Cuando instala ClusterControl, tiene una configuración predeterminada que tal vez no se ajuste a sus requisitos, por lo que probablemente deba personalizar esta instalación. Para esto, puede modificar los archivos de configuración, pero también puede verificar o modificar la configuración de ClusterControl en tiempo de ejecución. En este blog, le mostraremos dónde puede ver esta configuración y cuáles son las opciones disponibles para usar aquí.
¿Dónde se puede ver la configuración del tiempo de ejecución de ClusterControl?
Hay dos formas diferentes de verificar esto. Primero, puede ir a ClusterControl -> Configuración global -> Configuraciones de tiempo de ejecución, luego elija su clúster.
Otra forma es ClusterControl -> Seleccionar clúster -> Configuración -> Configuraciones de tiempo de ejecución .
En ambos casos, irá al mismo lugar, la configuración de tiempo de ejecución sección.
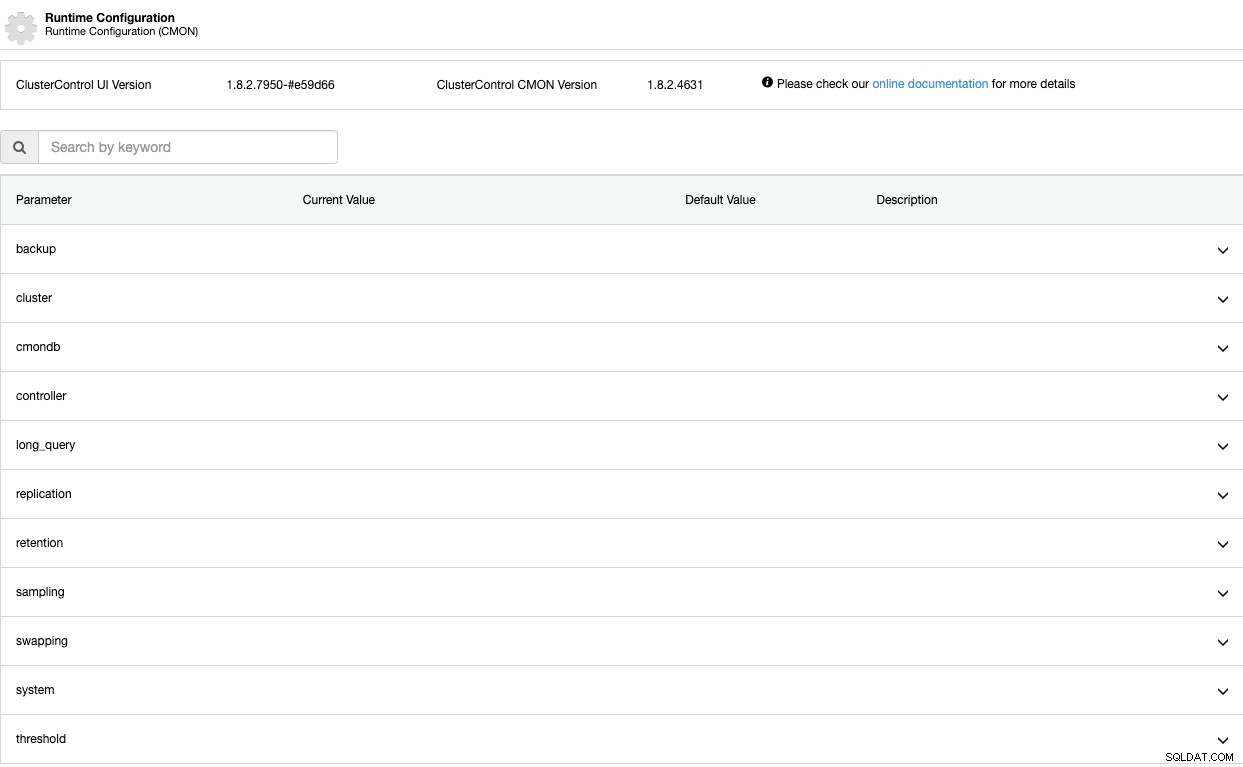
Parámetros de configuración de tiempo de ejecución
Ahora, veamos estos parámetros uno por uno. Tenga en cuenta que estos parámetros dependen de la tecnología de la base de datos que esté utilizando, por lo que lo más probable es que no los vea todos al mismo tiempo en el mismo clúster.
