En este blog, le proporcionaremos la introducción completa de Hadoop Mapper . yo
En este blog, responderemos qué es Mapper en Hadoop MapReduce, cómo funciona Hadoop Mapper, cuáles son los procesos de Mapper en MapReduce, cómo Hadoop genera un par clave-valor en MapReduce.
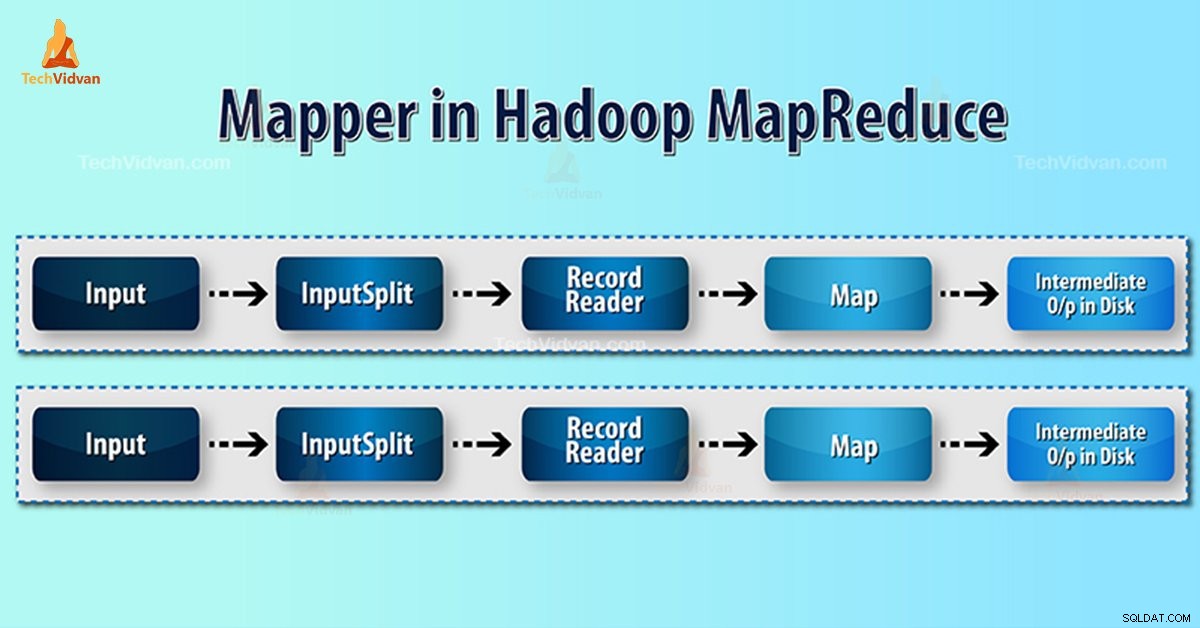
Introducción a Hadoop Mapper
Mapeador de Hadoop procesa el registro de entrada producido por RecordReader y genera pares clave-valor intermedios. La salida intermedia es completamente diferente del par de entrada.
La salida del mapeador es la colección completa de pares clave-valor. Antes de escribir la salida para cada tarea del mapeador, la partición de la salida se realiza sobre la base de la clave. Por lo tanto, la partición detalla que todos los valores de cada clave se agrupan.
Hadoop MapReduce genera una tarea de mapa para cada InputSplit.
Hadoop MapReduce solo comprende pares de datos clave-valor. Entonces, antes de enviar datos al mapeador, el marco Hadoop debería convertir los datos en el par clave-valor.
¿Cómo se genera el par clave-valor en Hadoop?
Como hemos entendido qué es el mapeador en Hadoop, ahora discutiremos cómo genera Hadoop el par clave-valor.
- División de entrada: Es la representación lógica de los datos generados por el InputFormat. En el programa MapReduce, describe una unidad de trabajo que contiene una sola tarea de mapa.
- Lector de registros- Se comunica con el inputSplit. Y luego convierte los datos en pares clave-valor adecuados para que Mapper los lea. RecordReader usa de forma predeterminada TextInputFormat para convertir datos en el par clave-valor.
Proceso de asignación en Hadoop MapReduce
División de entrada convierte la representación física de los bloques en lógica para el Mapeador. Por ejemplo, para leer el archivo de 100 MB, requerirá 2 InputSplit. Para cada bloque, el marco crea un InputSplit. Cada InputSplit crea un mapeador.
MapReduce InputSplit no siempre depende de la cantidad de bloques de datos . Podemos cambiar el número de una división configurando propiedad mapred.max.split.size durante la ejecución del trabajo.
MapReduce RecordReader es responsable de leer/convertir datos en pares clave-valor hasta el final del archivo. RecordReader asigna el desplazamiento de bytes a cada línea presente en el archivo.
Luego, Mapper recibe este par de claves. Mapper produce la salida intermedia (pares clave-valor que son comprensibles para reducir).
¿Cuántas tareas de mapas en Hadoop?
El número de tareas de mapa depende del número total de bloques de los archivos de entrada. En el mapa MapReduce, el nivel correcto de paralelismo parece estar alrededor de 10-100 mapas/nodo. Pero hay 300 mapas para tareas de mapas de CPU ligera.
Por ejemplo, tenemos un tamaño de bloque de 128 MB. Y esperamos 10 TB de datos de entrada. Así produce 82.000 mapas. Por lo tanto, el número de mapas depende de InputFormat.
Mapeador =(tamaño total de datos)/ (tamaño de división de entrada)
Ejemplo – el tamaño de los datos es de 1 TB. El tamaño de división de entrada es de 100 MB.
Asignador =(1000*1000)/100 =10 000
Conclusión
Por lo tanto, Mapper en Hadoop toma un conjunto de datos y lo convierte en otro conjunto de datos. Por lo tanto, divide los elementos individuales en tuplas (pares clave/valor).
Espero que le guste este bloque, si tiene alguna consulta sobre el mapeador de Hadoop, deje un comentario en la sección que figura a continuación. Estaremos encantados de resolverlos.



