Empecé a escribir sobre la herramienta (pglupgrade) que desarrollé para realizar actualizaciones automatizadas con tiempo de inactividad casi nulo de los clústeres de PostgreSQL. En esta publicación, hablaré sobre la herramienta y analizaré los detalles de su diseño.
Puede consultar la primera parte de la serie aquí: Actualizaciones automatizadas con tiempo de inactividad casi nulo de los clústeres de PostgreSQL en la nube (Parte I).

La herramienta está escrita en Ansible. Tengo experiencia previa de trabajo con Ansible y actualmente también trabajo con él en 2ndQuadrant , por lo que fue una opción cómoda para mí. Dicho esto, puede implementar la lógica de actualización de tiempo de inactividad mínimo, que se explicará más adelante en esta publicación, con su herramienta de automatización favorita.
Lectura adicional:Publicaciones de blog Ansible Loves PostgreSQL , PostgreSQL Planet in Ansible Galaxy y presentación Gestión de PostgreSQL con Ansible.
Guía de actualización de Pgl
En Ansible, libros de estrategias son los scripts principales que se desarrollan para automatizar los procesos, como el aprovisionamiento de instancias en la nube y la actualización de clústeres de bases de datos. Los libros de jugadas pueden contener una o más jugadas . Los libros de jugadas también pueden contener variables , roles y controladores si está definido.
La herramienta consta de dos playbooks principales. El primer libro de jugadas es provision.yml que automatiza el proceso de creación de máquinas Linux en la nube, de acuerdo con las especificaciones (Este es un libro de jugadas opcional escrito solo para aprovisionar instancias en la nube y no está directamente relacionado con la actualización ). El segundo (y el principal) libro de jugadas es pglupgrade.yml que automatiza el proceso de actualización de los clústeres de bases de datos.
El libro de jugadas de Pglupgrade tiene ocho jugadas para orquestar la actualización. Cada una de las jugadas, usa un archivo de configuración (config.yml ), realizar algunas tareas en los hosts o grupos de hosts que se definen en el archivo de inventario del host (host.ini ).
Archivo de inventario
Un archivo de inventario le permite a Ansible saber qué servidores necesita conectarse mediante SSH, qué información de conexión requiere y, opcionalmente, qué variables están asociadas con esos servidores. A continuación, puede ver un archivo de inventario de muestra, que se ha utilizado para ejecutar actualizaciones de clúster automatizadas para uno de los estudios de caso diseñados para la herramienta. Discutiremos estos estudios de casos en próximas publicaciones de esta serie.
[old-primary] 54.171.211.188 [new-primary] 54.246.183.100 [old-standbys] 54.77.249.81 54.154.49.180 [new-standbys:children] old-standbys [pgbouncer] 54.154.49.180
Archivo de inventario (host.ini )
El archivo de inventario de muestra contiene cinco hosts menos de cinco grupos de acogida que incluyen old-primary , new-primary , old-standbys , new-standbys y pgbouncer . Un servidor podría pertenecer a más de un grupo. Por ejemplo, los old-standbys es un grupo que contiene los new-standbys grupo, lo que significa los hosts que están definidos bajo el old-standbys grupo (54.77.249.81 y 54.154.49.180) también pertenece al new-standbys grupo. En otras palabras, los new-standbys el grupo se hereda de (hijos de) old-standbys grupo. Esto se logra usando el :children especial sufijo.
Una vez que el archivo de inventario está listo, el libro de jugadas de Ansible se puede ejecutar a través de ansible-playbook comando señalando el archivo de inventario (si el archivo de inventario no se encuentra en la ubicación predeterminada, de lo contrario utilizará el archivo de inventario predeterminado) como se muestra a continuación:
$ ansible-playbook -i hosts.ini pglupgrade.yml
Ejecución de un libro de jugadas de Ansible
Archivo de configuración
El libro de jugadas de Pglupgrade utiliza un archivo de configuración (config.yml ) que permite a los usuarios especificar valores para las variables de actualización lógica.