Copia de seguridad
| Nombre | Valor predeterminado | Descripción |
|---|---|---|
| deshabilitar_backup_email | falso | Esta configuración controla si los correos electrónicos se envían o no si una copia de seguridad finaliza o falla. |
| usuario_de_respaldo | usuario de respaldo | El nombre de usuario de la cuenta de la base de datos utilizada para administrar las copias de seguridad. |
| backup_create_hash | verdadero | Configura ClusterControl si tiene que calcular md5hash en los archivos de respaldo creados y verificarlos. |
| pitr_retention_hours | 0 | Horas de retención (para borrar registros de archivo WAL antiguos) para PITR. |
| puerto_netcat | 9999,9990-9998 | Lista de puertos Netcat y rangos de puertos utilizados para transmitir copias de seguridad. Los valores predeterminados son '9999,9990-9998' y se preferirá el puerto 9999 si está disponible. |
| dirección de copia de seguridad | /inicio/usuario/copias de seguridad | El directorio de copia de seguridad predeterminado, que se completará previamente en Frontend. |
| backup_subdir | RESPALDO-%I | Establezca el nombre del subdirectorio de copia de seguridad. Esta cadena puede contener separadores de campo estándar "%X", el "%06I", por ejemplo, será reemplazado por el ID numérico de la copia de seguridad en formato de 6 campos que usa '0' como caracteres de relleno iniciales. Esta es la lista de campos que admite actualmente el backend:- B La fecha y la hora en que comenzó la creación de la copia de seguridad. - H El nombre del host de respaldo, el host que creó el respaldo. - i El ID numérico del clúster. - I El ID numérico de la copia de seguridad. - J El ID numérico del trabajo que creó la copia de seguridad. - M El método de copia de seguridad (por ejemplo, "mysqldump"). - O El nombre del usuario que inició el trabajo de copia de seguridad. - S El nombre del host de almacenamiento, el host que almacena los archivos de copia de seguridad. - % El propio signo de porcentaje. Use signos de dos por ciento, "%%" de la misma manera que la función printf() estándar lo interpreta como un signo de uno por ciento. |
| backup_retention | 31 | La configuración de cuántos días mantener las copias de seguridad. Se eliminan las copias de seguridad que coinciden con el período de retención. |
| backup_cloud_retention | 180 | La configuración de cuántos días mantener las copias de seguridad cargadas en una nube. Se eliminan las copias de seguridad que coinciden con el período de retención. |
| backup_n_safety_copies | 1 | La configuración de cuántas copias de seguridad completas se mantendrán independientemente de su estado de retención. |
Clúster
| Nombre | Valor predeterminado | Descripción |
|---|---|---|
| nombre_del_clúster | El nombre del clúster para una fácil identificación. | |
| habilitar_nodo_recuperación automática | verdadero | Configuración de recuperación automática de nodo. |
| habilitar_clúster_recuperación automática | verdadero | Si es verdadero, ClusterControl realizará la recuperación automática del clúster; si es falso, no se realizará ninguna recuperación del clúster automáticamente. |
| dirección de configuración | /etc/ | El directorio de configuración del servidor de la base de datos. |
| creado_por_trabajo | El ID del trabajo que creó este clúster. | |
| ssh_keypath | /home/usuario/.ssh/id_rsa | El archivo de clave SSH utilizado para la conexión a los nodos. |
| selección_servidor_intentar_una vez | verdadero | Opción URI de conexión MongoDB. Define si la selección del servidor debe repetirse en caso de falla hasta que expire el tiempo de espera de la selección del servidor, o simplemente regresar con la falla de inmediato. |
| server_selection_timeout_ms | 30000 | Opción URI de conexión MongoDB. Define el valor de tiempo de espera hasta que mongodriver intente realizar una operación de selección de servidor exitosa. |
| propietario | El ID de usuario de ClusterControl del propietario del objeto de clúster. | |
| propietario_del_grupo | El ID de grupo de ClusterControl del grupo propietario del objeto de clúster. | |
