En este artículo vamos a construir un raspador para un real concierto independiente donde el cliente quiere un programa de Python para extraer datos de Stack Overflow para obtener nuevas preguntas (título de la pregunta y URL). Luego, los datos extraídos deben almacenarse en MongoDB. Vale la pena señalar que Stack Overflow tiene una API, que se puede usar para acceder a la exacta mismos datos. Sin embargo, el cliente quería un raspador, así que lo que obtuvo fue un raspador.
Bono gratis: Haga clic aquí para descargar un esqueleto de proyecto de Python + MongoDB con el código fuente completo que le muestra cómo acceder a MongoDB desde Python.
Actualizaciones:
- 03/01/2014 - Se refactorizó la araña. Gracias, @kissgyorgy.
- 18/02/2015 - Parte 2 agregada.
- 09/06/2015 - Actualizado a la última versión de Scrapy y PyMongo - ¡salud!
Como siempre, asegúrese de revisar los términos de uso/servicio del sitio y respete el robots.txt archivo antes de comenzar cualquier trabajo de raspado. Asegúrese de adherirse a las prácticas éticas de raspado al no inundar el sitio con numerosas solicitudes en un corto período de tiempo. Trate cualquier sitio que extraiga como si fuera suyo .
Instalación
Necesitamos la biblioteca Scrapy (v1.0.3) junto con PyMongo (v3.0.3) para almacenar los datos en MongoDB. También necesita instalar MongoDB (no cubierto).
Raspado
Si está ejecutando OSX o una versión de Linux, instale Scrapy con pip (con su virtualenv activado):
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt
Si está en una máquina con Windows, deberá instalar manualmente una serie de dependencias. Consulte la documentación oficial para obtener instrucciones detalladas, así como este video de Youtube que creé.
Una vez que Scrapy esté configurado, verifique su instalación ejecutando este comando en el shell de Python:
>>>>>> import scrapy
>>>
Si no obtiene un error, ¡entonces está listo para continuar!
PyMongo
A continuación, instale PyMongo con pip:
$ pip install pymongo
$ pip freeze > requirements.txt
Ahora podemos comenzar a construir el rastreador.
Proyecto Scrapy
Comencemos un nuevo proyecto de Scrapy:
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
Esto crea una cantidad de archivos y carpetas que incluyen un modelo básico para que pueda comenzar rápidamente:
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
Especificar datos
Los elementos.py El archivo se usa para definir "contenedores" de almacenamiento para los datos que planeamos extraer.
StackItem() la clase hereda de Item (docs), que básicamente tiene una serie de objetos predefinidos que Scrapy ya ha creado para nosotros:
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
Agreguemos algunos elementos que realmente queremos recopilar. Para cada pregunta, el cliente necesita el título y la URL. Entonces, actualice items.py así:
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
Crea la araña
Cree un archivo llamado stack_spider.py en el directorio "arañas". Aquí es donde ocurre la magia, por ejemplo, donde le diremos a Scrapy cómo encontrar el exacto datos que estamos buscando. Como puedes imaginar, esto es específico a cada página web individual que desea raspar.
Comience definiendo una clase que herede de Spider de Scrapy y luego agregar atributos según sea necesario:
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
Las primeras variables se explican por sí mismas (docs):
namedefine el nombre de la Araña.allowed_domainscontiene las URL base de los dominios permitidos para que la araña los rastree.start_urlses una lista de URL para que la araña comience a rastrear. Todas las URL posteriores comenzarán a partir de los datos que la araña descarga de las URL enstart_urls.
Selectores XPath
Luego, Scrapy usa selectores XPath para extraer datos de un sitio web. En otras palabras, podemos seleccionar ciertas partes de los datos HTML en función de un XPath determinado. Como se indica en la documentación de Scrapy, "XPath es un lenguaje para seleccionar nodos en documentos XML, que también se puede usar con HTML".
