En la primera parte de esta serie de blogs, presenté un par de resultados de referencia que muestran cómo cambió el rendimiento de OLTP de PostgreSQL desde 8.3, lanzado en 2008. En esta parte planeo hacer lo mismo pero para consultas analíticas/BI, procesando grandes cantidades de datos.
Hay una serie de puntos de referencia de la industria para probar esta carga de trabajo, pero probablemente el más utilizado es TPC-H, así que eso es lo que usaré para esta publicación de blog. También está TPC-DS, otro punto de referencia de TPC para probar los sistemas de soporte de decisiones, que puede verse como una evolución o reemplazo de TPC-H. Decidí quedarme con TPC-H por un par de razones.
En primer lugar, TPC-DS es mucho más complejo, tanto en términos de esquema (más tablas) como de número de consultas (22 frente a 99). Ajustar esto correctamente, particularmente cuando se trata de múltiples versiones de PostgreSQL, sería mucho más difícil. En segundo lugar, algunas de las consultas de TPC-DS utilizan funciones que no son compatibles con versiones anteriores de PostgreSQL (por ejemplo, conjuntos de agrupación), lo que hace que esas consultas sean irrelevantes para algunas versiones. Y finalmente, diría que la gente está mucho más familiarizada con TPC-H en comparación con TPC-DS.
El objetivo de esto no es permitir la comparación con otros productos de base de datos, solo proporcionar una caracterización razonable a largo plazo sobre cómo evolucionó el rendimiento de PostgreSQL desde PostgreSQL 8.3.
Nota :Para un análisis muy interesante del punto de referencia TPC-H, recomiendo encarecidamente el artículo "TPC-H Analyzed:Hidden Messages and Lessons Learned from an Influential Benchmark" de Boncz, Neumann y Erling.
El hardware
La mayoría de los resultados de esta publicación de blog provienen de la "caja más grande" que tengo en nuestra oficina, que tiene estos parámetros:
- 2x E5-2620 v4 (16 núcleos, 32 subprocesos)
- 64 GB de RAM
- SSD Intel Optane 900P de 280 GB NVMe (datos)
- 3 x 7.2k SATA RAID0 (tablespace temporal)
- núcleo 5.6.15, sistema de archivos ext4
Estoy seguro de que puede comprar máquinas significativamente más robustas, pero creo que esto es lo suficientemente bueno como para brindarnos datos relevantes. Había dos variantes de configuración:una con el paralelismo deshabilitado y otra con el paralelismo habilitado. La mayoría de los valores de los parámetros son los mismos en ambos casos, ajustados a los recursos de hardware disponibles (CPU, RAM, almacenamiento). Puede encontrar una información más detallada sobre la configuración al final de esta publicación.
El punto de referencia
Quiero dejar muy claro que no es mi objetivo implementar un punto de referencia TPC-H válido que pueda pasar todos los criterios requeridos por el TPC. Mi objetivo es evaluar cómo cambió el rendimiento de diferentes consultas analíticas con el tiempo, no perseguir una medida abstracta de rendimiento por dólar o algo así.
Así que decidí usar solo un subconjunto de TPC-H; esencialmente solo cargue los datos y ejecute las 22 consultas (los mismos parámetros en todas las versiones). No hay actualizaciones de datos, el conjunto de datos es estático después de la carga inicial. Elegí una serie de factores de escala, 1, 10 y 75, para que tengamos resultados para ajustes en búferes compartidos (1), ajustes en memoria (10) y más que memoria (75) . Iría por 100 para convertirlo en una "buena secuencia", que no encajaría en el almacenamiento de 280 GB en algunos casos (gracias a índices, archivos temporales, etc.). Tenga en cuenta que el factor de escala 75 ni siquiera es reconocido por TPC-H como un factor de escala válido.
Pero, ¿tiene sentido comparar conjuntos de datos de 1 GB o 10 GB? La gente tiende a centrarse en bases de datos mucho más grandes, por lo que puede parecer un poco tonto molestarse en probarlas. Pero no creo que eso sea útil:la gran mayoría de las bases de datos son bastante pequeñas, según mi experiencia. E incluso cuando toda la base de datos es grande, las personas generalmente solo trabajan con un pequeño subconjunto:datos recientes, pedidos no resueltos, etc. Así que creo que tiene sentido probar incluso con esos pequeños conjuntos de datos.
