En nuestro blog anterior, hemos estudiado Introducción a Hadoop y Características de Hadoop , Ahora, en este blog, vamos a cubrir la función de alta disponibilidad de HDFS NameNode en detalle.
En primer lugar, hablaremos sobre la arquitectura de alta disponibilidad de HDFS NemNode, luego con la implementación de la arquitectura de alta disponibilidad de Hadoop utilizando Quorum Journal Nodes y Shared Storage.
Alta disponibilidad de NameNode de HDFS
En HDFS , los datos están altamente disponibles y son accesibles a pesar de la falla del hardware. HDFS es el sistema de almacenamiento más confiable diseñado para almacenar archivos muy grandes.
HDFS sigue la topología maestro/esclavo. En qué maestro está NameNode y los esclavos son DataNode . NameNode almacena metadatos. Los metadatos incluyen el número de bloques, su ubicación, réplicas y otros detalles. Para una recuperación más rápida de los datos, los metadatos están disponibles en el maestro. NameNode mantiene y asigna tareas al nodo esclavo.
NameNode fue el punto único de falla (SPOF) antes de Hadoop 2.0. El clúster HDFS tenía un solo NameNode. Si el NameNode falla, todo el clúster se cae.
El punto único de falla limita la alta disponibilidad de las siguientes maneras:
- Si se desencadena algún evento no planificado, como bloqueos de nodos, el clúster no estará disponible a menos que un operador reinicie el nuevo nodo de nombre.
- También las actividades de mantenimiento planificadas, como las actualizaciones de hardware en NameNode, provocarán un tiempo de inactividad del clúster de Hadoop.
Arquitectura de alta disponibilidad de HDFS NameNode
La introducción de Hadoop 2.0 supera este SPOF proporcionando soporte a múltiples NameNode. La arquitectura de alta disponibilidad de HDFS NameNode brinda la opción de ejecutar dos NameNodes redundantes en el mismo clúster en una configuración activa/pasiva con un modo de espera activo.
- Nodo de nombre activo – Maneja todas las operaciones del cliente HDFS en el clúster HDFS.
- Nodo de nombre pasivo – Es un nodo de nombre en espera. Tiene datos similares a NameNode activo.
Por lo tanto, siempre que Active NameNode falle, el pasivo NameNode asumirá toda la responsabilidad del nodo activo. Por lo tanto, el clúster HDFS continúa funcionando.
Los problemas para mantener la coherencia en el clúster de alta disponibilidad de HDFS son los siguientes:
- El NameNode activo y en espera siempre debe estar sincronizado entre sí, es decir, debe tener los mismos metadatos. Esto permite restablecer el clúster de Hadoop en el mismo estado de espacio de nombres en el que se bloqueó. Y esto nos permitirá tener una conmutación por error rápida.
- Debe haber solo un NameNode activo a la vez. De lo contrario, dos NameNode conducirán a la corrupción de los datos. A este escenario lo llamamos “Escenario de cerebro dividido ”, donde un grupo se divide en el grupo más pequeño. Cada uno cree que es el único clúster activo. El “vallado” evita tal vallado es un proceso para garantizar que solo un NameNode permanezca activo en un momento determinado.
Implementación de la arquitectura de alta disponibilidad de Hadoop
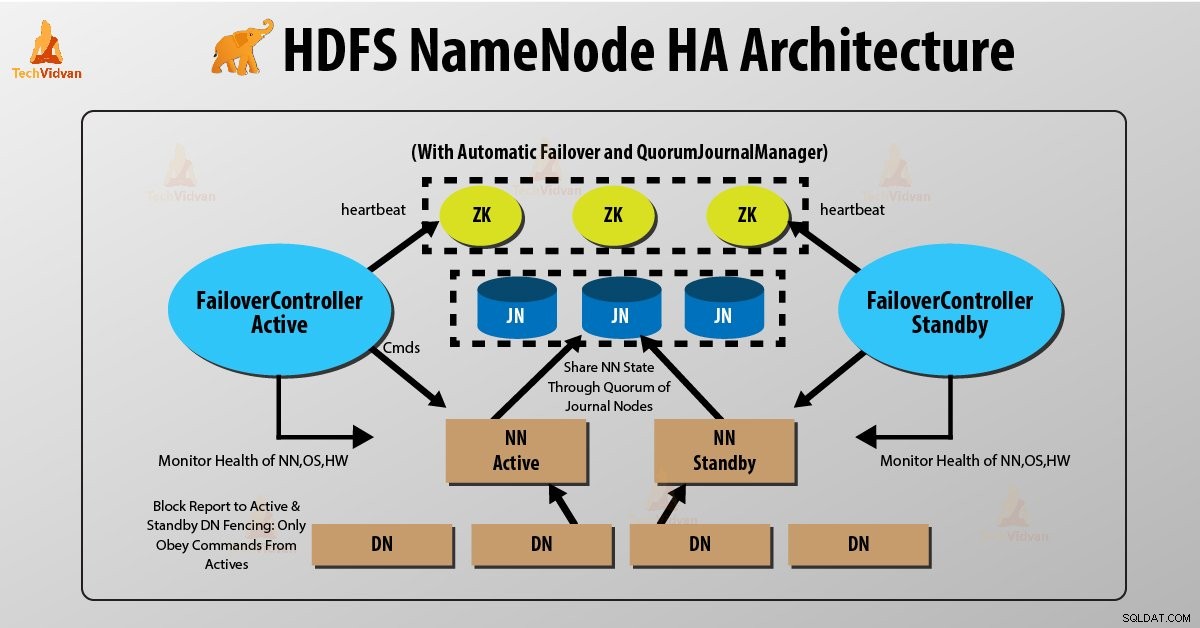
Dos NameNodes se ejecutan al mismo tiempo en la arquitectura de alta disponibilidad de HDFS NameNode. El cliente HDFS puede implementar la configuración de NameNode activo y en espera de las siguientes dos maneras:
- Uso de nodos de diario de quórum
- Uso de almacenamiento compartido
1. Uso de nodos de diario de quórum
Nodos de diario de quórum es una implementación de HDFS. QJN proporciona registros de edición. Permite compartir estos registros de edición entre el NameNode activo y en espera.
