Si quiere saber todo sobre Hadoop MapReduce, ha aterrizado en el lugar correcto. Este tutorial de MapReduce le brinda la guía completa sobre todos y cada uno de los elementos de Hadoop MapReduce.
En esta Introducción de MapReduce, explorará qué es Hadoop MapReduce, cómo funciona el marco MapReduce. El artículo también cubre MapReduce DataFlow, diferentes fases en MapReduce, Mapper, Reducer, Partitioner, Cominer, Shuffling, Sorting, Data Locality y muchos más.
También hemos enumerado las ventajas del marco MapReduce.
Primero exploremos por qué necesitamos Hadoop MapReduce.
¿Por qué MapReduce?
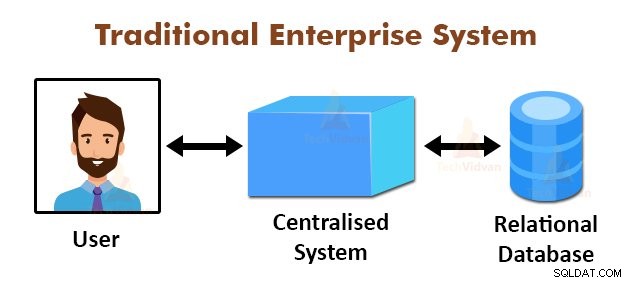
La figura anterior muestra la vista esquemática de los sistemas empresariales tradicionales. Los sistemas tradicionales normalmente tienen un servidor centralizado para almacenar y procesar datos. Este modelo no es adecuado para procesar grandes cantidades de datos escalables.
Además, los servidores de bases de datos estándar no podían acomodar este modelo. Además, el sistema centralizado crea demasiados cuellos de botella al procesar varios archivos simultáneamente.
Mediante el uso del algoritmo MapReduce, Google resolvió este problema de cuello de botella. El marco MapReduce divide la tarea en partes pequeñas y asigna tareas a muchas computadoras.
Posteriormente, los resultados se recopilan en un lugar común y luego se integran para formar el conjunto de datos de resultados.
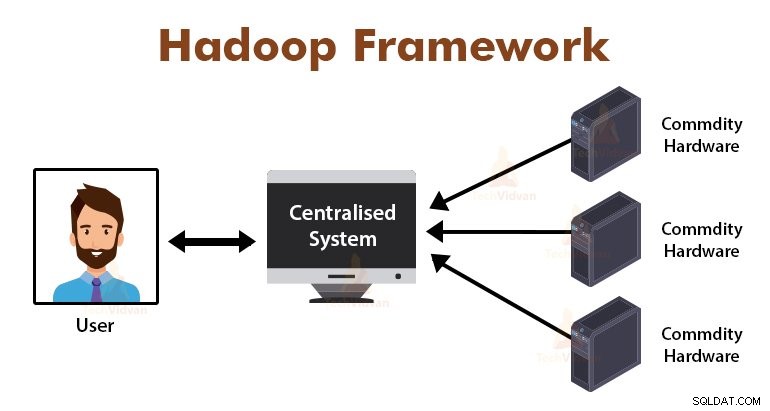
Introducción al Marco MapReduce
MapReduce es la capa de procesamiento en Hadoop. Es un marco de software diseñado para procesar grandes volúmenes de datos en paralelo al dividir la tarea en un conjunto de tareas independientes.
Solo necesitamos poner la lógica comercial en la forma en que funciona MapReduce, y el marco se encargará del resto. El marco MapReduce funciona dividiendo el trabajo en pequeñas tareas y asigna estas tareas a los esclavos.
Los programas de MapReduce están escritos en un estilo particular influenciado por las construcciones de programación funcional, modismos específicos para procesar las listas de datos.
En MapReduce, las entradas tienen la forma de una lista y la salida del marco también tiene la forma de una lista. MapReduce es el corazón de Hadoop. La eficiencia y la potencia de Hadoop se deben al procesamiento paralelo del marco MapReduce.
Exploremos ahora cómo funciona Hadoop MapReduce.
¿Cómo funciona Hadoop MapReduce?
El marco Hadoop MapReduce funciona dividiendo un trabajo en tareas independientes y ejecutando estas tareas en máquinas esclavas. El trabajo de MapReduce se ejecuta en dos etapas que son la fase de mapa y la fase de reducción.
La entrada y la salida de ambas fases son pares de valores clave. El marco MapReduce se basa en el principio de localidad de datos (que se analiza más adelante), lo que significa que envía el cálculo a los nodos donde residen los datos.
- Fase del mapa − En la fase de mapa, la función de mapa definida por el usuario procesa los datos de entrada. En la función de mapa, el usuario pone la lógica de negocio. El resultado de la fase de mapa son los resultados intermedios y se almacenan en el disco local.
- Fase de reducción: Esta fase es la combinación de la fase de reproducción aleatoria y la fase de reducción. En la fase Reducir, la salida de la etapa del mapa se pasa al Reductor donde se agregan. La salida de la fase Reducir es la salida final. En la fase de reducción, la función de reducción definida por el usuario procesa la salida de Mappers y genera los resultados finales.
Durante el trabajo MapReduce, el marco Hadoop envía las tareas Map y Reduce las tareas a las máquinas apropiadas en el clúster.
El propio marco gestiona todos los detalles del paso de datos, como la emisión de tareas, la verificación de la finalización de la tarea y la copia de datos entre los nodos del clúster. Las tareas tienen lugar en los nodos donde residen los datos para reducir el tráfico de red.