Cargas de datos
Primero, veamos cuánto se tarda en cargar datos en la base de datos, sin y con paralelismo. Solo mostraré los resultados del conjunto de datos de 75 GB, porque el comportamiento general es casi el mismo para los casos más pequeños.
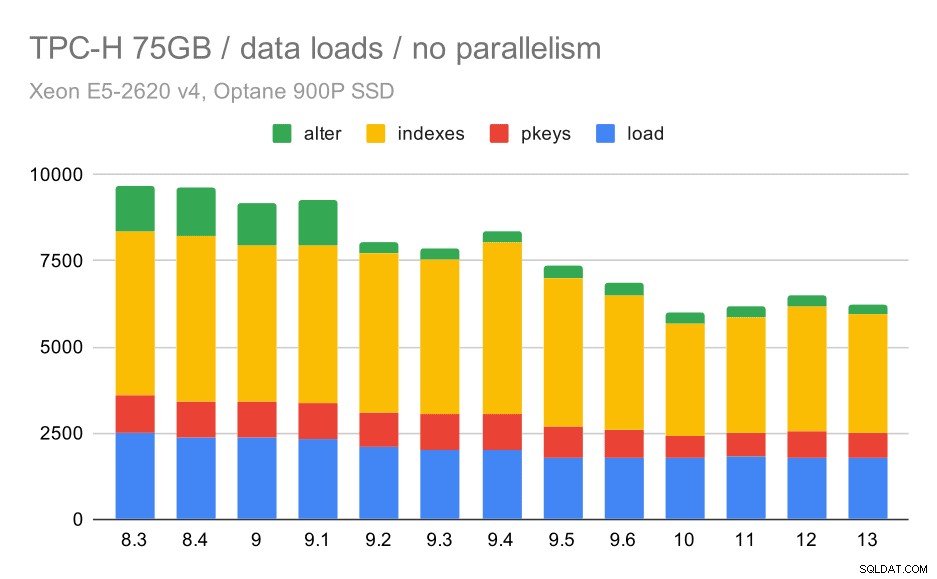
Duración de la carga de datos TPC-H:escala 75 GB, sin paralelismo
Puede ver claramente que hay una tendencia constante de mejoras, reduciendo aproximadamente el 30 % de la duración simplemente mejorando la eficiencia en los cuatro pasos:COPIAR, crear claves primarias e índices y (especialmente) configurar claves externas. La mejora "alterar" en 9.2 es particularmente clara.
| COPIAR | PKEYS | ÍNDICE | ALTER | |
| 8.3 | 2531 | 1156 | 1922 | 1615 |
| 8.4 | 2374 | 1171 | 1891 | 1370 |
| 9.0 | 2374 | 1137 | 1797 | 1282 |
| 9.1 | 2376 | 1118 | 1807 | 1268 |
| 9.2 | 2104 | 1120 | 1833 | 1157 |
| 9.3 | 2008 | 1089 | 1836 | 1229 |
| 9.4 | 1990 | 1168 | 1818 | 1197 |
| 9.5 | 1982 | 1000 | 1903 | 1203 |
| 9.6 | 1779 | 872 | 1797 | 1174 |
| 10 | 1773 | 777 | 1469 | 1012 |
| 11 | 1807 | 762 | 1492 | 758 |
| 12 | 1760 | 768 | 1513 | 741 |
| 13 | 1782 | 836 | 1587 | 675 |
Ahora, veamos cómo habilitar el paralelismo cambia el comportamiento. El siguiente cuadro compara los resultados con el paralelismo habilitado, marcado con "(p)", con los resultados con el paralelismo deshabilitado.
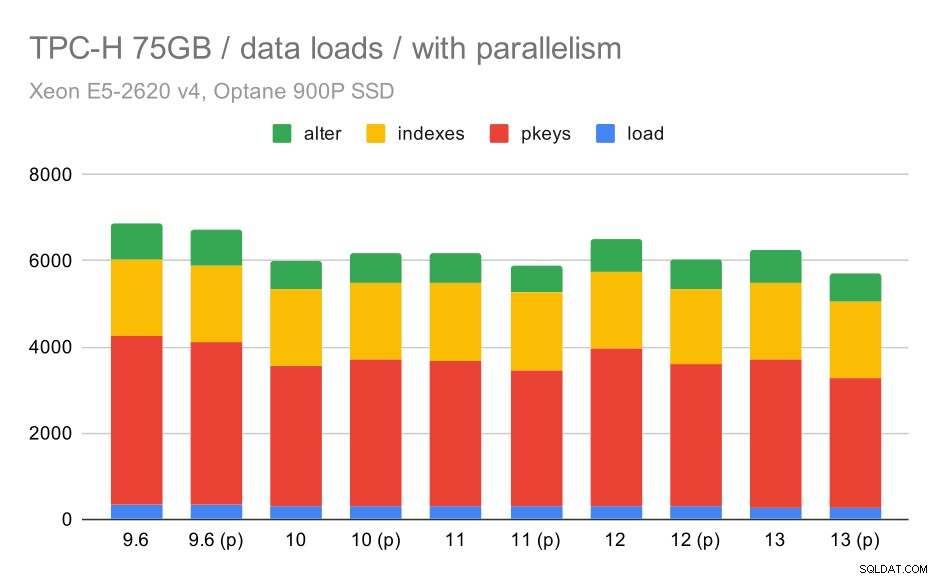
Duración de la carga de datos TPC-H:escala 75 GB, paralelismo habilitado.