Puede encontrar fácilmente un XPath específico utilizando las herramientas para desarrolladores de Chrome. Simplemente inspeccione un elemento HTML específico, copie el XPath y luego modifique (según sea necesario):
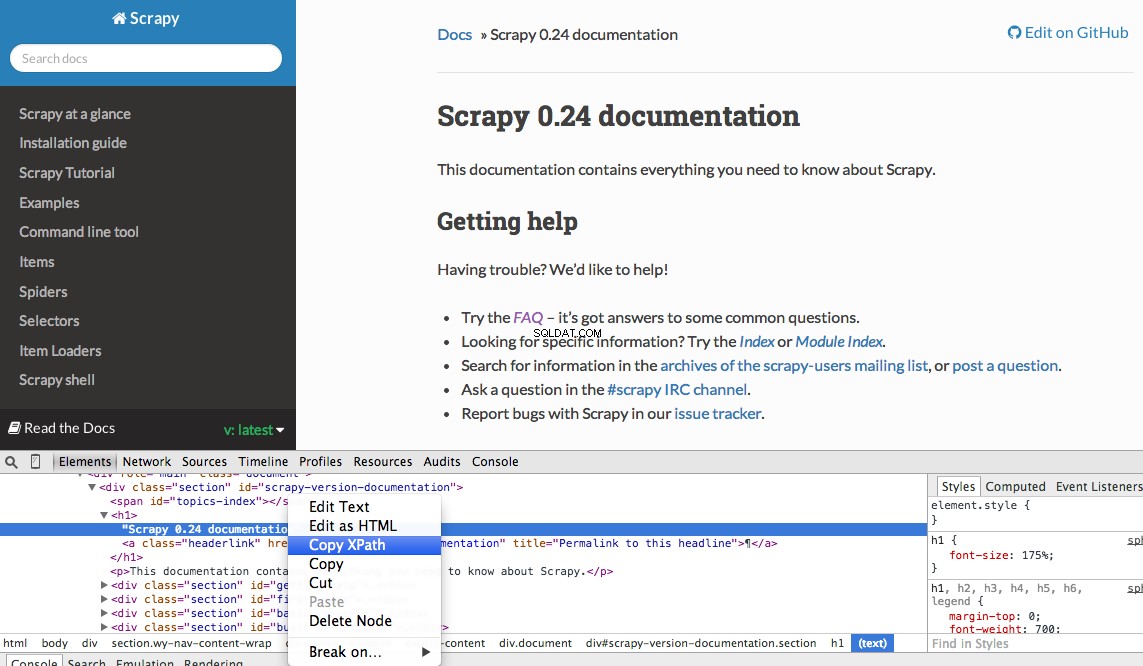
Developer Tools también le brinda la posibilidad de probar los selectores de XPath en la consola de JavaScript usando $x - es decir, $x("//img") :
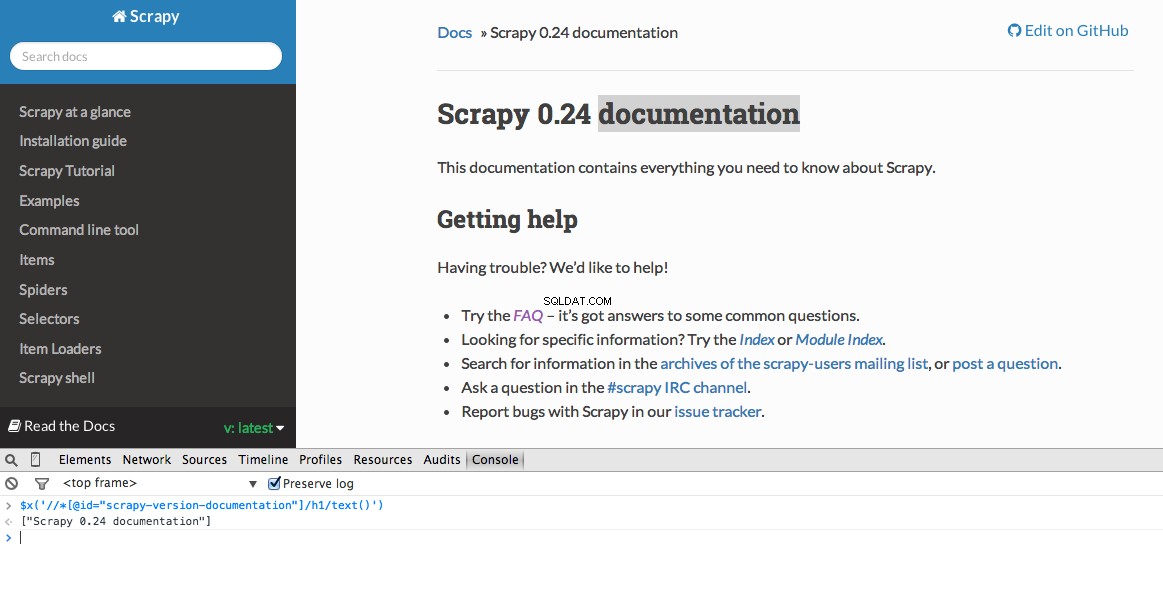
Nuevamente, básicamente le decimos a Scrapy dónde comenzar a buscar información basada en un XPath definido. Vayamos al sitio de Stack Overflow en Chrome y busquemos los selectores de XPath.
Haga clic con el botón derecho en la primera pregunta y seleccione "Inspeccionar elemento":
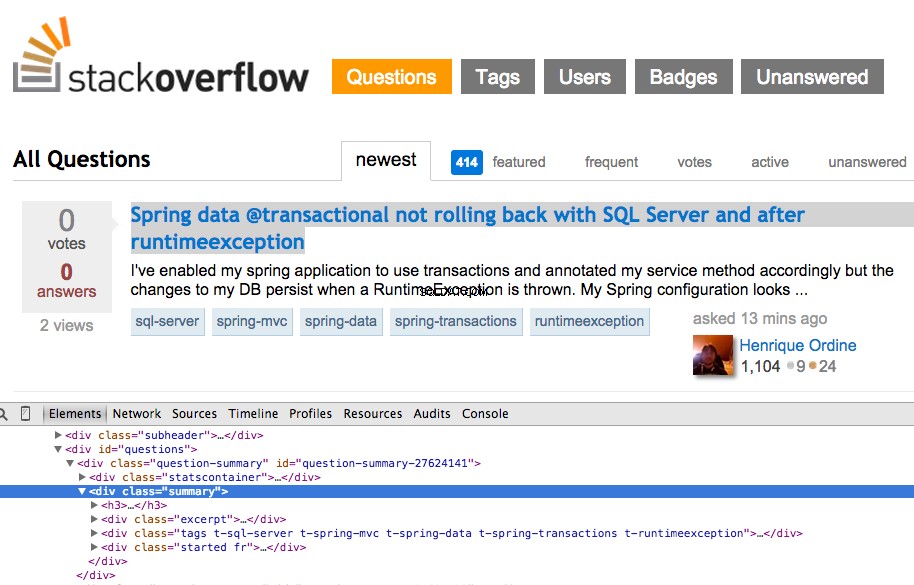
Ahora tome el XPath para el <div class="summary"> , //*[@id="question-summary-27624141"]/div[2] y luego pruébelo en la consola de JavaScript:
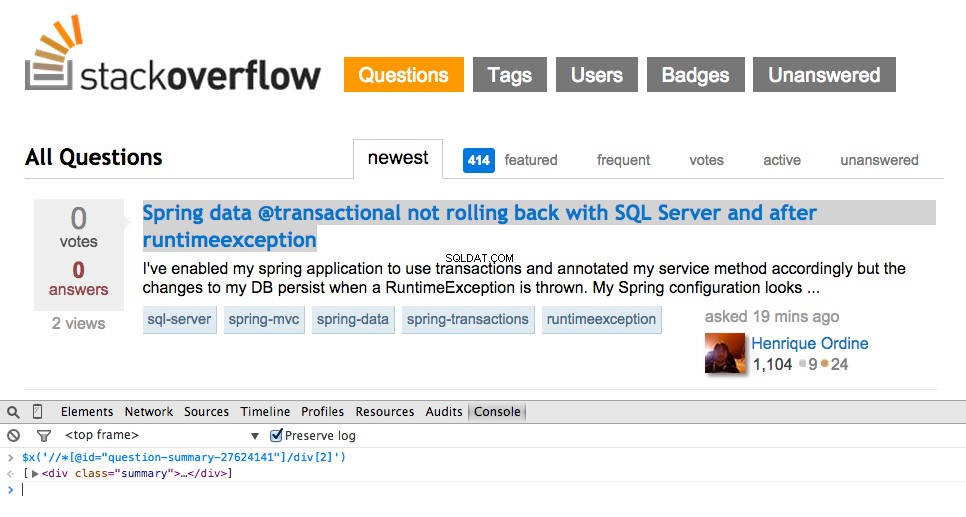
Como puede ver, solo selecciona ese uno pregunta. Por lo tanto, debemos modificar el XPath para obtener todos preguntas. ¿Algunas ideas? Es simple://div[@class="summary"]/h3 . ¿Qué significa esto? Esencialmente, este XPath dice:Toma todo <h3> elementos que son hijos de un <div> que tiene una clase de summary . Pruebe este XPath en la consola de JavaScript.