| ruta_cdt | La ubicación del objeto de clúster en el árbol de directorios de ClusterControl. | |
| etiquetas | / | Un conjunto de cadenas que el usuario puede especificar. |
| acl | La lista de control de acceso como una cadena que controla el acceso al objeto del clúster. | |
| usuario_mongodb | admindb | El nombre de usuario de MongoDB. |
| mongodb_basedir | /usr/ | El directorio base para la instalación de MongoDB. |
| mysql_basedir | /usr/ | El directorio base para la instalación de MySQL. |
| scriptdir | /usr/bin/ | El directorio de scripts de instalación de MySQL. |
| staging_dir | /home/usuario/s9s_tmp | Una ruta de preparación para archivos temporales. |
| bindir | /usr/bin | El directorio /bin de la instalación de MySQL. |
| puerto_mysql_monitorizado | 3306 | El número de puerto del servidor MySQL monitoreado. |
| ndb_cadena de conexión | 127.0.0.1:1186 | La configuración de cadena de conexión NDB para MySQL Cluster. |
| ndbd_datadir | El directorio de datos de los nodos NDBD. | |
| mgmd_datadir | El directorio de datos de los nodos NDB MGMD. | |
| usuario_os | El nombre de usuario SSH utilizado para acceder a los nodos. | |
| repl_usuario | cmon_replication | El nombre de usuario de replicación. |
| proveedor | El nombre del proveedor de la base de datos utilizado para las implementaciones. | |
| versión_galera | El número de versión de Galera usado. | |
| versión_servidor | La versión del servidor de la base de datos utilizada para las implementaciones. | |
| usuario_postgresql | admindb | El nombre de usuario de PostgreSQL. |
| puerto_galera | 4567 | El puerto galera que se usará al agregar nodos/garbd y construir wsrep_cluster_address. No cambie en tiempo de ejecución. |
| auto_manage_readonly | verdadero | Permitir que ClusterControl administre el indicador de solo lectura de los servidores MySQL administrados. |
| archivo_bloqueo_recuperación_nodo | Especifique un archivo de bloqueo y, si está presente en un nodo, el nodo no se recuperará. Es responsabilidad del administrador crear/eliminar el archivo. |
Cmondb
| Nombre | Valor predeterminado | Descripción |
|---|---|---|
| cmon_db | vamos | El nombre de la base de datos local de ClusterControl. |
| cmondb_hostname | 127.0.0.1 | El nombre de host del servidor MySQL de la base de datos local de ClusterControl. |
| puerto_mysql | 3306 | El puerto del servidor MySQL de la base de datos local de ClusterControl. |
| cmon_user | vamos | El nombre de la cuenta para acceder a la base de datos local de ClusterControl. |
Controlador
| Nombre | Valor predeterminado | Descripción |
|---|---|---|
| id_controlador | 5a3a993d-xxxx | Una cadena de identificación arbitraria de esta instancia de controlador. |
| cmon_hostname | 192.168.xx.xx | El nombre de host del controlador. |
| dir_informe_error | /home/usuario/s9s_tmp | Ubicación de almacenamiento de informes de error. |
Consulta_larga
| Nombre | Valor predeterminado | Descripción |
|---|---|---|
| long_query_time | 0.5 | Valor de umbral para verificación de consulta lenta. |
| query_monitor_alert_long_running_query | verdadero | Genera una alarma si una consulta se ejecuta durante más de query_monitor_long_running_query_ms. |
| query_monitor_kill_long_running_query | falso | Elimine la consulta si la consulta se ejecutó durante más de query_monitor_long_running_query_ms. |
| query_monitor_long_running_query_time_ms | 30000 | Genera una alarma si una consulta se ejecuta durante más tiempo que query_monitor_long_running_query_ms. El valor mínimo es 1000. |
| query_monitor_long_running_query_matching_info | Coincide solo consultas con una 'Información' que solo coincide con esta expresión regular POSIX. Sin valor predeterminado, coincide con cualquier información. | |
| query_monitor_long_running_query_matching_info_negate | falso | Niega el resultado de query_monitor_long_running_query_matching_info. |
| query_monitor_long_running_query_matching_host | Coincide solo consultas con un 'Host' que solo coincide con esta expresión regular POSIX. Sin valor predeterminado, coincide con cualquier Host. | |