El Namenode en espera se comunica y se sincroniza con el NameNode activo para lograr una alta disponibilidad. Sucederá por un grupo de demonios llamados "Nodos de diario". Los nodos de diario de quórum se ejecutan como un grupo de nodos de diario. Debe haber al menos tres nodos de diario.
Para N nodos de diario, el sistema puede tolerar como máximo (N-1)/2 fallas. Por lo tanto, el sistema continúa funcionando. Entonces, para tres nodos de diario, el sistema puede tolerar la falla de uno {(3-1)/2} de ellos.
Cada vez que un nodo activo realiza alguna modificación, registra la modificación en todos los nodos del diario.
El nodo en espera lee las ediciones de los nodos de diario y las aplica a su propio espacio de nombres de manera constante. En el caso de una conmutación por error, el standby se asegurará de haber leído todas las ediciones de los nodos de diario antes de promoverse al estado Activo. Esto asegura que el estado del espacio de nombres esté completamente sincronizado antes de que ocurra una falla.
Para proporcionar una conmutación por error rápida, el nodo en espera debe tener información actualizada sobre la ubicación de los bloques de datos en el clúster. Para que esto suceda, la dirección IP de ambos NameNode está disponible para todos los nodos de datos y envían información de ubicación del bloque y latidos a ambos NameNode.
Vallado de NameNode
Para el correcto funcionamiento de un clúster HA, solo uno de los NameNodes debe estar activo a la vez. De lo contrario, el estado del espacio de nombres se desviaría entre los dos NameNodes. Por lo tanto, cercar es un proceso para garantizar esta propiedad en un clúster.
- Los nodos de diario realizan esta valla al permitir que solo un NameNode sea el escritor a la vez.
- El NameNode en espera asume la responsabilidad de escribir en los nodos del diario y prohíbe que cualquier otro NameNode permanezca activo.
- Finalmente, el nuevo NameNode activo puede realizar sus actividades.
2. Uso de almacenamiento compartido
El NameNode en espera y el activo se sincronizan entre sí mediante el uso de un "dispositivo de almacenamiento compartido". Para esta implementación, tanto el NameNode activo como el Namenode en espera deben tener acceso al directorio particular en el dispositivo de almacenamiento compartido (es decir, el sistema de archivos de red).
Cuando el NameNode activo realiza cualquier modificación del espacio de nombres, registra un registro de la modificación en un archivo de registro de edición almacenado en el directorio compartido. El NameNode en espera observa este directorio en busca de ediciones y, cuando se producen ediciones, el NameNode en espera las aplica a su propio espacio de nombres. En caso de falla, el NameNode en espera se asegurará de haber leído todas las ediciones del almacenamiento compartido antes de pasar al estado Activo. Esto garantiza que el estado del espacio de nombres esté completamente sincronizado antes de que ocurra la conmutación por error.
Para evitar el "escenario de cerebro dividido" en el que el estado del espacio de nombres se desvía entre los dos NameNode, un administrador debe configurar al menos un método de cercado para el almacenamiento compartido.
Conclusión
Por lo tanto, Hadoop 2.0 HDFS HA proporciona un único NameNode activo y un único NameNode en espera. Pero algunas implementaciones necesitan un alto grado de tolerancia a errores . La nueva versión 3.0 de Hadoop permite al usuario ejecutar muchos NameNodes en espera.
Por ejemplo, configurar cinco journalnodes y tres NameNode. Como resultado, el clúster Hadoop puede tolerar la falla de dos nodos en lugar de uno.
Comparta su experiencia y sugerencias relacionadas con HDFS NameNode High Availability en la sección de comentarios a continuación.



