Los puntos de control pueden ser un lastre importante en las instalaciones de PostgreSQL con muchas operaciones de escritura. El primer paso para identificar problemas en esta área es monitorear la frecuencia con la que suceden, lo que acaba de agregar a la base de datos una interfaz más fácil de usar.
Los puntos de control son operaciones de mantenimiento periódicas que realiza la base de datos para asegurarse de que todo lo que ha estado almacenando en caché en la memoria se haya sincronizado con el disco. La idea es que una vez que haya terminado uno, puede eliminar la necesidad de preocuparse por las entradas más antiguas colocadas en el registro de escritura anticipada de la base de datos. Eso significa menos tiempo para recuperarse después de un bloqueo.
El problema con los puntos de control es que pueden ser muy intensivos, porque para completar uno se requiere escribir cada bit de datos modificados en el caché del búfer de la base de datos en el disco. Se agregaron una serie de características a PostgreSQL 8.3 que le permiten monitorear mejor la sobrecarga del punto de control y reducirla al distribuir la actividad durante un período de tiempo más largo. Escribí un artículo largo sobre esos cambios llamado Puntos de control y el Escritor de fondo que repasa lo que cambió, pero es una lectura bastante seca.
Lo que probablemente quiera saber es cómo monitorear los puntos de control en su sistema de producción y cómo saber si están sucediendo con demasiada frecuencia. A pesar de que las cosas han mejorado, los "picos de puntos de control" donde la E/S del disco se vuelve realmente pesada aún son posibles incluso en las versiones actuales de PostgreSQL. Y no ayuda que la configuración predeterminada esté ajustada para un espacio en disco muy bajo y una recuperación rápida de fallas en lugar de rendimiento. El parámetro checkpoint_segments que es una entrada sobre la frecuencia con la que ocurre un punto de control tiene un valor predeterminado de 3, lo que fuerza un punto de control después de solo 48 MB de escrituras.
Puede averiguar la frecuencia del punto de control de dos maneras. Puede activar log_checkpoints y ver qué sucede en los registros. También puede usar la vista pg_stat_bgwriter, que brinda un recuento de cada una de las dos fuentes para los puntos de control (tiempo que pasa y escrituras que ocurren), así como estadísticas sobre cuánto trabajo hicieron.
El principal problema de hacer eso más fácil hacer es que, hasta hace poco, ha sido imposible restablecer los contadores dentro de pg_stat_bgwriter. Eso significa que debe tomar una instantánea con una marca de tiempo, esperar un momento, tomar otra instantánea y luego restar todos los valores para obtener estadísticas útiles de los datos. Eso es un dolor.
Suficiente dolor que escribí un parche para hacerlo más fácil. Con la versión de desarrollo actual de la base de datos, ahora puede llamar a pg_stat_reset_shared('bgwriter') y devolver todos estos valores a 0 nuevamente. Esto permite seguir una práctica que solía ser común en PostgreSQL. Antes de 8.3, había un parámetro llamado stats_reset_on_server_start que podía activar. Eso restablece todas las estadísticas internas del servidor cada vez que lo inicia. Eso significaba que podía llamar a la práctica función pg_postmaster_start_time(), compararla con la hora actual y tener siempre un recuento preciso en términos de operaciones/segundo de cualquier estadística disponible en el sistema.
Todavía no es automático, pero ahora que restablecer estas piezas compartidas es posible, puede hacerlo usted mismo. La primera clave es integrar el borrado de estadísticas en la secuencia de inicio de su servidor. Un script como este funcionará:
pg_ctl start -l $PGLOG -w
psql -c "select pg_stat_reset();"
psql -c "select pg_stat_reset_shared('bgwriter');"
Tenga en cuenta el "-w" en el comando de inicio allí, que hará que pg_ctl espere hasta que el servidor termine de iniciarse antes de regresar, lo cual es vital si desea ejecutar inmediatamente una declaración en su contra.
Si lo ha hecho eso, y la hora de inicio de su servidor es esencialmente la misma que cuando las estadísticas del escritor en segundo plano comenzaron a recopilarse, ahora puede usar esta consulta divertida:
SELECT
total_checkpoints,
seconds_since_start / total_checkpoints / 60 AS minutes_between_checkpoints
FROM
(SELECT
EXTRACT(EPOCH FROM (now() - pg_postmaster_start_time())) AS seconds_since_start,
(checkpoints_timed+checkpoints_req) AS total_checkpoints
FROM pg_stat_bgwriter
) AS sub;
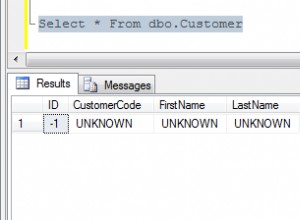
Y obtenga un informe simple de exactamente con qué frecuencia ocurren puntos de control en su sistema. La salida se ve así:
total_checkpoints | 9
minutes_between_checkpoints | 3.82999310740741
Lo que haces con esta información es mirar fijamente el intervalo de tiempo promedio y ver si parece demasiado rápido. Normalmente, le gustaría que un punto de control suceda no más de cada cinco minutos, y en un sistema ocupado, es posible que deba presionarlo a diez minutos o más para tener la esperanza de mantenerse al día. Con este ejemplo, cada 3,8 minutos es probablemente demasiado rápido; este es un sistema que necesita que los segmentos de puntos de control sean más altos.
El uso de esta técnica para medir el intervalo de los puntos de control le permite saber si necesita aumentar los segmentos de puntos de control y los parámetros de tiempo de espera de los puntos de control en orden. para lograr ese objetivo. Puede calcular los números manualmente en este momento, y una vez que se publique 9.0, es algo que puede considerar hacer completamente automático, siempre y cuando no le importe que sus estadísticas desaparezcan cada vez que se reinicia el servidor.
Hay otras formas interesantes para analizar los datos que el escritor de fondo le proporciona en pg_stat_bgwriter, pero no voy a revelar todos mis trucos hoy.