Hasta ahora hemos cubierto la introducción de Hadoop y Hadoop HDFS en detalle. En este tutorial, le proporcionaremos una descripción detallada de Hadoop Reducer.
Aquí se discutirá qué es Reducer en MapReduce, cómo funciona Reducer en Hadoop MapReduce, diferentes fases de Hadoop Reducer, cómo podemos cambiar el número de Reducer en Hadoop MapReduce.
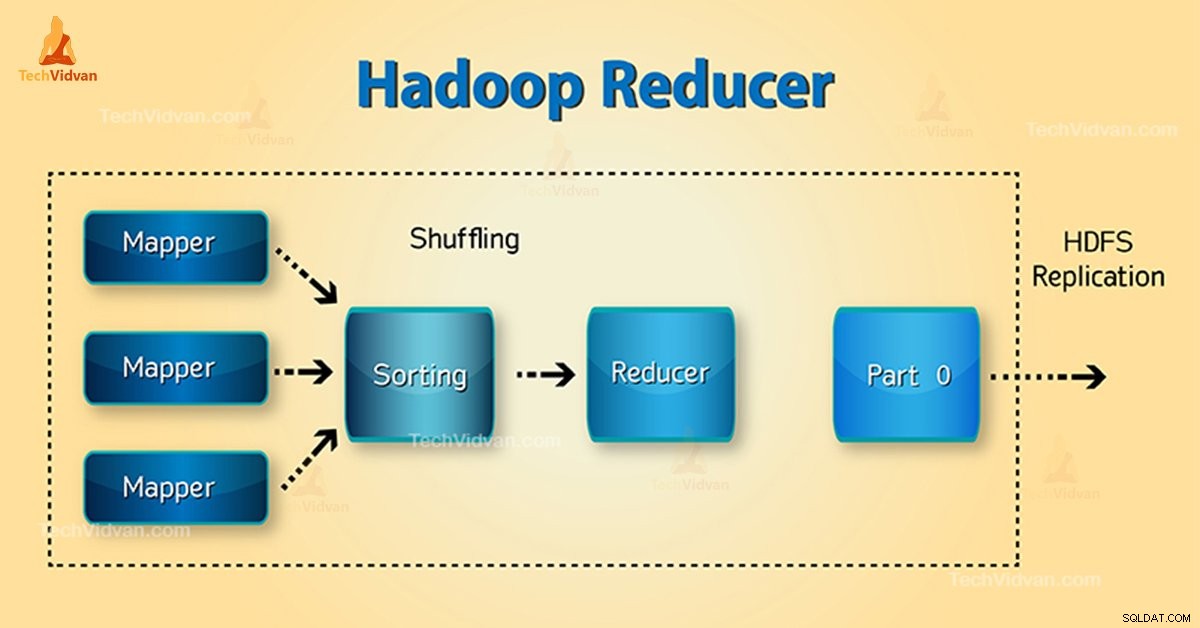
¿Qué es el reductor de Hadoop?
Reductor en Hadoop MapReduce reduce un conjunto de valores intermedios que comparten una clave a un conjunto de valores más pequeño.
En el flujo de ejecución de tareas de MapReduce, Reducer toma un conjunto de un par clave-valor intermedio producido por el mapeador como entrada. Luego, Reducer agrega, filtra y combina pares clave-valor y esto requiere una amplia gama de procesamiento.
El mapeo uno a uno se lleva a cabo entre claves y reductores en la ejecución del trabajo MapReduce. Funcionan en paralelo ya que son independientes entre sí. El usuario decide el número de reductores en MapReduce.
Fases de Hadoop Reducer
Las tres fases de Reducer son las siguientes:
1. Fase aleatoria
Esta es la fase en la que la salida ordenada del mapeador es la entrada al reductor. El marco con la ayuda de HTTP recupera la partición relevante de la salida de todos los mapeadores en esta fase. Fase de clasificación
2. Fase de clasificación
Esta es la fase en la que la entrada de diferentes mapeadores se ordena nuevamente en función de las claves similares en diferentes mapeadores.
Tanto Shuffle como Sort ocurren simultáneamente.
3. Reducir Fase
Esta fase se produce después de barajar y ordenar. Reducir la tarea agrega los pares clave-valor. Con el OutputCollector.collect() propiedad, la salida de la tarea reduce se escribe en FileSystem. La salida del reductor no está ordenada.
Número de reductores en Hadoop MapReduce
El usuario establece el número de reductores con la ayuda de Job.setNumreduceTasks(int) propiedad. Por lo tanto, el número correcto de reductores por la fórmula:
0,95 o 1,75 multiplicado por (
Entonces, con 0.95, todos los reductores se lanzan inmediatamente. Luego, comience a transferir las salidas del mapa a medida que finalicen los mapas.
Nodo más rápido termina la primera ronda de reductores con 1,75. Luego lanza la segunda ola de reductor que hace mucho mejor trabajo de balanceo de carga.
Con el aumento del número de reductores:
- Aumenta la sobrecarga del marco.
- Aumenta el equilibrio de carga.
- Disminuye el costo de las fallas.
Conclusión
Por lo tanto, Reducer toma la salida de los mapeadores como entrada. Luego, procese los pares clave-valor y produzca la salida. La salida del reductor es la salida final. Si le gusta este blog o tiene alguna consulta relacionada con Hadoop Reducer, comparta con nosotros dejando un comentario.
Espero que te ayudemos.