Como se muestra a continuación, el config.yml almacena principalmente variables específicas de PostgreSQL que se requieren para configurar un clúster de PostgreSQL como postgres_old_datadir y postgres_new_datadir para almacenar la ruta del directorio de datos de PostgreSQL para las versiones antiguas y nuevas de PostgreSQL; postgres_new_confdir para almacenar la ruta del directorio de configuración de PostgreSQL para la nueva versión de PostgreSQL; postgres_old_dsn y postgres_new_dsn para almacenar la cadena de conexión para el pglupgrade_user para poder conectarse a la pglupgrade_database de los servidores primarios nuevos y antiguos. La propia cadena de conexión se compone de las variables configurables para que el usuario (pglupgrade_user ) y la base de datos (pglupgrade_database ) la información se puede cambiar para los diferentes casos de uso.
ansible_user: admin
pglupgrade_user: pglupgrade
pglupgrade_pass: pglupgrade123
pglupgrade_database: postgres
replica_user: postgres
replica_pass: ""
pgbouncer_user: pgbouncer
postgres_old_version: 9.5
postgres_new_version: 9.6
subscription_name: upgrade
replication_set: upgrade
initial_standbys: 1
postgres_old_dsn: "dbname={{pglupgrade_database}} host={{groups['old-primary'][0]}} user {{pglupgrade_user}}"
postgres_new_dsn: "dbname={{pglupgrade_database}} host={{groups['new-primary'][0]}} user={{pglupgrade_user}}"
postgres_old_datadir: "/var/lib/postgresql/{{postgres_old_version}}/main"
postgres_new_datadir: "/var/lib/postgresql/{{postgres_new_version}}/main"
postgres_new_confdir: "/etc/postgresql/{{postgres_new_version}}/main" Archivo de configuración (config.yml )
Como paso clave para cualquier actualización, se puede especificar la información de la versión de PostgreSQL para la versión actual (postgres_old_version ) y la versión a la que se actualizará (postgres_new_version ). A diferencia de la replicación física, donde la replicación es una copia del sistema a nivel de byte/bloque, la replicación lógica permite la replicación selectiva. donde la replicación puede copiar los datos lógicos incluyen bases de datos especificadas y las tablas en esas bases de datos. Por este motivo, config.yml permite configurar qué base de datos replicar a través de pglupgrade_database variable. Además, el usuario de replicación lógica debe tener privilegios de replicación, razón por la cual pglupgrade_user La variable debe especificarse en el archivo de configuración. Hay otras variables que están relacionadas con el funcionamiento interno de pglogical como subscription_name y replication_set que se utilizan en el rol pglógico.
Diseño de alta disponibilidad de la herramienta Pglupgrade
La herramienta Pglupgrade está diseñada para brindar flexibilidad en términos de propiedades de alta disponibilidad (HA) al usuario para los diferentes requisitos del sistema. Los initial_standbys variable (ver config.yml ) es la clave para designar las propiedades HA del clúster mientras se lleva a cabo la operación de actualización.
Por ejemplo, si initial_standbys se establece en 1 (se puede establecer en cualquier número que permita la capacidad del clúster), lo que significa que se creará 1 en espera en el clúster actualizado junto con el maestro antes de que comience la replicación. En otras palabras, si tiene 4 servidores y establece initial_standbys en 1, tendrá 1 servidor principal y 1 en espera en la nueva versión actualizada, así como 1 servidor principal y 1 en espera en la versión anterior.
Esta opción permite reutilizar los servidores existentes mientras se realiza la actualización. En el ejemplo de 4 servidores, los servidores principal y en espera antiguos se pueden reconstruir como 2 nuevos servidores en espera una vez finalizada la replicación.
Cuando initial_standbys se establece en 0, no se crearán servidores en espera iniciales en el nuevo clúster antes de que comience la replicación.
Si initial_standbys la configuración suena confusa, no te preocupes. Esto se explicará mejor en la próxima publicación del blog cuando discutamos dos estudios de casos diferentes.
Finalmente, el archivo de configuración permite especificar grupos de servidores antiguos y nuevos. Esto podría proporcionarse de dos maneras. Primero, si hay un clúster existente, las direcciones IP de los servidores (pueden ser servidores bare-metal o virtuales ) debe ingresarse en hosts.ini archivo considerando las propiedades HA deseadas durante la operación de actualización.