Observe cómo no estamos usando la salida XPath real de Chrome Developer Tools. En la mayoría de los casos, la salida es solo un complemento útil, que generalmente lo indica en la dirección correcta para encontrar el XPath que funcione.
Ahora actualicemos stack_spider.py guión:
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
Extraer los datos
Todavía necesitamos analizar y raspar los datos que queremos, que se encuentran dentro de <div class="summary"><h3> . Nuevamente, actualice stack_spider.py así:
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
````
We are iterating through the `questions` and assigning the `title` and `url` values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()')` and `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href')`.
## Test
Ready for the first test? Simply run the following command within the "stack" directory:
```console
$ scrapy crawl stack
Junto con el seguimiento de la pila de Scrapy, debería ver 50 títulos de preguntas y URL generados. Puede representar la salida en un archivo JSON con este pequeño comando:
$ scrapy crawl stack -o items.json -t json
Ahora hemos implementado nuestra araña en función de los datos que estamos buscando. Ahora necesitamos almacenar los datos raspados dentro de MongoDB.
Almacenar los datos en MongoDB
Cada vez que se devuelve un elemento, queremos validar los datos y luego agregarlo a una colección de Mongo.
El paso inicial es crear la base de datos que planeamos usar para guardar todos nuestros datos rastreados. Abra configuraciones.py y especifique la canalización y agregue la configuración de la base de datos:
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
Gestión de tuberías
Hemos configurado nuestra araña para rastrear y analizar el HTML, y hemos configurado la configuración de nuestra base de datos. Ahora tenemos que conectar los dos a través de una canalización en pipelines.py .
Conectar a la base de datos
Primero, definamos un método para conectarnos a la base de datos:
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
Aquí, creamos una clase, MongoDBPipeline() , y tenemos una función constructora para inicializar la clase definiendo la configuración de Mongo y luego conectándonos a la base de datos.
Procesar los datos
A continuación, debemos definir un método para procesar los datos analizados:
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
Establecemos una conexión a la base de datos, desempaquetamos los datos y luego los guardamos en la base de datos. ¡Ahora podemos probar de nuevo!
Prueba
Nuevamente, ejecute el siguiente comando dentro del directorio "stack":
$ scrapy crawl stack
NOTA :Asegúrese de tener el demonio Mongo - mongod - ejecutándose en una ventana de terminal diferente.
