En nuestro anterior tutorial de Hadoop , hemos estudiado Hadoop Partitioner en detalle. Ahora vamos a discutir InputSplit en Hadoop MapReduce.
Aquí, cubriremos qué es Hadoop InputSplit, la necesidad de InputSplit en MapReduce. También discutiremos cómo se crean estos InputSplits en Hadoop MapReduce con gran detalle.
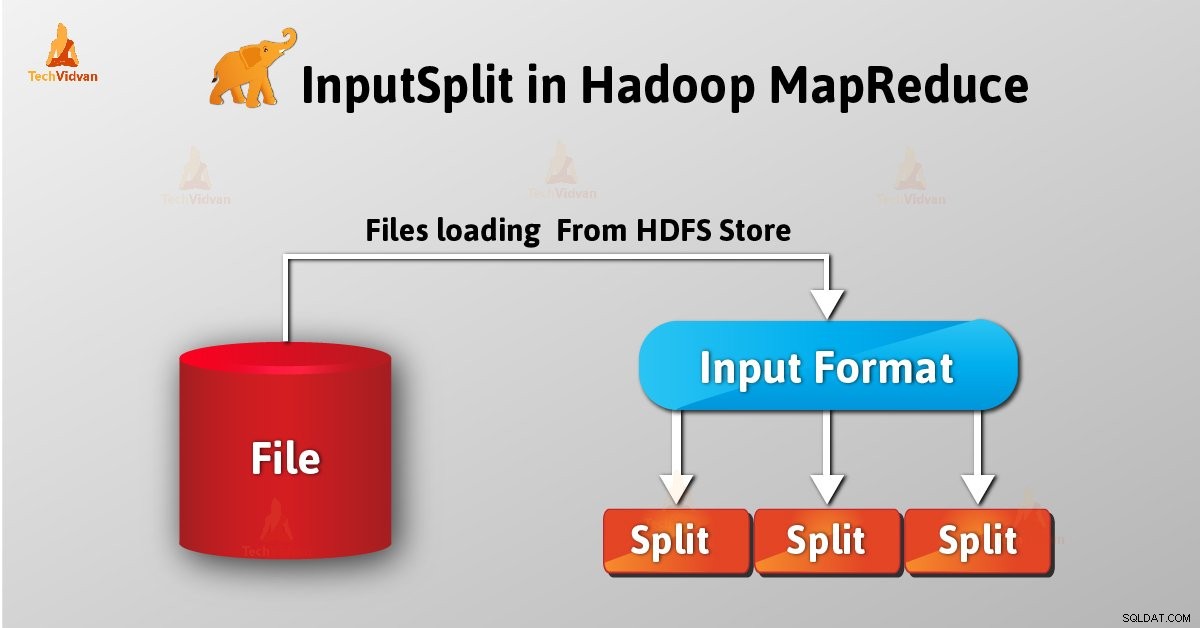
Introducción a InputSplit en Hadoop
InputSplit es la representación lógica de datos en Hadoop MapReduce. Representa los datos que el mapeador individual procesos. Por lo tanto, el número de tareas del mapa es igual al número de InputSplits. El marco divide la división en registros, que procesa el mapeador.
La longitud de MapReduce InputSplit se ha medido en bytes. Cada InputSplit tiene ubicaciones de almacenamiento (cadenas de nombre de host). El sistema MapReduce coloca las tareas del mapa lo más cerca posible de los datos de la división mediante el uso de ubicaciones de almacenamiento.
El marco procesa las tareas del mapa en el orden del tamaño de las divisiones para que la más grande se procese primero (algoritmo de aproximación codicioso). Esto minimiza el tiempo de ejecución del trabajo.
Lo principal a enfocar es que Inputsplit no contiene los datos de entrada; es solo una referencia a los datos.
¿Cómo se crean InputSplits en Hadoop MapReduce?
Como usuario, no nos ocupamos de InputSplit en Hadoop directamente, ya que InputFormat (ya que InputFormat es responsable de crear el Inputsplit y dividirlo en los registros) lo crea. FileInputFormat divide un archivo en fragmentos de 128 MB.
Además, al configurar mapred .min .dividir .tamaño parámetro en mapred-site .xml el usuario puede cambiar el valor según el requisito. También con esto podemos anular el parámetro en el objeto Job utilizado para enviar un trabajo de MapReduce en particular.
Al escribir un InputFormat personalizado, también podemos controlar cómo se divide el archivo en divisiones.
InputSplit está definido por el usuario. El usuario también puede controlar el tamaño dividido según el tamaño de los datos en el programa MapReduce. Por lo tanto, en una ejecución de trabajo de MapReduce, el número de tareas de mapa es igual al número de InputSplits.
Llamando a ‘getSplit()’ , el cliente calcula las particiones para el trabajo. Luego, se envía al maestro de aplicaciones, que usa sus ubicaciones de almacenamiento para programar tareas de mapas que los procesarán en el clúster.
Después de que la tarea del mapa pase la división a createRecordReader() método. De ahí obtiene RecordReader para la escisión. Luego, RecordReader genera un registro (par clave-valor) , que pasa a la función de mapa.
Conclusión
En conclusión, podemos decir que InputSplit representa los datos que procesa el mapeador individual. Para cada división se crea una tarea de mapa. Por lo tanto, InputFormat crea InputSplit.
Si tiene alguna consulta sobre InputSplit en MapReduce, deje un comentario en la sección que figura a continuación.



