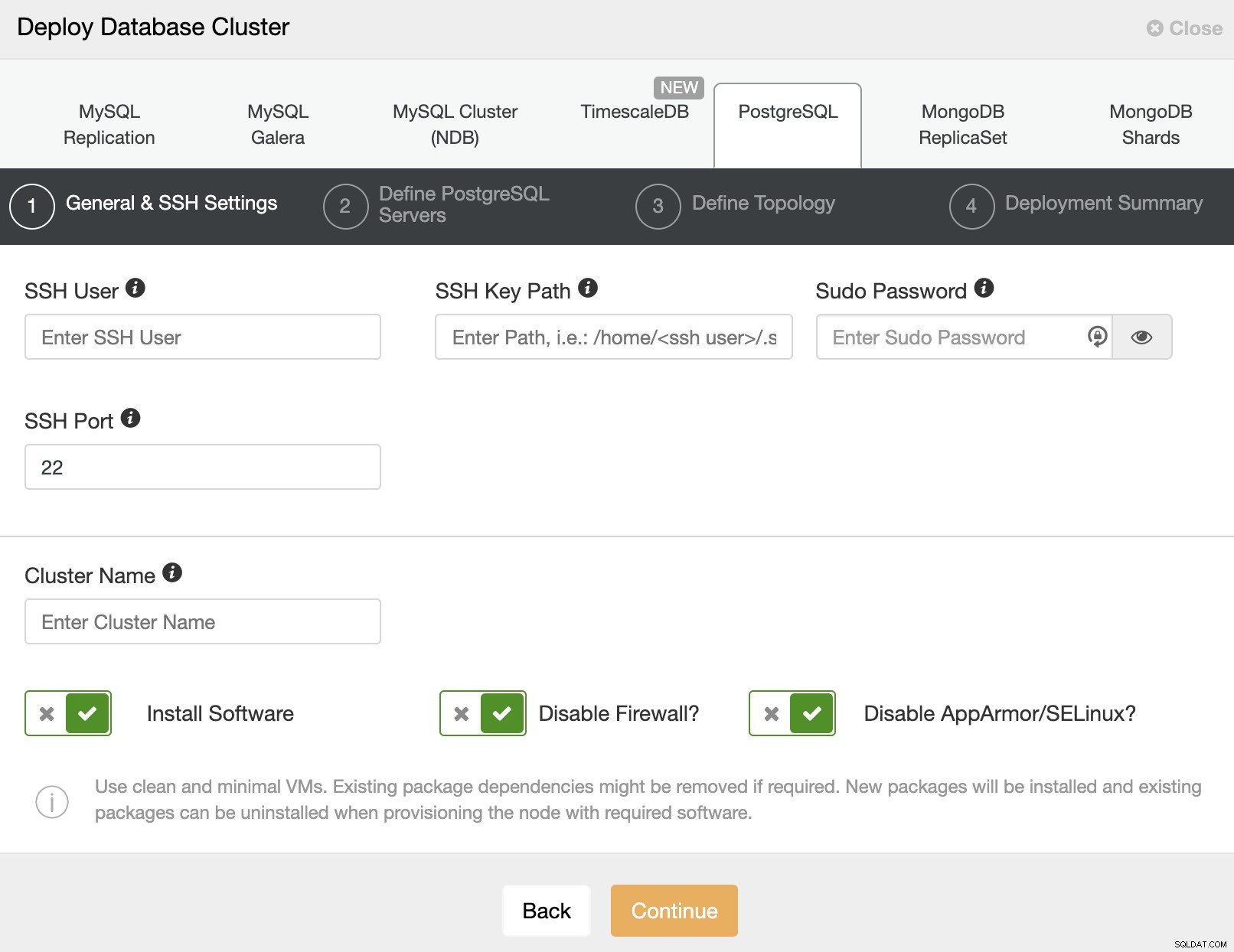
Después de configurar la información de acceso SSH, debe ingresar los datos para acceder tu base de datos También puede especificar qué repositorio usar.
