Apache Hadoop es un marco de software que procesa y almacena grandes datos en el clúster de hardware básico. Hadoop se basa en el modelo MapReduce para procesar grandes cantidades de datos de forma distribuida.
Este tutorial de MapReduce incluyó varias características de MapReduce. Después de leer esto, comprenderá claramente por qué MapReduce es la mejor opción para procesar grandes cantidades de datos.
Primero, veremos una pequeña introducción al framework MapReduce. Luego exploraremos varias funciones de MapReduce.
Comencemos con la introducción al marco MapReduce.
Introducción a MapReduce
MapReduce es un marco de software para escribir aplicaciones que pueden procesar grandes cantidades de datos en los clústeres de nodos económicos. Hadoop MapReduce es la parte de procesamiento de Apache Hadoop.
También se le conoce como el corazón de Hadoop. Es la aplicación de procesamiento de datos más preferida. Varios jugadores en el sector del comercio electrónico como Amazon, Yahoo y Zuventus, etc. están utilizando el marco MapReduce para el procesamiento de datos de gran volumen.
Estudiemos ahora las diversas funciones de Hadoop MapReduce.
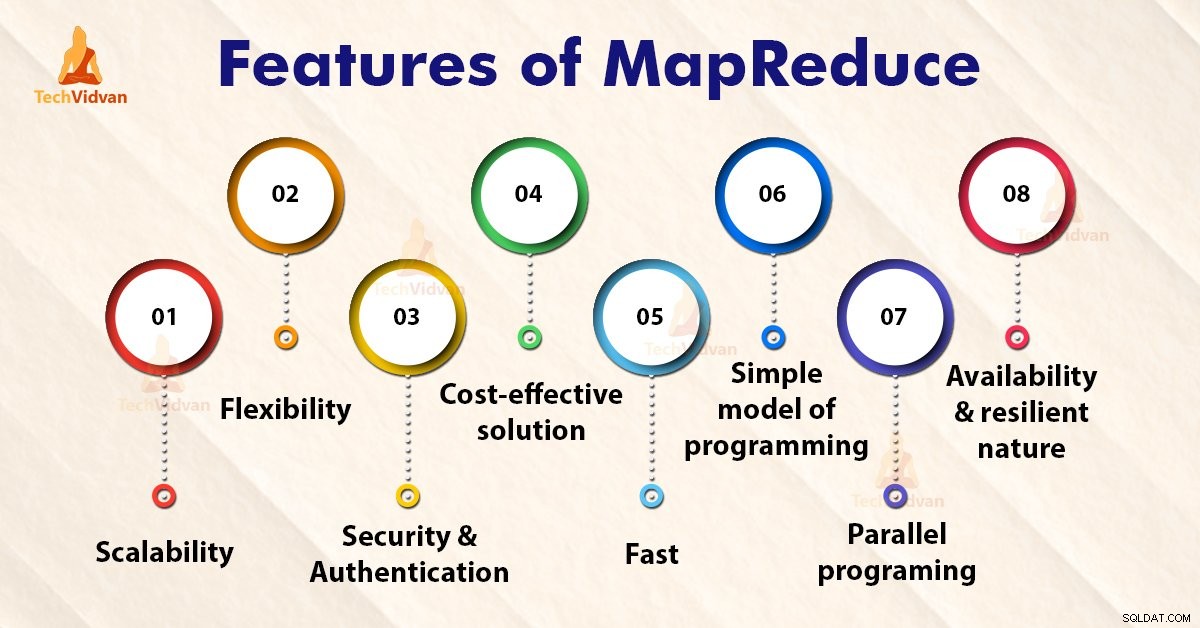
Características de MapReduce
1. Escalabilidad
Apache Hadoop es un marco altamente escalable. Esto se debe a su capacidad para almacenar y distribuir grandes cantidades de datos en muchos servidores. Todos estos servidores eran económicos y podían operar en paralelo. Podemos escalar fácilmente el almacenamiento y el poder de cómputo agregando servidores al clúster.
