La eficiencia de una base de datos no solo se basa en el ajuste fino de los parámetros más críticos, sino que también va más allá de la presentación adecuada de los datos en las colecciones relacionadas. Recientemente, trabajé en un proyecto que desarrolló una aplicación de chat social y, después de algunos días de prueba, notamos un retraso al obtener datos de la base de datos. No teníamos tantos usuarios, por lo que descartamos el ajuste de los parámetros de la base de datos y nos enfocamos en nuestras consultas para llegar a la causa raíz.
Para nuestra sorpresa, nos dimos cuenta de que nuestra estructura de datos no era del todo adecuada, ya que teníamos más de 1 solicitud de lectura para obtener información específica.
El modelo conceptual de cómo se colocan las secciones de la aplicación depende en gran medida de la estructura de las colecciones de la base de datos. Por ejemplo, si inicia sesión en una aplicación social, los datos se introducen en las diferentes secciones según el diseño de la aplicación como se muestra en la presentación de la base de datos.
En pocas palabras, para una base de datos bien diseñada, la estructura del esquema y las relaciones de colección son elementos clave para mejorar su velocidad e integridad, como veremos en las siguientes secciones.
Discutiremos los factores que debe considerar al modelar sus datos.
¿Qué es el modelado de datos?
El modelado de datos es generalmente el análisis de elementos de datos en una base de datos y qué tan relacionados están con otros objetos dentro de esa base de datos.
En MongoDB, por ejemplo, podemos tener una colección de usuarios y una colección de perfiles. La colección de usuarios enumera los nombres de los usuarios para una aplicación determinada, mientras que la colección de perfiles captura la configuración del perfil de cada usuario.
En el modelado de datos, necesitamos diseñar una relación para conectar a cada usuario con el perfil correspondiente. En pocas palabras, el modelado de datos es el paso fundamental en el diseño de bases de datos además de formar la base de la arquitectura para la programación orientada a objetos. También da una pista sobre cómo se verá la aplicación física durante el progreso del desarrollo. Una arquitectura de integración de aplicación y base de datos se puede ilustrar a continuación.
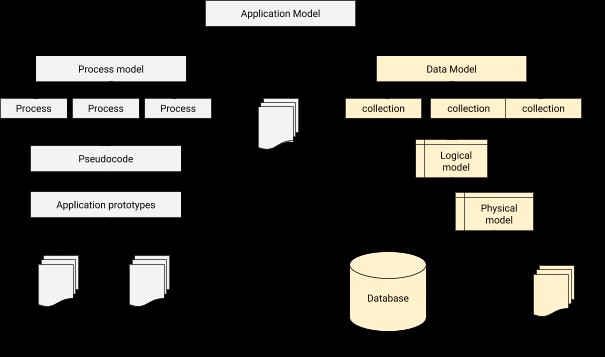
El proceso de modelado de datos en MongoDB
El modelado de datos viene con un mejor rendimiento de la base de datos, pero a expensas de algunas consideraciones que incluyen:
- Patrones de recuperación de datos
- Equilibrar necesidades de la aplicación tales como:consultas, actualizaciones y procesamiento de datos
- Características de rendimiento del motor de base de datos elegido
- La estructura inherente de los propios datos
Estructura del documento MongoDB
Los documentos en MongoDB juegan un papel importante en la toma de decisiones sobre qué técnica aplicar para un conjunto de datos dado. Generalmente hay dos relaciones entre los datos, que son:
- Datos incrustados
- Datos de referencia
Datos incrustados
En este caso, los datos relacionados se almacenan en un solo documento, ya sea como un valor de campo o como una matriz dentro del propio documento. La principal ventaja de este enfoque es que los datos se desnormalizan y, por lo tanto, brinda la oportunidad de manipular los datos relacionados en una sola operación de base de datos. En consecuencia, esto mejora la velocidad a la que se realizan las operaciones CRUD, por lo que se requieren menos consultas. Consideremos un ejemplo de un documento a continuación:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"Settings" : {
"location" : "Embassy",
"ParentPhone" : 724765986
"bus" : "KAZ 450G",
"distance" : "4",
"placeLocation" : {
"lat" : -0.376252,
"lng" : 36.937389
}
}
}En este conjunto de datos tenemos un estudiante con su nombre y alguna otra información adicional. El campo Configuración se ha incrustado con un objeto y, además, el campo placeLocation también está incrustado con un objeto con las configuraciones de latitud y longitud. Todos los datos de este estudiante se han contenido en un solo documento. Si necesitamos obtener toda la información de este estudiante, simplemente ejecutamos:
db.students.findOne({StudentName : "George Beckonn"})Fortalezas de la integración
- Mayor velocidad de acceso a los datos:para mejorar la velocidad de acceso a los datos, la incrustación es la mejor opción, ya que una sola operación de consulta puede manipular los datos dentro del documento especificado con una sola búsqueda en la base de datos.