Desafortunadamente, parece que el efecto del paralelismo es muy limitado en esta prueba; ayuda un poco, pero las diferencias son bastante pequeñas. Por lo tanto, la mejora general sigue siendo de alrededor del 30 %.
| COPIAR | PKEYS | ÍNDICE | ALTER | |
| 9.6 | 344 | 3902 | 1786 | 831 |
| 9.6 (p) | 346 | 3781 | 1780 | 832 |
| 10 | 318 | 3259 | 1766 | 671 |
| 10 (p) | 315 | 3400 | 1769 | 693 |
| 11 | 319 | 3357 | 1817 | 690 |
| 11 (p) | 320 | 3144 | 1791 | 618 |
| 12 | 314 | 3643 | 1803 | 754 |
| 12 (p) | 313 | 3296 | 1752 | 657 |
| 13 | 276 | 3437 | 1790 | 744 |
| 13 (P) | 274 | 3011 | 1770 | 641 |
Consultas
Ahora podemos echar un vistazo a las consultas. TPC-H tiene 22 plantillas de consulta:generé un conjunto de consultas reales y las ejecuté en todas las versiones dos veces, primero después de eliminar todos los cachés y reiniciar la instancia, luego con el caché calentado. Todos los números presentados en los gráficos son los mejores de estas dos carreras (en la mayoría de los casos es la segunda, por supuesto).
Sin paralelismo
Sin paralelismo, los resultados en el conjunto de datos más pequeño son bastante claros:cada barra se divide en varias partes con diferentes colores para cada una de las 22 consultas. Es difícil decir qué parte corresponde a qué consulta exacta, pero es suficiente para identificar casos en los que una consulta mejora o empeora mucho entre dos ejecuciones. Por ejemplo, en el primer gráfico, está muy claro que Q21 fue mucho más rápido entre 8,3 y 8,4.
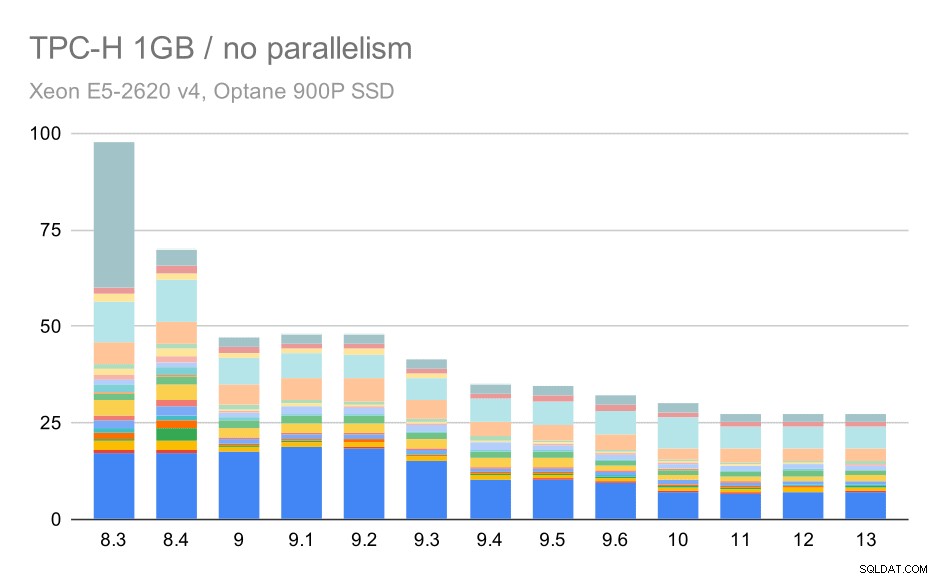
Consultas TPC-H en conjuntos de datos pequeños (1 GB):paralelismo deshabilitado
Para la escala de 10 GB, los resultados son algo difíciles de interpretar, porque en 8.3 una de las consultas (Q21) tarda tanto en ejecutarse que empequeñece todo lo demás.