La programación de Hadoop MapReduce permite a las organizaciones ejecutar aplicaciones desde grandes conjuntos de nodos, lo que podría implicar el uso de miles de terabytes de datos.
La programación de Hadoop MapReduce permite a las organizaciones comerciales ejecutar aplicaciones desde grandes conjuntos de nodos. Esto puede usar miles de terabytes de datos.
2. Flexibilidad
La programación de MapReduce permite a las empresas acceder a nuevas fuentes de datos. Permite a las empresas operar con diferentes tipos de datos. Permite a las empresas acceder a datos estructurados y no estructurados y obtener un valor significativo al obtener información de las múltiples fuentes de datos.
Además, el marco MapReduce también brinda soporte para múltiples idiomas y datos de fuentes que van desde correo electrónico, redes sociales hasta flujo de clics.
MapReduce procesa datos en pares clave-valor simples, por lo que admite tipos de datos que incluyen metadatos, imágenes y archivos grandes. Por lo tanto, MapReduce es flexible para manejar datos en lugar de DBMS tradicional.
3. Seguridad y autenticación
El modelo de programación de MapReduce utiliza la plataforma de seguridad HBase y HDFS que permite el acceso solo a los usuarios autenticados para operar sobre los datos. Por lo tanto, protege el acceso no autorizado a los datos del sistema y mejora la seguridad del sistema.
4. Solución rentable
La arquitectura escalable de Hadoop con el marco de programación MapReduce permite el almacenamiento y procesamiento de grandes conjuntos de datos de una manera muy asequible.
5. Rápido
Hadoop utiliza un método de almacenamiento distribuido llamado Sistema de archivos distribuidos de Hadoop que básicamente implementa un sistema de mapeo para ubicar datos en un clúster.
Las herramientas que se utilizan para el procesamiento de datos, como la programación de MapReduce, generalmente se encuentran en los mismos servidores que permiten un procesamiento de datos más rápido.
Entonces, incluso si estamos tratando con grandes volúmenes de datos no estructurados, Hadoop MapReduce solo toma unos minutos para procesar terabytes de datos. Puede procesar petabytes de datos en solo una hora.
6. Modelo simple de programación
Entre las diversas funciones de Hadoop MapReduce, una de las más importantes es que se basa en un modelo de programación simple. Básicamente, esto permite a los programadores desarrollar los programas MapReduce que pueden manejar tareas de manera fácil y eficiente.
Los programas de MapReduce se pueden escribir en Java, que no es muy difícil de aprender y también se usa ampliamente. Por lo tanto, cualquiera puede aprender y escribir fácilmente programas MapReduce y satisfacer sus necesidades de procesamiento de datos.
7. Programación en paralelo
Uno de los aspectos principales del funcionamiento de la programación de MapReduce es su procesamiento paralelo. Divide las tareas de una manera que permite su ejecución en paralelo.
El procesamiento en paralelo permite que múltiples procesadores ejecuten estas tareas divididas. Así todo el programa se ejecuta en menos tiempo.
8. Disponibilidad y naturaleza resiliente
Cada vez que los datos se envían a un nodo individual, el mismo conjunto de datos se envía a otros nodos en un clúster. Por lo tanto, si algún nodo en particular sufre una falla, siempre hay otras copias presentes en otros nodos a las que aún se puede acceder cuando sea necesario. Esto asegura una alta disponibilidad de datos.
Una de las principales características que ofrece Apache Hadoop es su tolerancia a fallas. El marco Hadoop MapReduce tiene la capacidad de reconocer rápidamente las fallas que ocurren.
Luego aplica una solución de recuperación rápida y automática. Esta función lo convierte en un punto de inflexión en el mundo del procesamiento de big data.
Resumen
Espero que después de leer este artículo haya entendido claramente las diversas funciones de Hadoop MapReduce. El artículo enumeró varias características de MapReduce. El marco MapReduce es un sistema de procesamiento escalable, flexible, rentable y rápido.
Ofrece seguridad, tolerancia a fallas y autenticación. MapReduce es un modelo simple de programación y ofrece programación paralela.