| query_monitor_long_running_query_matching_db | Coincide solo consultas con un 'Db' que solo coincide con esta expresión regular POSIX. Sin valor predeterminado, coincide con cualquier base de datos. | |
| query_monitor_long_running_query_matching_user | Coincide solo consultas con un 'Usuario' que solo coincide con esta expresión regular POSIX. Sin valor predeterminado, coincide con cualquier usuario. | |
| query_monitor_long_running_query_matching_user_negate | falso | Niega el resultado de query_monitor_long_running_query_matching_user. |
| query_monitor_long_running_query_matching_command | Consulta | Coincide solo consultas con un 'Comando' que solo coincide con esta expresión regular POSIX. El valor predeterminado es 'Consulta'. |
Replicación
| Nombre | Valor predeterminado | Descripción |
|---|---|---|
| max_replication_lag | 10 | Retraso de replicación máximo permitido en segundos antes de enviar una alarma. |
| detención_de_replicación_en_error | verdadero | Controla si los procedimientos de failover/switchover deben fallar si se encuentran errores que pueden causar la pérdida de datos. |
| esclavo_de_reconstrucción_automática_de_replicación | falso | Si se detiene SQL THREAD y el código de error no es cero, el esclavo se reconstruirá automáticamente. |
| replication_failover_blacklist | Lista separada por comas de nombres de host:pares de puertos. Los servidores incluidos en la lista negra no se considerarán candidatos durante la conmutación por error. replication_failover_blacklist se ignora si se establece replication_failover_whitelist. | |
| replication_failover_whitelist | Lista separada por comas de nombres de host:pares de puertos. Solo los servidores incluidos en la lista blanca se considerarán candidatos durante la conmutación por error. Si ningún servidor en la lista blanca está disponible (activo/conectado), la conmutación por error fallará. replication_failover_blacklist se ignora si se establece replication_failover_whitelist. | |
| secuencia de comandos de replicación_onfail_failover_ | Este script se ejecuta tan pronto como se descubre que se necesita una conmutación por error. Si el script devuelve un valor distinto de cero o no existe, se anulará la conmutación por error. Se proporcionan cuatro argumentos a la secuencia de comandos y se configuran si se conocen; de lo contrario, están vacíos:arg1='todos los servidores' arg2='maestro fallido' arg3='candidato seleccionado', arg4='esclavos del antiguo maestro (los candidatos)' y se pasan como esto:'scriptname arg1 arg2 arg3 arg4' El script debe ser accesible en el controlador y ejecutable. | |
| secuencia de comandos_pre_failover_replication_pre_failover | Este script se ejecuta antes de que ocurra la conmutación por error, pero después de que se haya elegido un candidato, es posible continuar con el proceso de conmutación por error. Si el script devuelve un valor distinto de cero o no existe, se anulará la conmutación por error. Se proporcionan cuatro argumentos a la secuencia de comandos y se configuran si se conocen; de lo contrario, están vacíos:arg1='todos los servidores' arg2='maestro fallido' arg3='candidato seleccionado', arg4='esclavos del antiguo maestro (los candidatos)' y se pasan como esto:'scriptname arg1 arg2 arg3 arg4' El script debe ser accesible en el controlador y ejecutable. | |
| script_post_failover_de_replicación | Este script se ejecuta después de que ocurre la conmutación por error (se elige un nuevo maestro y se ejecuta). Si el script devuelve un valor distinto de cero o no existe, se anulará la conmutación por error. Se proporcionan cuatro argumentos a la secuencia de comandos y se establecen si se conocen; de lo contrario, están vacíos:arg1='todos los servidores' arg2='maestro fallido' arg3='candidato seleccionado', arg4='esclavos del maestro anterior (los candidatos)' y aprobados así:'scriptname arg1 arg2 arg3 arg4' El script debe ser accesible en el controlador y ejecutable. | |