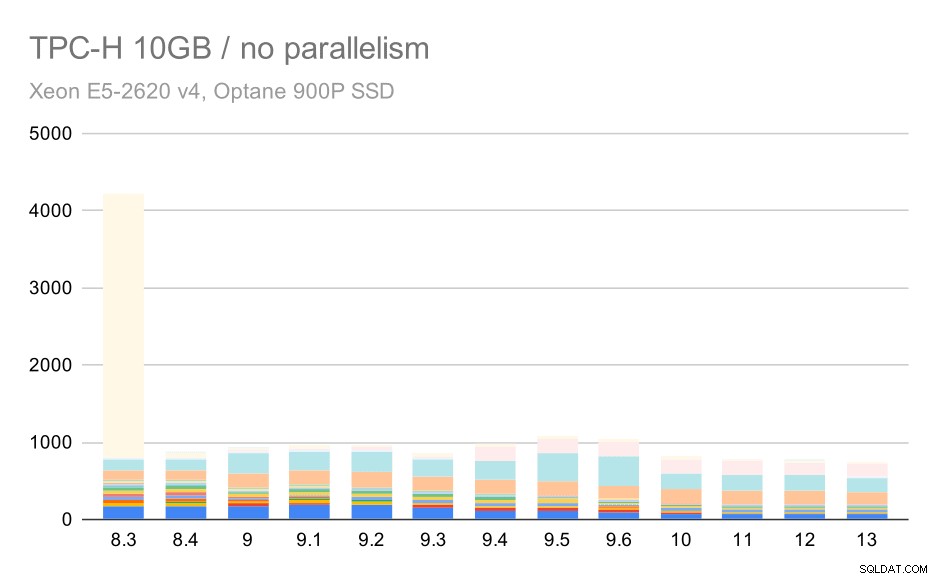
Consultas TPC-H en un conjunto de datos mediano (10 GB):paralelismo deshabilitado
Entonces, veamos cómo se vería el gráfico sin Q21:
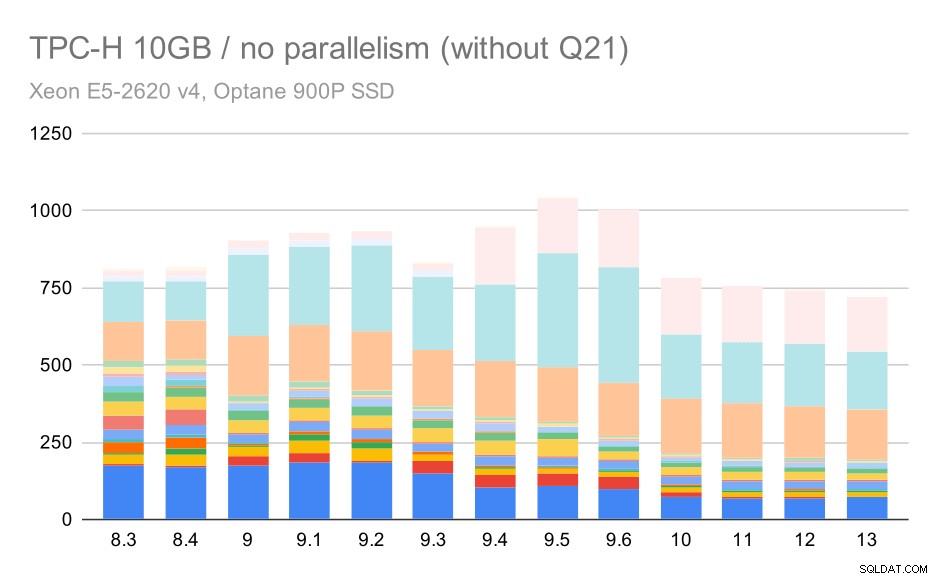
Consultas TPC-H en conjunto de datos mediano (10 GB):paralelismo deshabilitado, sin Q2 problemático
OK, eso es más fácil de leer. Podemos ver claramente que la mayoría de las consultas (hasta Q17) se hicieron más rápidas, pero luego dos de las consultas (Q18 y Q20) se hicieron algo más lentas. Veremos un problema similar en el conjunto de datos más grande, por lo que analizaré cuál podría ser la causa principal en ese momento.