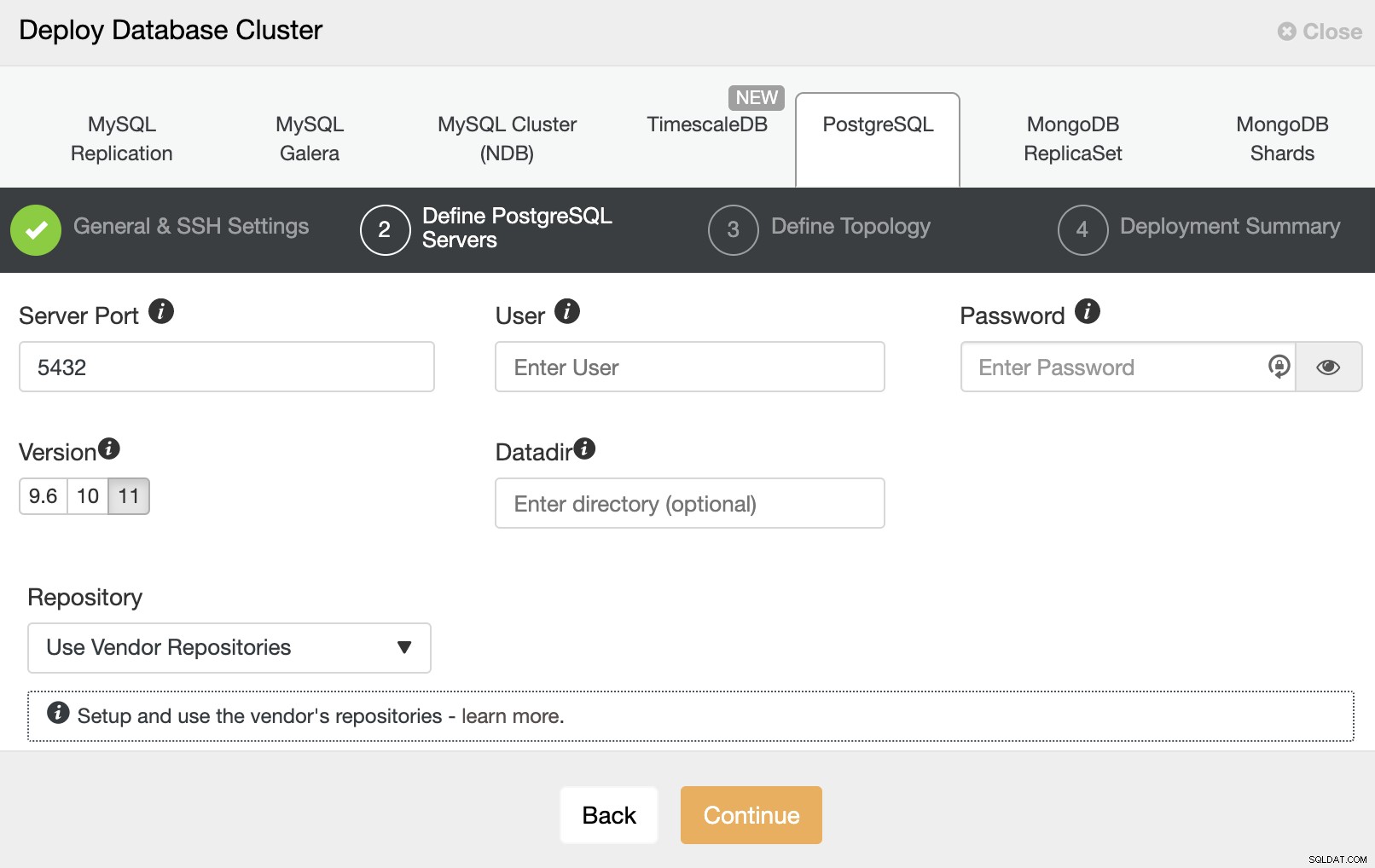
En el siguiente paso, debe agregar sus servidores al clúster que vas a crear. Al agregar sus servidores, puede ingresar la IP o el nombre de host.