La segunda forma es ejecutar provision.yml playbook (así es como aprovisioné las instancias en la nube, pero puede usar sus propios scripts de aprovisionamiento o aprovisionar instancias manualmente ) para aprovisionar servidores Linux vacíos en la nube (instancias AWS EC2) y obtener las direcciones IP de los servidores en hosts.ini expediente. De cualquier manera, config.yml obtendrá información del host a través de hosts.ini archivo.
Flujo de trabajo del proceso de actualización
Después de explicar el archivo de configuración (config.yml ) que utiliza pglupgrade playbook, podemos explicar el flujo de trabajo del proceso de actualización.
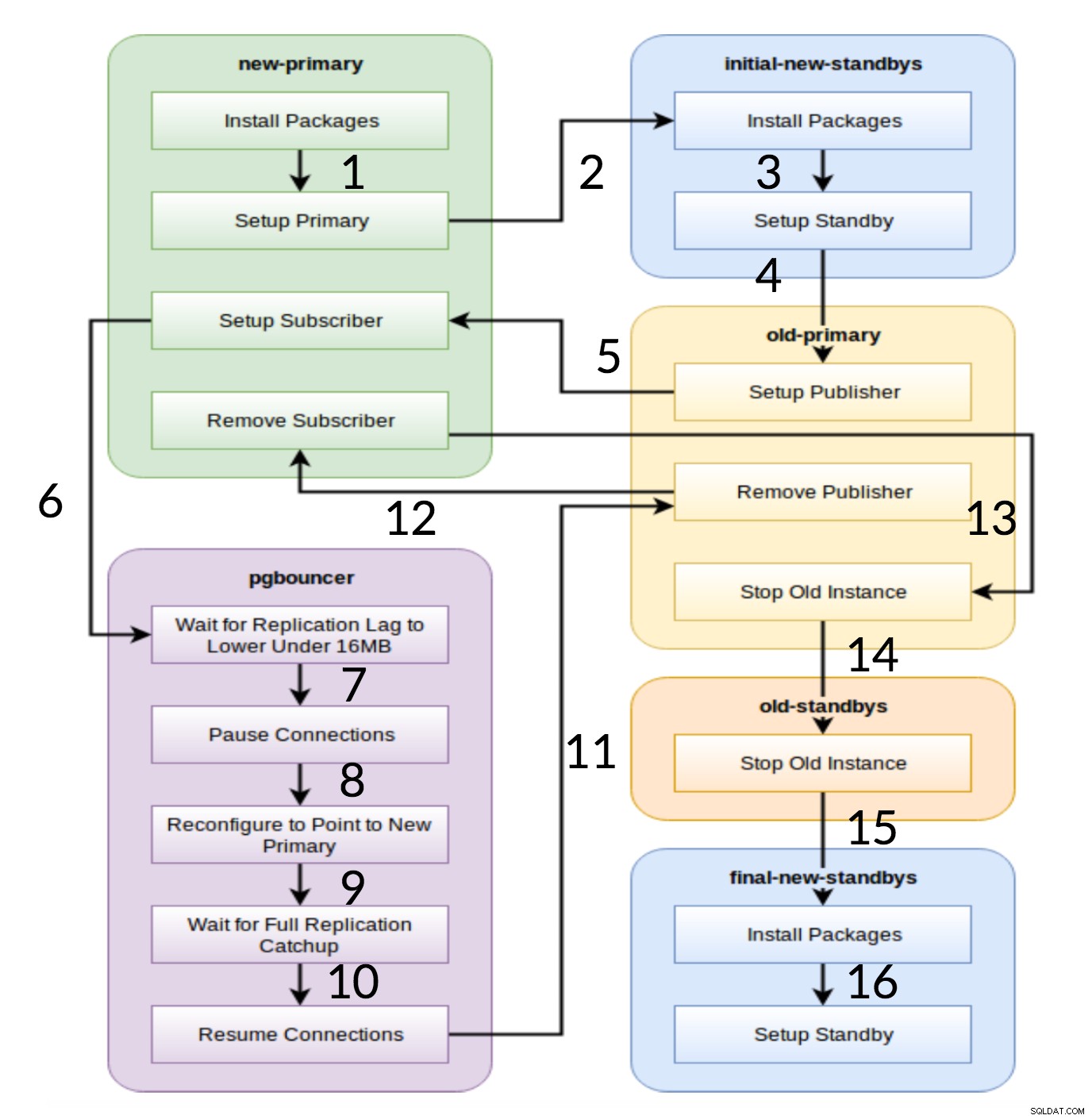
Flujo de trabajo de Pglupgrade
Como se ve en el diagrama anterior, hay seis grupos de servidores que se generan al principio en función de la configuración (ambos hosts.ini y el config.yml ). El new-primary y old-primary los grupos siempre tendrán un servidor, pgbouncer El grupo puede tener uno o más servidores y todos los grupos en espera pueden tener cero o más servidores. En cuanto a la implementación, todo el proceso se divide en ocho pasos. Cada paso corresponde a una jugada en el libro de jugadas pglupgrade, que realiza las tareas requeridas en los grupos de host asignados. El proceso de actualización se explica a través de las siguientes jugadas:
- Crear hosts según la configuración: Juego de preparación que construye grupos internos de servidores basados en la configuración. El resultado de este juego (en combinación con el
hosts.inicontenido) son los seis grupos de servidores (ilustrados con diferentes colores en el diagrama de flujo de trabajo) que se utilizarán en las siguientes siete obras. - Configurar un nuevo clúster con espera(s) inicial(es): Configura un clúster de PostgreSQL vacío con los nuevos recursos de reserva principales e iniciales (si hay alguno definido). Garantiza que no queden restos de las instalaciones de PostgreSQL del uso anterior.
- Modifique el principal anterior para admitir la replicación lógica: Instala la extensión pglogical. Luego establece el editor agregando todas las tablas y secuencias a la replicación.
- Replicar al nuevo principal: Configura el suscriptor en el nuevo maestro que actúa como disparador para iniciar la replicación lógica. Esta reproducción termina de replicar los datos existentes y comienza a recuperar lo que ha cambiado desde que comenzó la replicación.