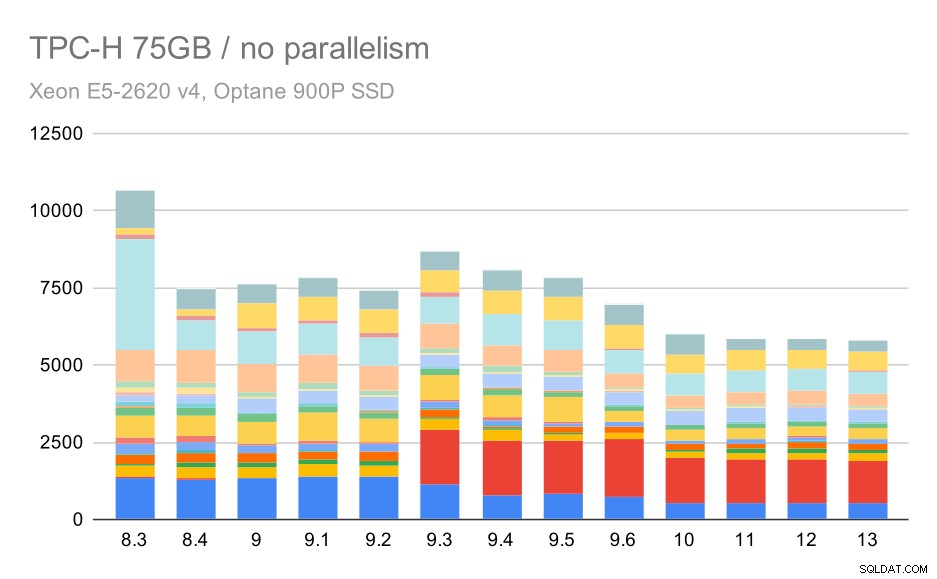
Consultas TPC-H en conjuntos de datos grandes (75 GB):paralelismo deshabilitado
Nuevamente, vemos un aumento repentino para una de las consultas en 9.3; esta vez es el segundo trimestre, sin el cual el gráfico se ve así:
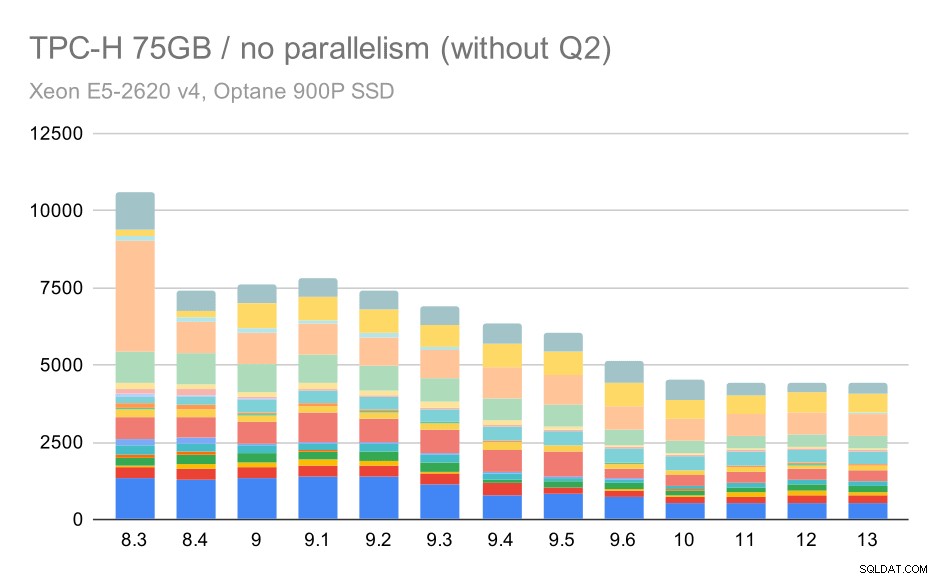
Consultas TPC-H en conjuntos de datos grandes (75 GB):paralelismo deshabilitado, sin Q2 problemático
Esa es una mejora bastante agradable en general, acelerando toda la ejecución de ~2.7 horas a solo ~1.2h, simplemente haciendo que el planificador y el optimizador sean más inteligentes, y haciendo que el ejecutor sea más eficiente (recuerde, el paralelismo se deshabilitó en estas ejecuciones) .
