Explore la arquitectura de Hadoop, que es el marco más adoptado para almacenar y procesar datos masivos.
En este artículo, estudiaremos la Arquitectura Hadoop. El artículo explica la arquitectura Hadoop y los componentes de la arquitectura Hadoop que son HDFS, MapReduce e YARN. En el artículo, exploraremos la arquitectura de Hadoop en detalle, junto con el diagrama de la arquitectura de Hadoop.
Comencemos ahora con Hadoop Architecture.
Arquitectura Hadoop
El objetivo de diseñar Hadoop es desarrollar un marco económico, confiable y escalable que almacene y analice los crecientes grandes datos.
Apache Hadoop es un marco de software diseñado por Apache Software Foundation para almacenar y procesar grandes conjuntos de datos de diferentes tamaños y formatos.
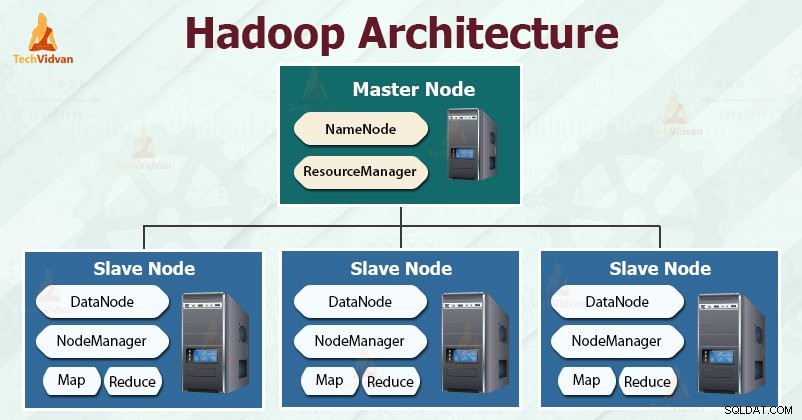
Hadoop sigue al maestro-esclavo arquitectura para almacenar y procesar eficazmente grandes cantidades de datos. Los nodos maestros asignan tareas a los nodos esclavos.
Los nodos esclavos son responsables de almacenar los datos reales y realizar el cálculo/procesamiento real. Los nodos maestros son responsables de almacenar los metadatos y administrar los recursos en todo el clúster.
Los nodos esclavos almacenan los datos comerciales reales, mientras que el maestro almacena los metadatos.
La arquitectura de Hadoop consta de tres capas. Ellos son:
- Capa de almacenamiento (HDFS)
- Capa de gestión de recursos (YARN)
- Capa de procesamiento (MapReduce)
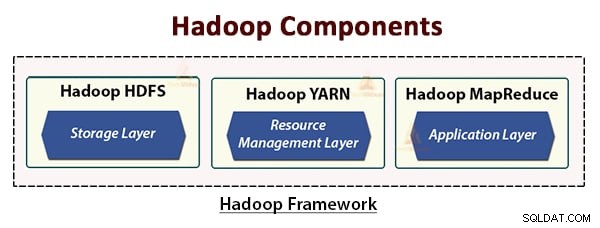
HDFS, YARN y MapReduce son los componentes principales de Hadoop Framework.
Estudiemos ahora estos tres componentes principales en detalle.