Flujo de datos MapReduce
Es posible que todos deseen saber cómo se generan estos pares de valores clave y cómo MapReduce procesa los datos de entrada. Esta sección responde a todas estas preguntas.
Veamos cómo deben fluir los datos de varias fases en Hadoop MapReduce para manejar los próximos datos de manera paralela y distribuida.
1. Archivos de entrada
El conjunto de datos de entrada, que debe ser procesado por el programa MapReduce, se almacena en InputFile. El archivo de entrada se almacena en el sistema de archivos distribuidos de Hadoop.
2. División de entrada
El registro en InputFiles se divide en el modelo lógico. El tamaño de división generalmente es igual al tamaño de bloque HDFS. Cada división es procesada por el asignador individual.
3. Formato de entrada
InputFormat especifica la especificación de entrada del archivo. Define la forma en que RecordReader convierte el registro de InputFile en pares clave-valor.
4. Lector de registros
RecordReader lee los datos de InputSplit y convierte los registros en pares de clave y valor y los presenta a los mapeadores.
5. Mapeadores
Los mapeadores toman pares de clave y valor como entrada del RecordReader y los procesan implementando la función de mapa definida por el usuario. En cada Mapeador, a la vez, se procesa una sola división.
El desarrollador puso la lógica empresarial en la función de mapa. La salida de todos los mapeadores es la salida intermedia, que también tiene la forma de pares de clave y valor.
6. Barajar y ordenar
La salida intermedia generada por Mappers se ordena antes de pasar al Reducer para reducir la congestión de la red. Las salidas intermedias ordenadas luego se barajan al Reducer a través de la red.
7. Reductor
El proceso Reducer y agrega las salidas de Mapper implementando la función de reducción definida por el usuario. La salida de Reducers es la salida final y se almacena en el sistema de archivos distribuidos de Hadoop (HDFS).
Estudiemos ahora algunas terminologías y conceptos avanzados del marco Hadoop MapReduce.
Pares clave-valor en MapReduce
El marco MapReduce funciona en los pares de clave y valor porque se ocupa del esquema no estático. Toma los datos en forma de clave, par de valores y la salida generada también tiene la forma de clave, pares de valores.
El par de valores de clave de MapReduce es una entidad de registro que recibe el trabajo de MapReduce para la ejecución. En un par clave-valor:
- La clave es el desplazamiento de línea desde el principio de la línea dentro del archivo.
- El valor es el contenido de la línea, excluyendo los terminadores de línea.
Partición MapReduce
Hadoop MapReduce Partitioner divide el espacio de claves. El espacio de claves de partición en MapReduce especifica que todos los valores de cada clave se agruparon y garantiza que todos los valores de la clave única deben ir al mismo Reducer.
Esta partición permite una distribución uniforme de la salida del mapeador sobre Reducer al garantizar que la clave correcta vaya al Reducer correcto.
El particionador predeterminado de MapReducer es Hash Partitioner, que divide los espacios de claves en función del valor hash.
Combinador MapReduce
El combinador MapReduce también se conoce como el "semirreductor". Desempeña un papel importante en la reducción de la congestión de la red. El marco MapReduce proporciona la funcionalidad para definir el Combinador, que combina la salida intermedia de Mappers antes de pasarlos a Reducer.
La agregación de las salidas de Mapper antes de pasar a Reducer ayuda al marco a mezclar pequeñas cantidades de datos, lo que lleva a una baja congestión de la red.
La función principal del Combiner es resumir la salida de los Mappers con la misma clave y pasarla al Reducer. La clase Combiner se usa entre la clase Mapper y la clase Reducer.
Localidad de datos en MapReduce
La localidad de los datos se refiere a “Acercar el cómputo a los datos en lugar de mover los datos al cómputo”. Es mucho más eficiente si el cómputo solicitado por la aplicación se ejecuta en la máquina donde residen los datos solicitados.
Esto es muy cierto en el caso de que el tamaño de los datos sea enorme. Es porque minimiza la congestión de la red y aumenta el rendimiento general del sistema.
La única suposición detrás de esto es que es mejor mover el cálculo más cerca de la máquina donde están presentes los datos en lugar de mover los datos a la máquina donde se ejecuta la aplicación.
Apache Hadoop funciona con un gran volumen de datos, por lo que no es eficiente mover datos tan grandes a través de la red. Por lo tanto, el marco ideó el principio más innovador que es la localidad de datos, que mueve la lógica de cálculo a los datos en lugar de mover los datos a los algoritmos de cálculo. Esto se llama localidad de datos.
Ventajas de MapReduce
Uso de MapReduce
Cada vez que se encuentra una página web en el registro, se pasa un par de clave y valor al reductor donde la clave es la página web y el valor es "1". Después de emitir un par clave-valor a Reducer, los Reducers agregan el número de para ciertas páginas web.
El resultado final será el número total de visitas de cada página web.
La función reduce luego concatena la lista de todas las URL de origen que están asociadas con la URL de destino dada y devuelve el destino y la lista de fuentes.
Resumen
Esto es todo sobre el tutorial Hadoop MapReduce. El marco procesa grandes volúmenes de datos en paralelo en todo el clúster de hardware básico. Divide el trabajo en tareas independientes y las ejecuta en paralelo en diferentes nodos del clúster.
MapReduce supera el cuello de botella del sistema empresarial tradicional. El marco funciona en los pares clave, valor. El usuario define las dos funciones que son la función de mapa y la función de reducción.
La lógica empresarial se pone en la función de mapa. El artículo había explicado varios conceptos avanzados del marco MapReduce.