- Reducción de la incoherencia de los datos:durante el funcionamiento, si algo sale mal (por ejemplo, una desconexión de la red o un corte de energía), solo unos pocos documentos pueden verse afectados, ya que los criterios a menudo seleccionan un solo documento.
- Operaciones CRUD reducidas. Es decir, las operaciones de lectura superan en número a las de escritura. Además, es posible actualizar datos relacionados en una sola operación de escritura atómica. Es decir, para los datos anteriores, podemos actualizar el número de teléfono y también aumentar la distancia con esta única operación:
db.students.updateOne({StudentName : "George Beckonn"}, { $set: {"ParentPhone" : 72436986}, $inc: {"Settings.distance": 1} })
Debilidades de la incrustación
- Tamaño de documento restringido. Todos los documentos en MongoDB están limitados al tamaño BSON de 16 megabytes. Por lo tanto, el tamaño total del documento junto con los datos incrustados no debe superar este límite. De lo contrario, para algunos motores de almacenamiento, como MMAPv1, los datos pueden crecer más y provocar la fragmentación de datos como resultado de un rendimiento de escritura degradado.
- Duplicación de datos:varias copias de los mismos datos dificultan la consulta de los datos replicados y puede llevar más tiempo filtrar los documentos incrustados, por lo que superan la ventaja principal de la incrustación.
Notación de puntos
La notación de puntos es la característica de identificación de los datos incrustados en la parte de programación. Se utiliza para acceder a elementos de un campo incrustado o una matriz. En los datos de muestra anteriores, podemos devolver información del estudiante cuya ubicación es "Embajada" con esta consulta usando la notación de puntos.
db.users.find({'Settings.location': 'Embassy'})Datos de referencia
La relación de datos en este caso es que los datos relacionados se almacenan en diferentes documentos, pero se emite algún enlace de referencia a estos documentos relacionados. Para los datos de muestra anteriores, podemos reconstruirlos de tal manera que:
Documento de usuario
{ "_id" : xyz,
"StudentName" : "George Beckonn",
"ParentPhone" : 075646344,
}Documento de configuración
{
"id" :xyz,
"location" : "Embassy",
"bus" : "KAZ 450G",
"distance" : "4",
"lat" : -0.376252,
"lng" : 36.937389
}Hay 2 documentos diferentes, pero están vinculados por el mismo valor para los campos _id e id. El modelo de datos está así normalizado. Sin embargo, para que podamos acceder a la información de un documento relacionado, necesitamos emitir consultas adicionales y, en consecuencia, esto se traduce en un aumento del tiempo de ejecución. Por ejemplo, si queremos actualizar ParentPhone y la configuración de distancia relacionada, tendremos al menos 3 consultas, es decir,
//fetch the id of a matching student
var studentId = db.students.findOne({"StudentName" : "George Beckonn"})._id
//use the id of a matching student to update the ParentPhone in the Users document
db.students.updateOne({_id : studentId}, {
$set: {"ParentPhone" : 72436986},
})
//use the id of a matching student to update the distance in settings document
db.students.updateOne({id : studentId}, {
$inc: {"distance": 1}
})Fortalezas de las referencias
- Coherencia de datos. Para cada documento, se mantiene una forma canónica, por lo que las posibilidades de inconsistencia de datos son bastante bajas.
- Integridad de datos mejorada. Debido a la normalización, es fácil actualizar los datos independientemente de la duración de la operación y, por lo tanto, garantizar los datos correctos para cada documento sin causar confusión.
- Utilización de caché mejorada. Los documentos canónicos a los que se accede con frecuencia se almacenan en la memoria caché en lugar de los documentos incrustados a los que se accede varias veces.
- Utilización eficiente del hardware. A diferencia de la incrustación, que puede dar lugar a que el documento supere el tamaño, la referencia no promueve el crecimiento del documento, por lo que reduce el uso del disco y de la RAM.
- Flexibilidad mejorada, especialmente con un gran conjunto de subdocumentos.
- Escrituras más rápidas.
Debilidades de las referencias
- Búsquedas múltiples:dado que tenemos que buscar en una cantidad de documentos que coincidan con los criterios, aumenta el tiempo de lectura cuando se recupera del disco. Además, esto puede resultar en errores de caché.