1. HDFS
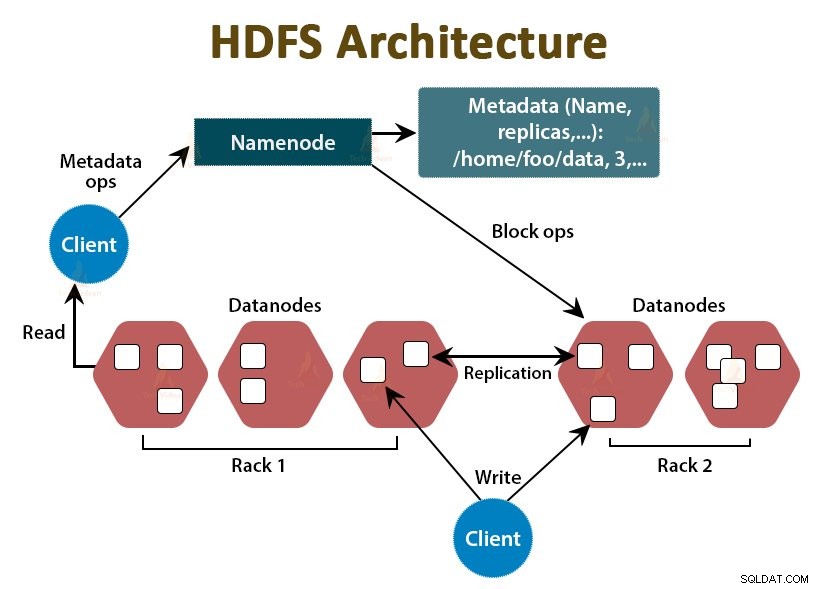
HDFS es el Sistema de archivos distribuidos de Hadoop , que se ejecuta en hardware básico económico. Es la capa de almacenamiento de Hadoop. Los archivos en HDFS se dividen en fragmentos del tamaño de un bloque denominados bloques de datos.
Estos bloques luego se almacenan en los nodos esclavos en el clúster. El tamaño del bloque es de 128 MB por defecto, que podemos configurar según nuestros requisitos.
Al igual que Hadoop, HDFS también sigue la arquitectura maestro-esclavo. Comprende dos demonios:NameNode y DataNode. NameNode es el demonio maestro que se ejecuta en el nodo maestro. Los DataNodes son el demonio esclavo que se ejecuta en los nodos esclavos.
NombreNodo
NameNode almacena los metadatos del sistema de archivos, es decir, nombres de archivos, información sobre bloques de un archivo, ubicaciones de bloques, permisos, etc. Administra los Datanodes.
Nodo de datos
DataNodes son los nodos esclavos que almacenan los datos comerciales reales. Atiende las solicitudes de lectura/escritura del cliente según las instrucciones de NameNode.
DataNodes almacena los bloques de los archivos y NameNode almacena los metadatos como ubicaciones de bloques, permisos, etc.
2. MapaReducir
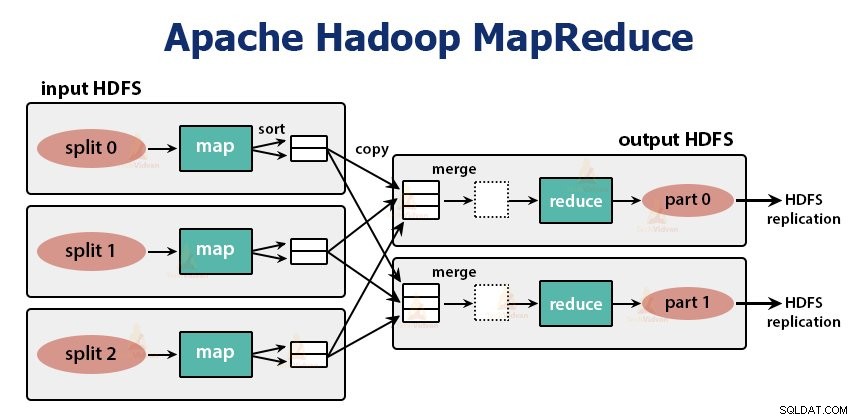
Es la capa de procesamiento de datos de Hadoop. Es un marco de software para escribir aplicaciones que procesan grandes cantidades de datos (terabytes a petabytes en el rango) en paralelo en el clúster de hardware básico.