Entonces, ¿cuál podría ser el problema con Q2, haciéndolo más lento en 9.3? La respuesta simple es que cada vez que hace que el planificador y el optimizador sean más inteligentes, ya sea construyendo nuevos tipos de rutas/planes, o haciéndolo depender de algunas estadísticas, también significa que se pueden cometer nuevos errores cuando las estadísticas o estimaciones son incorrectas. En el segundo trimestre, la cláusula WHERE hace referencia a una subconsulta agregada; una versión simplificada de la consulta podría verse así:
Seleccione 1 FROM PartSuppwhere PS_SUPPLYCOST =(Seleccione min (ps_supplycost) de partesupp, proveedor, nation, región donde p_partkey =ps_partkey y s_suppkey =ps_suppkey y s_nationkey =n_nationkey y n_regionkey =r_regionkey y r_name ='america';El problema es que no conocemos el valor promedio en el momento de la planificación, lo que hace imposible calcular estimaciones lo suficientemente buenas para la condición DÓNDE. El Q2 real contiene uniones adicionales, y su planificación depende fundamentalmente de buenas estimaciones de las relaciones unidas. En versiones anteriores, el optimizador parece haber estado haciendo lo correcto, pero luego en 9.3 lo hicimos más inteligente de alguna manera, pero con la mala estimación no logra tomar la decisión correcta. En otras palabras, los buenos planes en versiones anteriores fueron solo suerte, gracias a las limitaciones del planificador.
Apuesto a que las regresiones de Q18 y Q20 en el conjunto de datos más pequeño también son causadas por algo similar, aunque no las he investigado en detalle.