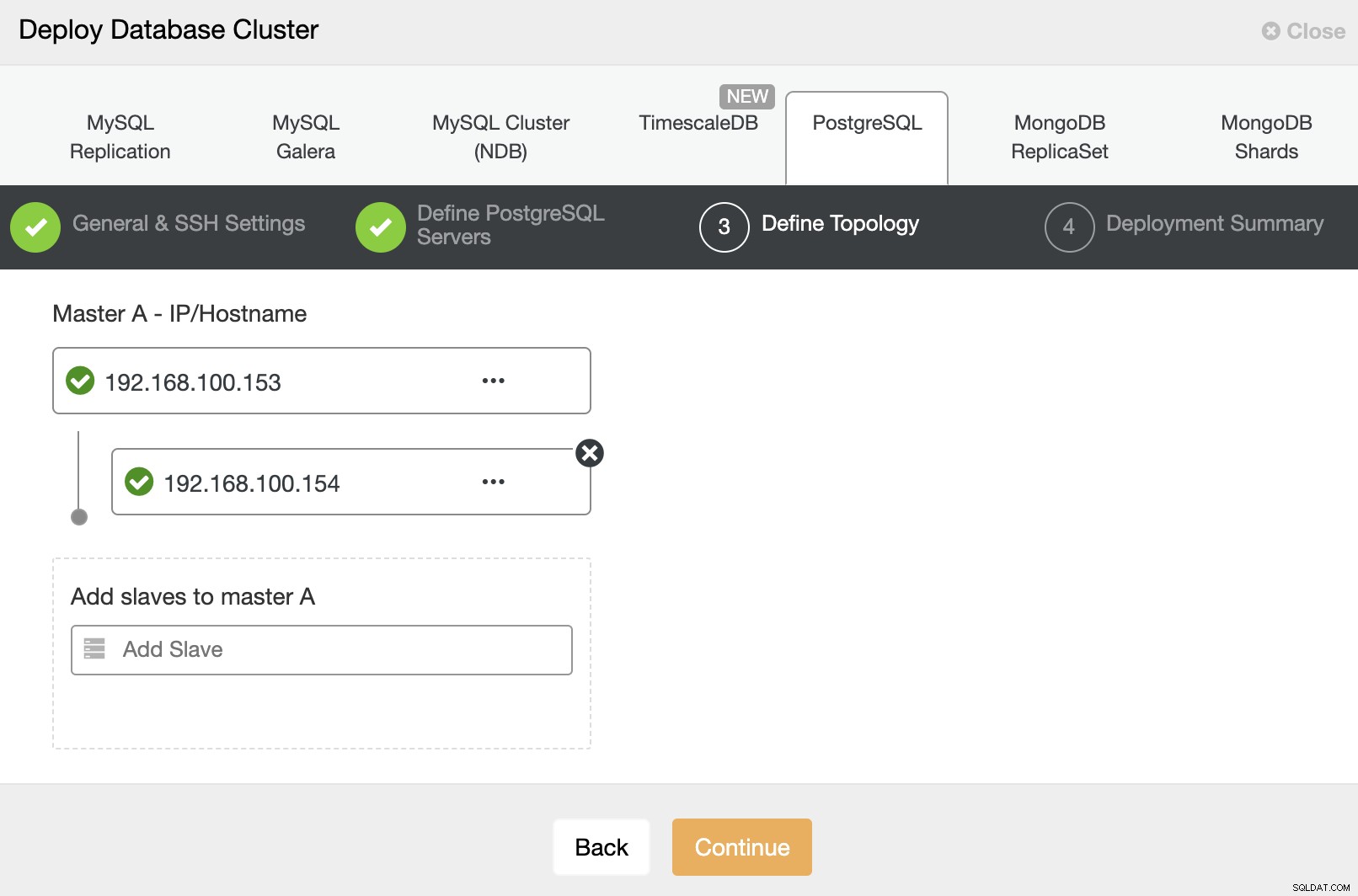
Y finalmente, en el último paso, puede elegir el método de replicación, que puede ser replicación asíncrona o síncrona.