¡Hurra! Hemos almacenado con éxito nuestros datos rastreados en la base de datos:
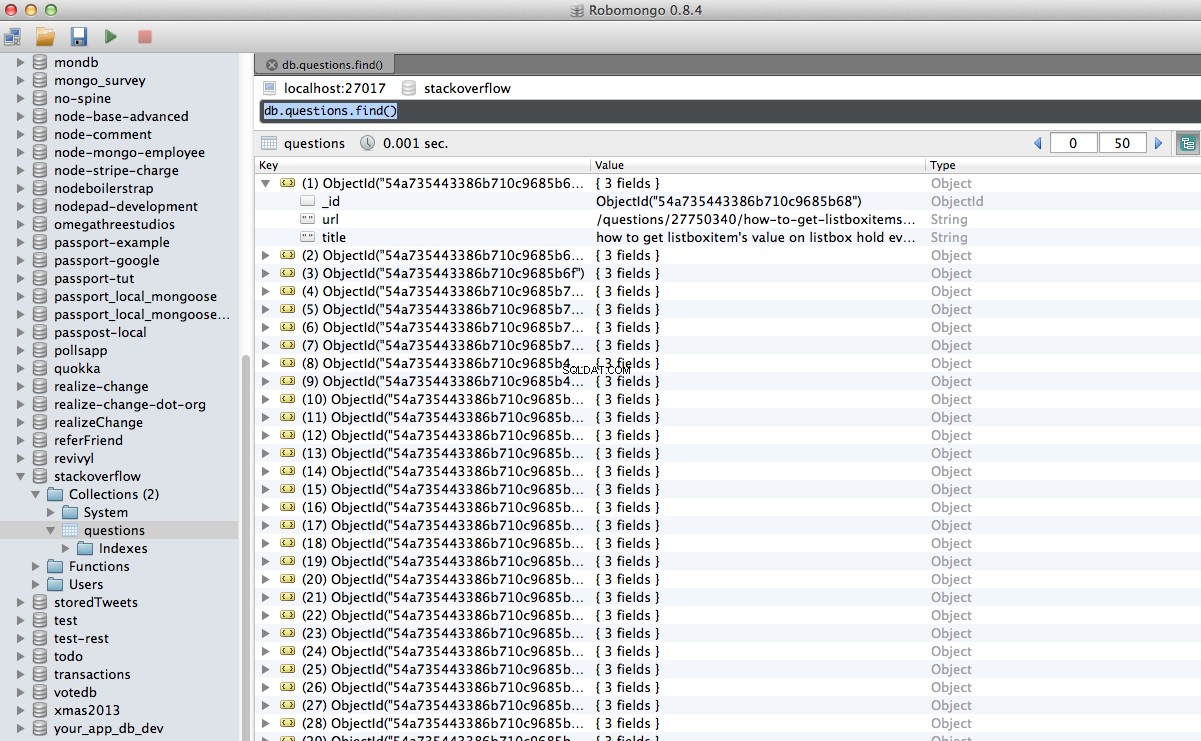
Conclusión
Este es un ejemplo bastante simple del uso de Scrapy para rastrear y raspar una página web. El proyecto independiente real requería que el script siguiera los enlaces de paginación y extrajera cada página usando el CrawlSpider (docs), que es muy fácil de implementar. Intente implementar esto por su cuenta y deje un comentario a continuación con el enlace al repositorio de Github para una revisión rápida del código.
¿Necesitas ayuda? Comience con este script, que está casi completo. ¡Entonces vea la Parte 2 para obtener la solución completa!
Bono gratis: Haga clic aquí para descargar un esqueleto de proyecto de Python + MongoDB con el código fuente completo que le muestra cómo acceder a MongoDB desde Python.
Puede descargar el código fuente completo desde el repositorio de Github. Comenta abajo con preguntas. ¡Gracias por leer!



