NO usar índices excepto por clave numérica única única.
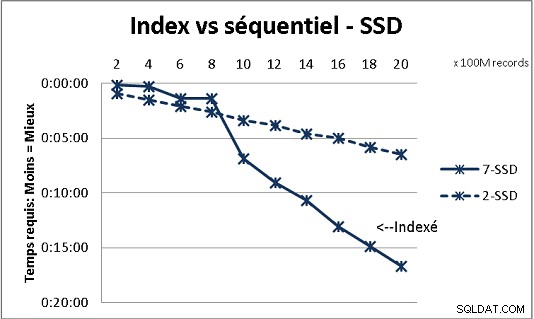
Eso no encaja con toda la teoría de DB que recibimos, pero las pruebas con una gran cantidad de datos lo demuestran. Aquí hay un resultado de 100 millones de cargas a la vez para llegar a 2 mil millones de filas en una tabla, y cada vez un montón de varias consultas en la tabla resultante. Primera gráfica con NAS de 10 gigabits (150 MB/s), segunda con 4 SSD en RAID 0 (R/W @ 2 GB/s).
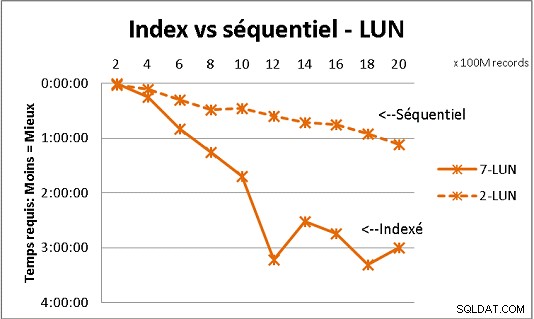
Si tiene más de 200 millones de filas en una tabla en discos regulares, es más rápido si olvida los índices. En SSD, el límite es de mil millones.
También lo he hecho con particiones para obtener mejores resultados, pero con PG9.2 es difícil beneficiarse de ellas si usa procedimientos almacenados. También debe tener cuidado de escribir/leer en solo 1 partición a la vez. Sin embargo, las particiones son el camino a seguir para mantener sus mesas por debajo de la pared de mil millones de filas. También ayuda mucho para multiprocesar sus cargas. Con SSD, el proceso único me permite insertar (copiar) 18 000 filas/s (con algo de trabajo de procesamiento incluido). Con multiprocesamiento en 6 CPU, crece a 80 000 filas/s.
Observe su uso de CPU y E/S mientras realiza pruebas para optimizar ambos.