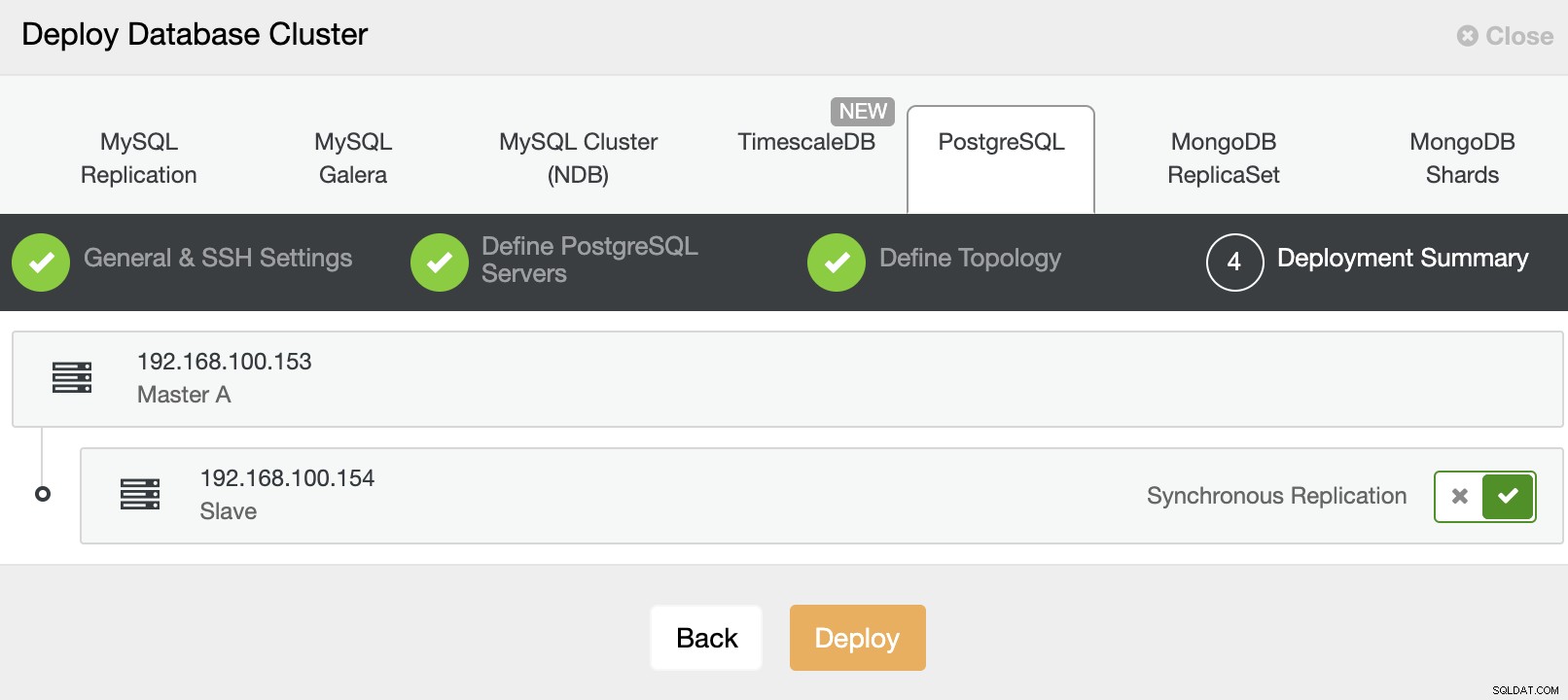
Eso es todo. Puede monitorear el estado del trabajo en la sección de actividad de ClusterControl.
Y cuando termine este trabajo, tendrá instalado su clúster síncrono de PostgreSQL, configurado y monitoreado por ClusterControl.
Conclusión
Como mencionamos al comienzo de este blog, la Alta Disponibilidad es un requisito para todas las empresas, por lo que debe conocer las opciones disponibles para lograrlo para cada tecnología en uso. Para PostgreSQL, puede usar la replicación de transmisión síncrona como la forma más segura de implementarla, pero este método no funciona para todos los entornos y cargas de trabajo.
Cuidado con la latencia que genera esperar la confirmación de cada transacción que podría ser un problema en lugar de una solución de Alta Disponibilidad.