Creo que algunos de esos problemas del optimizador podrían solucionarse ajustando los parámetros de costo (por ejemplo, costo_página_aleatorio, etc.), pero no lo he intentado debido a limitaciones de tiempo. Sin embargo, muestra que las actualizaciones no mejoran automáticamente todas las consultas; a veces, una actualización puede desencadenar una regresión, por lo que es una buena idea realizar una prueba adecuada de su aplicación.
Paralelismo
Entonces, veamos cuánto cambia el paralelismo de consultas en los resultados. Nuevamente, solo veremos los resultados de las versiones posteriores a la 9.6 etiquetando los resultados con "(p)" donde la consulta en paralelo está habilitada.
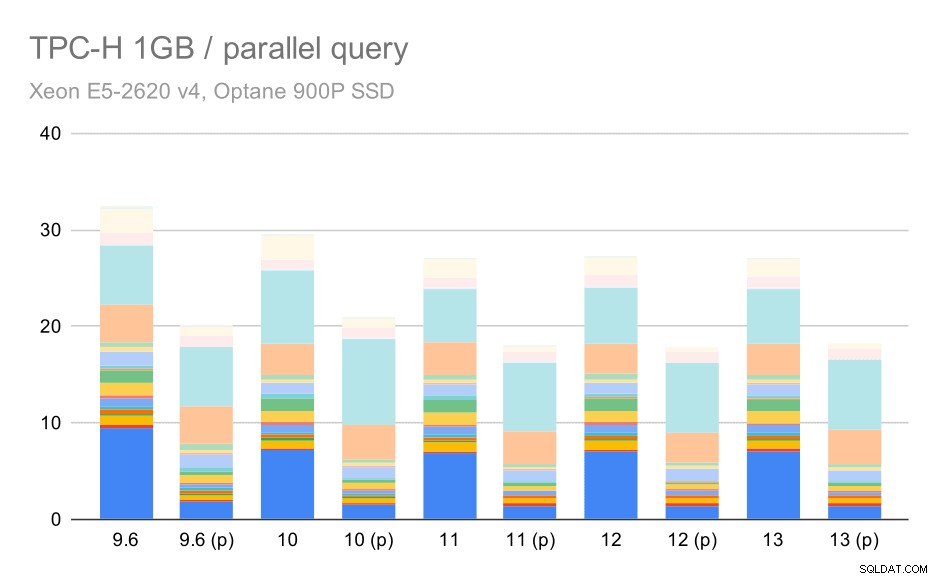
Consultas TPC-H en conjuntos de datos pequeños (1 GB):paralelismo habilitado
Claramente, el paralelismo ayuda bastante:elimina alrededor del 30% incluso en este pequeño conjunto de datos. En el conjunto de datos mediano, no hay mucha diferencia entre ejecuciones regulares y paralelas:
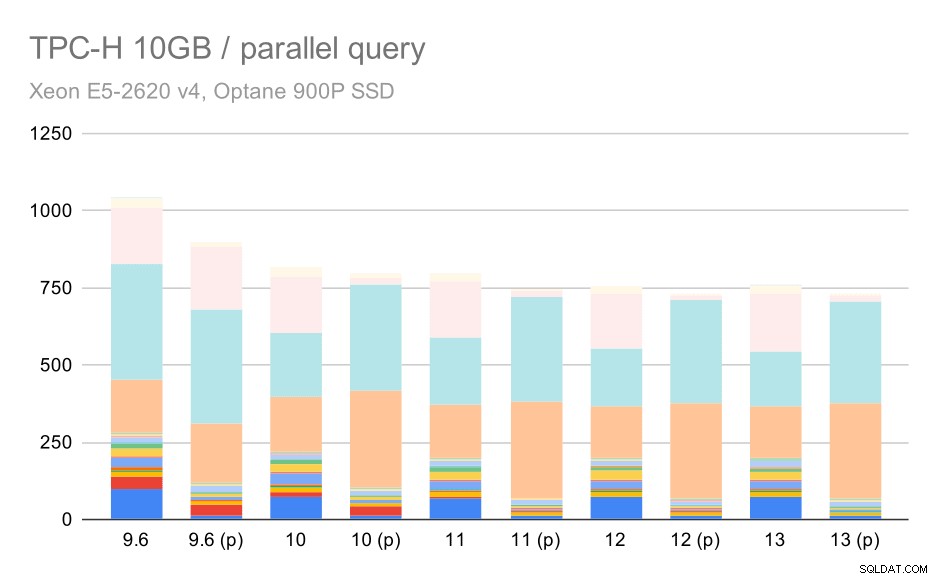
Consultas TPC-H en un conjunto de datos mediano (10 GB):paralelismo habilitado
Esta es otra demostración del problema ya discutido:habilitar el paralelismo permite considerar planes de consulta adicionales y, claramente, las estimaciones o los costos no coinciden con la realidad, lo que da como resultado opciones de planes deficientes.
Y finalmente el gran conjunto de datos, donde los resultados completos se ven así:
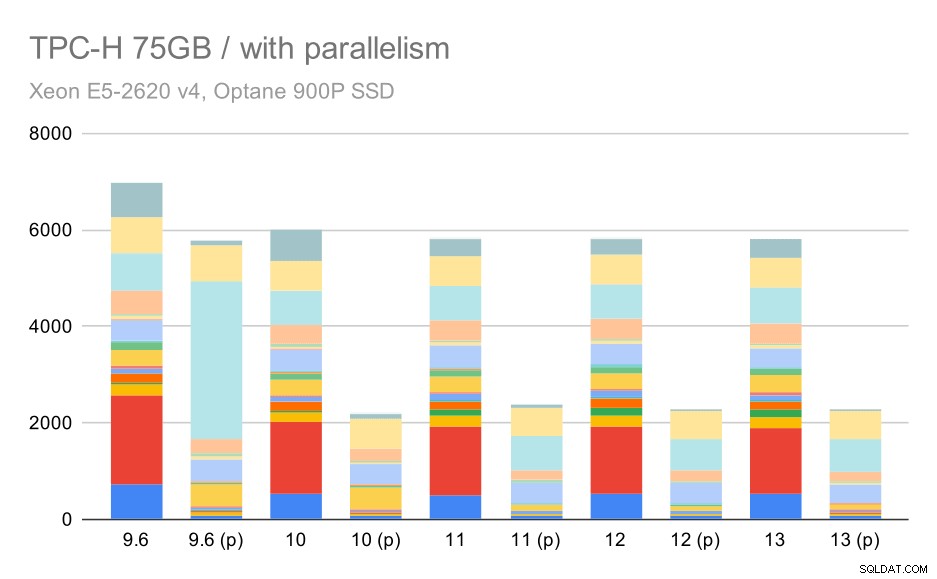
Consultas TPC-H en grandes conjuntos de datos (75 GB):paralelismo habilitado
Aquí, habilitar el paralelismo funciona a nuestro favor:el optimizador logra crear un plan paralelo más económico para el segundo trimestre, anulando la mala elección del plan introducida en 9.3. Pero solo para completar, estos son los resultados sin el segundo trimestre.
