El objetivo principal de este Tutorial de Hadoop es proporcionarle una descripción detallada de cada componente que se utiliza en el funcionamiento de Hadoop. En este tutorial, vamos a cubrir el particionador en Hadoop.
¿Qué es Hadoop Partitioner, cuál es la necesidad de Partitioner en Hadoop, cuál es el Partitioner predeterminado en MapReduce, cuántos MapReduce Partitioner se utilizan en Hadoop?
Responderemos a todas estas preguntas en este tutorial de MapReduce.
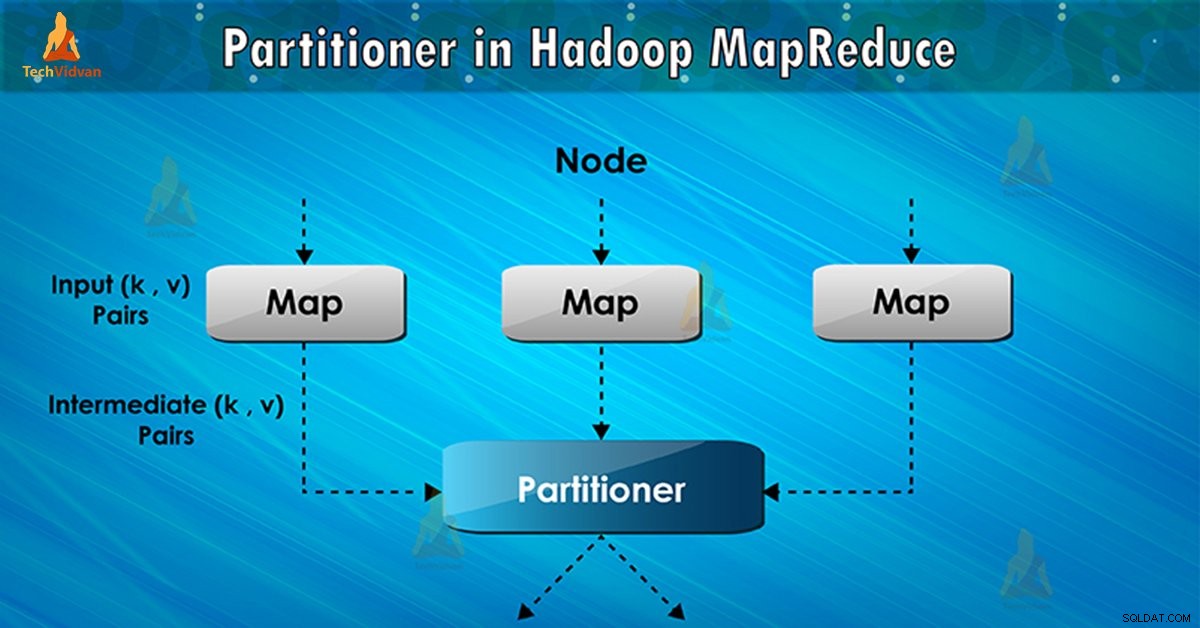
¿Qué es el particionador de Hadoop?
El particionador en la ejecución del trabajo de MapReduce controla la partición de las claves de las salidas intermedias del mapa. Con la ayuda de la función hash, la clave (o un subconjunto de la clave) deriva la partición. El número total de particiones es igual al número de tareas de reducción.
Sobre la base del valor clave , marco de particiones, cada mapeador producción. Los registros que tienen el mismo valor clave van a la misma partición (dentro de cada asignador). Luego, cada partición se envía a un reductor .
La clase de partición decide a qué partición irá un par determinado (clave, valor). La fase de partición en el flujo de datos de MapReduce tiene lugar después de la fase de mapa y antes de la fase de reducción.
Necesidad de MapReduce Partitioner en Hadoop
En la ejecución del trabajo de MapReduce, toma un conjunto de datos de entrada y produce la lista de pares de valores clave. Este par clave-valor es el resultado de la fase del mapa. En el que los datos de entrada se dividen y cada tarea procesa la división y cada mapa, genera la lista de pares de valores clave.
Luego, el marco envía la salida del mapa para reducir la tarea. Reduce procesa la función de reducción definida por el usuario en las salidas del mapa. Antes de la fase de reducción, la partición de la salida del mapa se realiza en función de la clave.
Hadoop Partitioning especifica que todos los valores de cada clave se agrupan. También se asegura de que todos los valores de una sola clave vayan al mismo reductor. Esto permite una distribución uniforme de la salida del mapa sobre el reductor.
El particionador en un trabajo de MapReduce redirige la salida del mapeador al reductor al determinar qué reductor maneja la clave en particular.
Partición predeterminada de Hadoop
Particionador hash es el particionador predeterminado. Calcula un valor hash para la clave. También asigna la partición en función de este resultado.
¿Cuántos particionadores hay en Hadoop?
El número total de particiones depende del número de reductores. Hadoop Partitioner divide los datos según el número de reductores. Lo establece JobConf.setNumReduceTasks() método.
Por lo tanto, el reductor único procesa los datos de un particionador único. Lo importante a tener en cuenta es que el marco crea un particionador solo cuando hay muchos reductores.
Particionamiento deficiente en Hadoop MapReduce
Si en la entrada de datos en el trabajo de MapReduce una tecla aparece más que cualquier otra tecla. En tal caso, para enviar datos a la partición utilizamos dos mecanismos que son los siguientes:
- La clave que aparezca más veces se enviará a una partición.
- Todas las demás claves se enviarán a las particiones en función de su hashCode() .
Si hashCode() El método no distribuye otros datos clave en el rango de partición. Entonces no se enviarán datos a los reductores.
La mala partición de datos significa que algunos reductores tendrán más entrada de datos en comparación con otros. Tendrán más trabajo que hacer que otros reductores. Por lo tanto, todo el trabajo tiene que esperar a que un reductor termine su gran parte de la carga.
¿Cómo superar la mala partición en MapReduce?
Para superar el particionador deficiente en Hadoop MapReduce, podemos crear un particionador personalizado. Esto permite compartir la carga de trabajo entre diferentes reductores.
Conclusión
En conclusión, Partitioner permite una distribución uniforme de la salida del mapa sobre el reductor. En MapReducer Partitioner, la partición de la salida del mapa se realiza en función de la clave y el valor.
Por lo tanto, hemos cubierto la descripción completa de Partitioner en este blog. Espero que les haya gustado. Si le surge alguna duda sobre Hadoop Partitioner, no olvide compartirla con nosotros.