- Cambie el pgbouncer (y las aplicaciones) a la nueva primaria: Cuando el retraso de la replicación converge a cero, el pgbouncer detiene para cambiar la aplicación gradualmente. Luego apunta la configuración de pgbouncer al nuevo primario y espera hasta que la diferencia de replicación llegue a cero. Finalmente, pgbouncer se reanuda y todas las transacciones en espera se propagan al nuevo primario y comienzan a procesarse allí. Los modos de espera iniciales ya están en uso y responden solicitudes de lectura.
- Limpiar la configuración de la replicación entre el principal antiguo y el principal nuevo: Finaliza la conexión entre los servidores primarios antiguo y nuevo. Dado que todas las aplicaciones se mueven al nuevo servidor primario y se realiza la actualización, ya no se necesita la replicación lógica. La replicación entre los servidores principal y en espera continúa con la replicación física.
- Detener el clúster antiguo: El servicio de Postgres se detiene en hosts antiguos para garantizar que ninguna aplicación pueda conectarse más.
- Reconfigure el resto de los recursos de reserva para el nuevo principal: Reconstruye otros recursos de reserva si quedan hosts distintos de los recursos de reserva iniciales. En el segundo estudio de caso, no quedan servidores en espera para reconstruir. Este paso brinda la oportunidad de reconstruir el servidor principal antiguo como un nuevo servidor de reserva si se indica en el grupo de nuevos servidores de reserva en hosts.ini. La reutilización de los servidores existentes (incluso el principal anterior) se logra mediante el diseño de configuración en espera de dos pasos de la herramienta pglupgrade. El usuario puede especificar qué servidores deben convertirse en servidores de reserva del nuevo clúster antes de la actualización y cuáles deben convertirse en servidores de reserva después de la actualización.
Conclusión
En esta publicación, discutimos los detalles de implementación y el diseño de alta disponibilidad de la herramienta pglupgrade. Al hacerlo, también mencionamos algunos conceptos clave del desarrollo de Ansible (es decir, libro de jugadas, inventario y archivos de configuración) usando la herramienta como ejemplo. Ilustramos el flujo de trabajo del proceso de actualización y resumimos cómo funciona cada paso con una jugada correspondiente. Continuaremos explicando pglupgrade mostrando estudios de casos en próximas publicaciones de esta serie.
¡Gracias por leer!