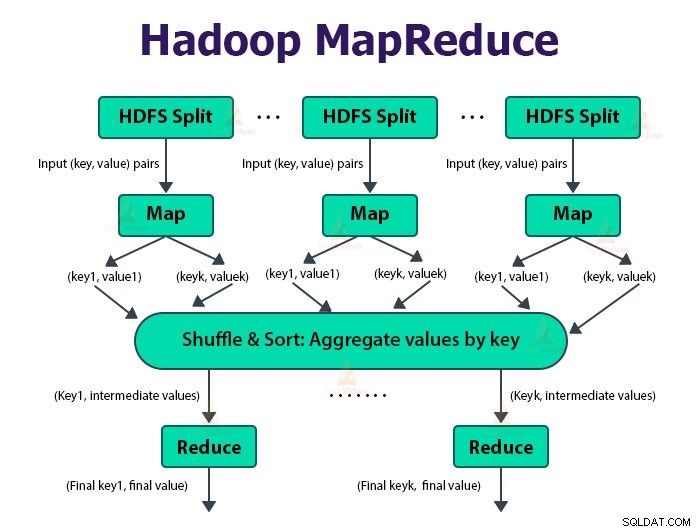
El marco MapReduce funciona en los pares
El trabajo de MapReduce es la unidad de trabajo que el cliente desea realizar. El trabajo de MapReduce consiste principalmente en los datos de entrada, el programa MapReduce y la información de configuración. Hadoop ejecuta los trabajos de MapReduce dividiéndolos en dos tipos de tareas que son tareas de mapa y reducir tareas . Hadoop YARN programó estas tareas y se ejecutan en los nodos del clúster.
Debido a algunas condiciones desfavorables, si las tareas fallan, se reprogramarán automáticamente en un nodo diferente.
El usuario define la función de mapa y la función de reducción para realizar el trabajo de MapReduce.
La entrada a la función map y la salida de la función reduce es el par clave-valor.
La función de las tareas del mapa es cargar, analizar, filtrar y transformar los datos. La salida de la tarea map es la entrada de la tarea reduce. Reducir la tarea luego realiza la agrupación y agregación en la salida de la tarea del mapa.
La tarea MapReduce se realiza en dos fases-
1. Fase del mapa
Hadoop divide las entradas del trabajo de MapReduce en divisiones de tamaño fijo denominadas divisiones de entrada. o divisiones. RecordReader transforma estas divisiones en registros y analiza los datos en registros, pero no analiza los registros en sí. Lector de registros proporciona los datos a la función del mapeador en pares clave-valor.
En la fase de mapa, Hadoop crea una tarea de mapa que ejecuta una función definida por el usuario llamada función de mapa para cada registro en la división de entrada. Genera cero o múltiples pares clave-valor intermedios como resultado de la tarea del mapa.
La tarea de mapa escribe su salida en el disco local. Esta salida intermedia luego es procesada por las tareas de reducción que ejecutan una función de reducción definida por el usuario para producir la salida final. Una vez que se completa el trabajo, la salida del mapa se elimina.
La entrada a la tarea de reducción única es la salida de todos los mapeadores que es la salida de todas las tareas de mapa. Hadoop permite al usuario definir una función combinadora que se ejecuta en la salida del mapa.
Combinador agrupa los datos en la fase del mapa antes de pasarlos a Reducer. Combina la salida de la función map que luego se pasa como entrada a la función reduce.
Cuando hay varios reductores, las tareas del mapa dividen su salida, cada una de las cuales crea una partición para cada tarea de reducción. En cada partición, puede haber muchas claves y sus valores asociados, pero los registros de cualquier clave dada están todos en una única partición.
Hadoop permite a los usuarios controlar la partición especificando una función de partición definida por el usuario. Por lo general, hay un particionador predeterminado que almacena las claves mediante la función hash.
2. Reducir fase:
Las diversas fases en la tarea de reducción son las siguientes:
La tarea Reducer comienza con un paso de barajar y ordenar. El objetivo principal de esta fase es reunir las claves equivalentes. La fase Ordenar y mezclar descarga los datos escritos por el particionador en el nodo donde se está ejecutando Reducer.
Ordena cada pieza de datos en una gran lista de datos. El marco MapReduce realiza este tipo y baraja para que podamos iterarlo fácilmente en la tarea de reducción.
La clasificación y barajado son realizados por el marco de forma automática. El desarrollador, a través del objeto comparador, puede controlar cómo se ordenan y agrupan las claves.
El Reductor, que es la función de reducción definida por el usuario, se realiza una vez por agrupación de teclas. El reductor filtra, agrega y combina datos de varias maneras diferentes. Una vez que se completa la tarea de reducción, proporciona cero o más pares clave-valor a OutputFormat. La salida de la tarea de reducción se almacena en Hadoop HDFS.
Toma la salida del reductor y la escribe en el archivo HDFS mediante RecordWriter. Por defecto, separa la clave, el valor por una pestaña y cada registro por un carácter de nueva línea.