- Se emiten muchas consultas para lograr alguna operación, por lo que los modelos de datos normalizados requieren más viajes de ida y vuelta al servidor para completar una operación específica.
Normalización de datos
La normalización de datos se refiere a la reestructuración de una base de datos de acuerdo con algunas formas normales para mejorar la integridad de los datos y reducir los eventos de redundancia de datos.
El modelado de datos gira en torno a 2 técnicas principales de normalización que son:
-
Modelos de datos normalizados
Tal como se aplica en los datos de referencia, la normalización divide los datos en varias colecciones con referencias entre las nuevas colecciones. Se emitirá una única actualización de documento a la otra colección y se aplicará en consecuencia al documento coincidente. Esto proporciona una representación de actualización de datos eficiente y se usa comúnmente para datos que cambian con bastante frecuencia.
-
Modelos de datos desnormalizados
Los datos contienen documentos incrustados, lo que hace que las operaciones de lectura sean bastante eficientes. Sin embargo, está asociado con un mayor uso de espacio en disco y también con dificultades para mantenerse sincronizado. El concepto de desnormalización se puede aplicar bien a subdocumentos cuyos datos no cambian muy a menudo.
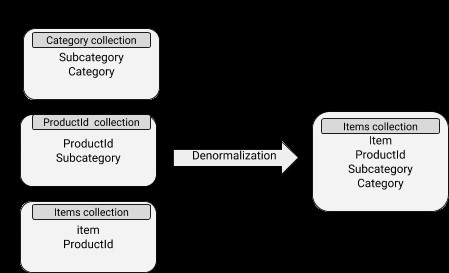
Esquema MongoDB
Un esquema es básicamente un esqueleto delineado de campos y tipos de datos que cada campo debe contener para un conjunto de datos determinado. Teniendo en cuenta el punto de vista de SQL, todas las filas están diseñadas para tener las mismas columnas y cada columna debe contener el tipo de datos definido. Sin embargo, en MongoDB, tenemos un esquema flexible por defecto que no tiene la misma conformidad para todos los documentos.
Esquema flexible
Un esquema flexible en MongoDB define que los documentos no necesariamente deben tener los mismos campos o tipos de datos, ya que un campo puede diferir entre documentos dentro de una colección. La principal ventaja de este concepto es que se pueden agregar nuevos campos, eliminar los existentes o cambiar los valores de los campos a un nuevo tipo y, por lo tanto, actualizar el documento a una nueva estructura.
Por ejemplo podemos tener estos 2 documentos en la misma colección:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"ParentPhone" : 75646344,
"age" : 10
}
{ "_id" : ObjectId("5b98bfe7e8b9ab98757e8b9a"),
"StudentName" : "Fredrick Wesonga",
"ParentPhone" : false,
}En el primer documento, tenemos un campo de edad, mientras que en el segundo documento no hay ningún campo de edad. Además, el tipo de datos para el campo ParentPhone es un número, mientras que en el segundo documento se ha configurado como falso, que es un tipo booleano.
La flexibilidad del esquema facilita la asignación de documentos a un objeto y cada documento puede coincidir con los campos de datos de la entidad representada.
Esquema rígido
Por mucho que hayamos dicho que estos documentos pueden diferir entre sí, a veces puede decidir crear un esquema rígido. Un esquema rígido definirá que todos los documentos de una colección compartirán la misma estructura y esto le dará una mejor oportunidad de establecer algunas reglas de validación de documentos como una forma de mejorar la integridad de los datos durante las operaciones de inserción y actualización.
Tipos de datos de esquema
Al usar algunos controladores de servidor para MongoDB, como mongoose, se proporcionan algunos tipos de datos que le permiten realizar la validación de datos. Los tipos de datos básicos son:
- Cadena
- Número
- Booleano
- Fecha
- Búfer
- Id. de objeto
- matriz
- Mixto
- Decimal128
- Mapa
Eche un vistazo al esquema de muestra a continuación
var userSchema = new mongoose.Schema({
userId: Number,
Email: String,
Birthday: Date,
Adult: Boolean,
Binary: Buffer,
height: Schema.Types.Decimal128,
units: []
});Ejemplo de caso de uso
var user = mongoose.model(‘Users’, userSchema )
var newUser = new user;
newUser.userId = 1;
newUser.Email = “example@sqldat.com”;
newUser.Birthday = new Date;
newUser.Adult = false;
newUser.Binary = Buffer.alloc(0);
newUser.height = 12.45;
newUser.units = [‘Circuit network Theory’, ‘Algerbra’, ‘Calculus’];
newUser.save(callbackfunction);Validación de esquema
Por mucho que pueda hacer la validación de datos desde el lado de la aplicación, siempre es una buena práctica hacer la validación también desde el lado del servidor. Logramos esto empleando las reglas de validación del esquema.