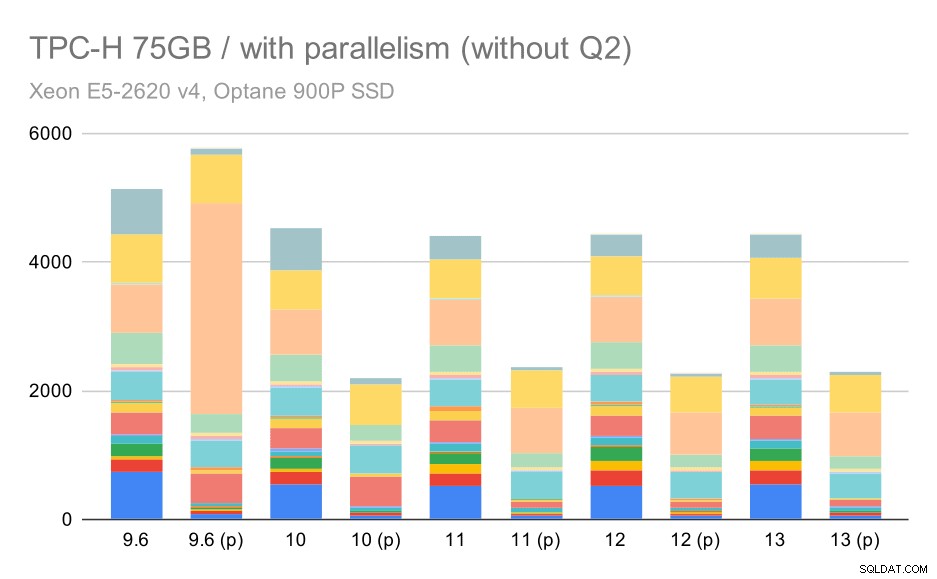
Consultas TPC-H en grandes conjuntos de datos (75 GB):paralelismo habilitado, sin Q2 problemático
Incluso aquí puede detectar algunas opciones de planes paralelos deficientes; por ejemplo, el plan paralelo para Q9 es peor hasta el 11, donde se vuelve más rápido, probablemente gracias a que 11 admite nodos ejecutores paralelos adicionales. Por otro lado, algunas consultas paralelas (Q18, Q20) se vuelven más lentas en 11, por lo que no se trata solo de arcoíris y unicornios.
Resumen y Futuro
Creo que estos resultados demuestran muy bien las optimizaciones implementadas desde PostgreSQL 8.3. Las pruebas con el paralelismo deshabilitado ilustran las mejoras en la eficiencia (es decir, hacer más con la misma cantidad de recursos):las cargas de datos se hicieron un 30 % más rápidas y las consultas se hicieron aproximadamente el doble de rápidas. Es cierto que me he encontrado con algunos problemas con los planes de consultas ineficientes, pero ese es un riesgo inherente al hacer que el planificador de consultas sea más inteligente. Trabajamos continuamente para que los resultados sean más confiables y estoy seguro de que podría mitigar la mayoría de estos problemas ajustando un poco la configuración.
Los resultados con el paralelismo habilitado muestran que podemos utilizar recursos adicionales de manera efectiva (núcleos de CPU en particular). Las cargas de datos no parecen beneficiarse mucho de esto, al menos no en este punto de referencia, pero el impacto en la ejecución de consultas es significativo, lo que resulta en una aceleración ~2x (aunque las diferentes consultas se ven afectadas de manera diferente, por supuesto).
Hay muchas oportunidades para mejorar esto en futuras versiones de PostgreSQL. Por ejemplo, hay una serie de parches que implementan el paralelismo para COPY, lo que acelera las cargas de datos. Hay varios parches que mejoran la ejecución de consultas analíticas, desde pequeñas optimizaciones localizadas hasta grandes proyectos como almacenamiento y ejecución en columnas, push-down agregado, etc. Se puede ganar mucho usando también el particionamiento declarativo, una característica que en su mayoría ignoré mientras trabajaba en esto. punto de referencia, simplemente porque aumentaría demasiado el alcance. Y estoy seguro de que hay muchas otras oportunidades que ni siquiera puedo imaginar, pero las personas más inteligentes de la comunidad de PostgreSQL ya están trabajando en ellas.
Apéndice:Configuración de PostgreSQL
Paralelismo deshabilitado
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =0max_parallel_maintenance_workers =0# Optimizerdefault_statistics_target =1000random_page_cost =60effect_cache_size =32GB
Paralelismo habilitado
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =16max_parallel_maintenance_workers =16max_worker_processes =32max_parallel_workers =32# Optimizerdefault_statistics_target =1000random_page_cost =60effect_cache_size =32GB