| replication_post_unsuccessful_failover_script | Este script se ejecuta si falla el intento de conmutación por error. Si el script devuelve un valor distinto de cero o no existe, se anulará la conmutación por error. Se proporcionan cuatro argumentos a la secuencia de comandos y se establecen si se conocen; de lo contrario, están vacíos:arg1='todos los servidores' arg2='maestro fallido' arg3='candidato seleccionado', arg4='esclavos del maestro anterior (los candidatos)' y aprobados así:'scriptname arg1 arg2 arg3 arg4' El script debe ser accesible en el controlador y ejecutable. |
Retención
| Nombre | Valor predeterminado | Descripción |
|---|---|---|
| ops_report_retention | 31 | La configuración de cuántos días para mantener los informes operativos. Se eliminan los informes que coinciden con el período de retención. |
Muestreo
| Nombre | Valor predeterminado | Descripción |
|---|---|---|
| habilitar_icmp_ping | verdadero | Alterna si ClusterControl debe medir los tiempos de ping ICMP al host. |
| host_stats_collection_interval | 30 | Configuración del intervalo de recopilación del host (CPU, memoria, etc.). |
| host_stats_window_size | 180 | Configurar el tamaño de la ventana (en segundos) para examinar las estadísticas para activar/borrar las alarmas de estadísticas del host. |
| db_stats_collection_interval | 30 | Configuración del intervalo de recopilación de estadísticas de la base de datos. |
| db_proc_stats_collection_interval | 5 | Configuración del intervalo de recopilación de estadísticas del proceso de la base de datos. El valor mínimo permitido es 1 segundo. Requiere un reinicio del servicio cmon. |
| lb_stats_collection_interval | 15 | Configuración del intervalo de recopilación de estadísticas del equilibrador de carga. |
| db_schema_stats_collection_interval | 108000 | Configuración del intervalo de monitoreo de estadísticas del esquema. |
| db_deadlock_check_interval | 0 | Con qué frecuencia verificar si hay interbloqueos. Especificado en segundos. La detección de puntos muertos afectará el uso de la CPU en los nodos de la base de datos. |
| intervalo_de_recopilación_de_registro | 600 | Controla el intervalo entre colecciones de archivos de registro. |
| db_hourly_stats_collection_interval | 5 | Controla cuántos segundos hay entre cada muestra individual en las estadísticas de rango horario. |
| puntos_de_montaje_supervisados | La lista de puntos de montaje a monitorear. | |
| monitor_cpu_temperature | falso | Supervise la temperatura de la CPU. |
| log_queries_not_using_indexes | falso | Configure el monitor de consultas para detectar consultas que no utilicen índices. |
| intervalo_de_muestra_consulta | 1 | Controla el intervalo del monitor de consultas en segundos, -1 significa que no hay monitoreo de consultas. |
| query_monitor_auto_purge_ps | falso | Si está habilitado, la tabla P_S events_statements_summary_by_digest se purgará automáticamente (TRUNCATE TABLE) cada hora. |
| dirección_detección_de_cambio_de_esquema | Se ejecutarán comprobaciones (usando SHOW TABLES/SHOW CREATE TABLE) para determinar si el esquema ha cambiado. Las comprobaciones se ejecutan en la dirección especificada y tienen el formato HOSTNAME:PORT. También se debe configurar schema_change_detection_databases. Se crea una diferencia de una tabla modificada. | |
| esquema_cambio_detección_bases de datos | Lista de bases de datos separadas por comas para monitorear los cambios de esquema. Si está vacío, no se realizan comprobaciones. | |
| esquema_cambio_detección_pausa_tiempo_ms | 0 | Tiempo de pausa en ms entre cada SHOW CREATE TABLE. El tiempo de pausa afectará la duración del proceso de detección. |
| habilitar_es_consultas | verdadero | Especifica si se ejecutarán o no consultas al esquema_información. Las consultas a information_schema pueden no ser adecuadas cuando se tienen muchos objetos de esquema (cientos de bases de datos, cientos de tablas en cada base de datos, disparadores, usuarios, eventos, sprocs). Si está deshabilitado, la consulta que se ejecutará se registrará para que se pueda determinar si la consulta es adecuada en su entorno. |
Intercambio
| Nombre | Valor predeterminado | Descripción |
|---|---|---|
| swap_warning | 20 | Umbral de alarma de advertencia para uso de intercambio. |