3. HILO
YARN significa Otro negociador de recursos más . Es la capa de gestión de recursos de Hadoop. Fue introducido en Hadoop 2.
YARN está diseñado con la idea de dividir las funcionalidades de programación de trabajos y administración de recursos en demonios separados. La idea básica es tener un Administrador de recursos global y un Maestro de aplicaciones por aplicación donde la aplicación puede ser un solo trabajo o DAG de trabajos.
YARN consta de ResourceManager, NodeManager y ApplicationMaster por aplicación.
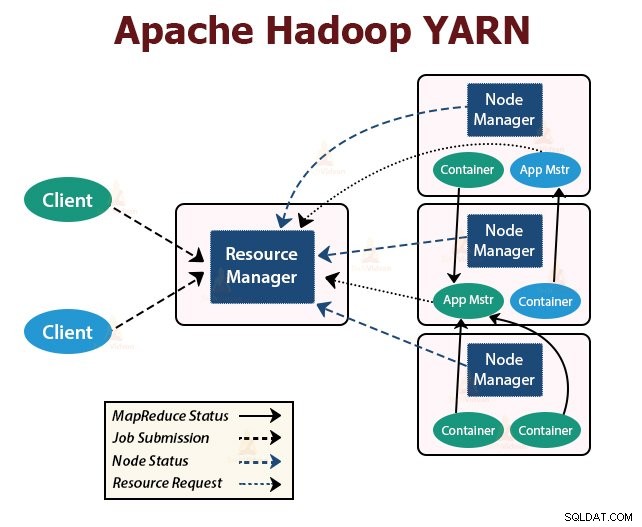
1. Administrador de recursos
Arbitra los recursos entre todas las aplicaciones del clúster.
Tiene dos componentes principales que son Scheduler y ApplicationManager.
- El programador asigna recursos a las distintas aplicaciones que se ejecutan en el clúster, teniendo en cuenta las capacidades, las colas, etc.
- Es un Planificador puro. No supervisa ni rastrea el estado de la aplicación.
- Scheduler no garantiza el reinicio de las tareas fallidas debido a una falla de la aplicación o una falla del hardware.
- Realiza la programación en función de los requisitos de recursos de las aplicaciones.
- Son responsables de aceptar las presentaciones de trabajo.
- ApplicationManager negocia el primer contenedor para ejecutar ApplicationMaster específico de la aplicación.
- Proporcionan servicio para reiniciar el contenedor de ApplicationMaster en caso de falla.
- El ApplicationMaster por aplicación es responsable de negociar contenedores desde el Programador. Realiza un seguimiento y supervisa su estado y progreso.
2. Administrador de nodos:
NodeManager se ejecuta en los nodos esclavos. Es responsable de los contenedores, monitorea el uso de recursos de la máquina que es CPU, memoria, disco, uso de la red y reporta lo mismo al ResourceManager o Scheduler.
3. Maestro de aplicaciones:
El ApplicationMaster por aplicación es una biblioteca específica del marco. Es responsable de negociar los recursos desde el ResourceManager. Funciona con NodeManager(s) para ejecutar y monitorear las tareas.
Resumen
En este artículo, hemos estudiado la arquitectura de Hadoop. Hadoop sigue la topología maestro-esclavo. Los nodos maestros asignan tareas a los nodos esclavos. La arquitectura comprende tres capas que son HDFS, YARN y MapReduce.
HDFS es el sistema de archivos distribuido en Hadoop para almacenar grandes datos. MapReduce es el marco de procesamiento para procesar grandes datos en el clúster de Hadoop de manera distribuida. YARN es responsable de administrar los recursos entre las aplicaciones en el clúster.
El demonio de HDFS NameNode y el demonio de YARN ResourceManager se ejecutan en el nodo maestro en el clúster de Hadoop. El demonio HDFS DataNode y YARN NodeManager se ejecutan en los nodos esclavos.
HDFS y el marco MapReduce se ejecutan en el mismo conjunto de nodos, lo que da como resultado un ancho de banda agregado muy alto en todo el clúster.
¡¡Sigue Aprendiendo!!