Estas reglas se aplican durante las operaciones de inserción y actualización. Se declaran sobre una base de colección durante el proceso de creación normalmente. Sin embargo, también puede agregar las reglas de validación de documentos a una colección existente usando el comando collMod con opciones de validación, pero estas reglas no se aplican a los documentos existentes hasta que se les aplica una actualización.
Del mismo modo, al crear una nueva colección con el comando db.createCollection(), puede emitir la opción de validación. Eche un vistazo a este ejemplo al crear una colección para estudiantes. Desde la versión 3.6, MongoDB admite la validación del esquema JSON, por lo tanto, todo lo que necesita es usar el operador $jsonSchema.
db.createCollection("students", {
validator: {$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "gpa" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
gender: {
bsonType: "string",
description: "must be a string and is not required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
exclusiveMaximum: false,
description: "must be an integer in [ 2017, 2020 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
minimum: 0,
description: "must be a double and is required"
}
}
}})En este diseño de esquema, si intentamos insertar un nuevo documento como:
db.students.insert({
name: "James Karanja",
year: NumberInt(2016),
major: "History",
gpa: NumberInt(3)
})La función de devolución de llamada devolverá el error a continuación, debido a que se violaron algunas reglas de validación, como que el valor del año proporcionado no está dentro de los límites especificados.
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 121,
"errmsg" : "Document failed validation"
}
})Además, puede agregar expresiones de consulta a su opción de validación usando operadores de consulta excepto $where, $text, near y $nearSphere, es decir:
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )Niveles de validación de esquema
Como se mencionó anteriormente, la validación se emite normalmente para las operaciones de escritura.
Sin embargo, la validación también se puede aplicar a documentos ya existentes.
Hay 3 niveles de validación:
- Estricto:este es el nivel de validación predeterminado de MongoDB y aplica reglas de validación a todas las inserciones y actualizaciones.
- Moderado:las reglas de validación se aplican durante las inserciones, actualizaciones y a documentos ya existentes que cumplen únicamente los criterios de validación.
- Desactivado:este nivel establece las reglas de validación para un esquema determinado como nulo, por lo que no se realizará ninguna validación en los documentos.
Ejemplo:
Insertemos los datos a continuación en una colección de clientes.
db.clients.insert([
{
"_id" : 1,
"name" : "Brillian",
"phone" : "+1 778 574 666",
"city" : "Beijing",
"status" : "Married"
},
{
"_id" : 2,
"name" : "James",
"city" : "Peninsula"
}
]Si aplicamos el nivel de validación moderado usando:
db.runCommand( {
collMod: "test",
validator: { $jsonSchema: {
bsonType: "object",
required: [ "phone", "name" ],
properties: {
phone: {
bsonType: "string",
description: "must be a string and is required"
},
name: {
bsonType: "string",
description: "must be a string and is required"
}
}
} },
validationLevel: "moderate"
} )Las reglas de validación se aplicarán solo al documento con _id de 1, ya que coincidirá con todos los criterios.
Para el segundo documento, dado que las reglas de validación no se cumplen con los criterios emitidos, el documento no será validado.
Acciones de validación de esquema
Después de hacer la validación de los documentos, puede haber algunos que violen las reglas de validación. Siempre es necesario proporcionar una acción cuando esto sucede.
MongoDB proporciona dos acciones que se pueden emitir a los documentos que fallan las reglas de validación:
- Error:esta es la acción predeterminada de MongoDB, que rechaza cualquier inserción o actualización en caso de que viole los criterios de validación.
-
Advertencia:esta acción registrará la infracción en el registro de MongoDB, pero permite que se complete la operación de inserción o actualización. Por ejemplo:
db.createCollection("students", { validator: {$jsonSchema: { bsonType: "object", required: [ "name", "gpa" ], properties: { name: { bsonType: "string", description: "must be a string and is required" }, gpa: { bsonType: [ "double" ], minimum: 0, description: "must be a double and is required" } } }, validationAction: “warn” })Si intentamos insertar un documento como este:
db.students.insert( { name: "Amanda", status: "Updated" } );Falta el gpa independientemente del hecho de que es un campo obligatorio en el diseño del esquema, pero dado que la acción de validación se ha configurado para advertir, el documento se guardará y se registrará un mensaje de error en el registro de MongoDB.