| intercambio_crítico | 90 | Umbral de alarma crítica para uso de intercambio. |
| período_de_intercambio_de_entrada | 0 | El intervalo para intercambiar alarmas de E/S (<=0 desactiva). |
| swap_inout_warning | 10240 | El número de páginas intercambiadas de E/S en el intervalo especificado (swap_inout_period, por defecto 10 minutos) para la advertencia. |
| swap_inout_critical | 102400 | El número de páginas intercambiadas de E/S en el intervalo especificado (swap_inout_period, por defecto 10 minutos) para críticas. |
Sistema
| Nombre | Valor predeterminado | Descripción |
|---|---|---|
| ruta_configuración_cmon | /etc/cmon.d/cmon_x.cnf | La ruta del archivo de configuración. Este valor de configuración es de solo lectura. |
| os | debian/redhat | El tipo de sistema operativo. Los valores posibles son 'debian' o 'redhat'. |
| libssh_timeout | 30 | El valor de tiempo de espera de red para conexiones SSH. |
| sudo | sudo -n 2>/dev/null | El comando utilizado para obtener privilegios de superusuario. |
| puerto_ssh | 22 | El puerto para las conexiones SSH a los nodos. |
| nombre_repo_local | Los nombres de los repositorios locales utilizados para la implementación del clúster. | |
| frontend_url | La URL enviada en los correos electrónicos para dirigir al destinatario a la interfaz web de ClusterControl. | |
| purgar | 7 | Durante cuánto tiempo ClusterControl conservará los datos. Medido en días, se eliminarán los trabajos, los mensajes de trabajo, las alarmas, los registros recopilados, los informes operativos y la información de crecimiento de la base de datos anterior a esta. |
| os_user_home | /inicio/usuario | El directorio HOME del usuario utilizado en los nodos. |
| cmon_mail_sender | El remitente de correo electrónico utilizado para los correos electrónicos enviados. | |
| plugin_dir | La ruta del directorio de complementos. | |
| usar_internal_repos | falso | Configuración que deshabilitó la configuración del repositorio de terceros. |
| cmon_use_mail | falso | Configuración para usar el comando 'mail' para enviar correos electrónicos. |
| habilitar_html_correos electrónicos | verdadero | Habilita el envío de correos electrónicos HTML. |
| enviar_borrar_alarma | verdadero | Alterna el envío de correo electrónico en caso de que se eliminen las alarmas del grupo. |
| dir_paquete_software | Esta es la ubicación de almacenamiento de los paquetes de software, es decir, todos los archivos necesarios para instalar correctamente un nodo, si no hay un repositorio yum/apt disponible, deben colocarse aquí. Se aplica principalmente a MySQL Cluster o a instalaciones anteriores de Codership/Galera. |
Umbral
| Nombre | Valor predeterminado | Descripción |
|---|---|---|
| advertencia_ram | 80 | Umbral de alarma de advertencia para uso de RAM. |
| ram_critical | 90 | Umbral de alarma crítica para uso de RAM. |
| advertencia_espacio_disco | 80 | Umbral de alarma de advertencia para el uso del disco. |
| espacio_disco_crítico | 90 | Umbral de alarma crítica para el uso del disco. |
| advertencia_cpu | 80 | Umbral de alarma de advertencia para uso de CPU. |
| cpu_critical | 90 | Umbral de alarma crítica para uso de CPU. |
| cpu_steal_warning | 10 | Umbral de alarma de advertencia para robo de CPU. |
| cpu_steal_critical | 20 | Umbral de alarma crítica para robo de CPU. |
| cpu_iowait_warning | 50 | Umbral de alarma de advertencia para la espera de E/S de la CPU. |
| cpu_iowait_critical | 60 | Umbral de alarma crítica para CPU IO Wait. |
| advertencia_ssh_lento | 6 | Se generará una alarma de advertencia si se tarda más del tiempo especificado en establecer una conexión SSH (segundos). |
| lento_ssh_crítico | 12 | Se generará una alarma crítica si se tarda más del tiempo especificado en establecer una conexión SSH (segundos). |
Conclusión
Como puede ver, hay muchos parámetros para cambiar si necesita adaptar ClusterControl a su carga de trabajo o negocio. Revisar todos los valores y cambiarlos en consecuencia podría llevar mucho tiempo, pero al final del día, ahorrará tiempo ya que puede aprovechar al máximo todas las características de ClusterControl.



