Una de las mayores preocupaciones al tratar y administrar bases de datos es su complejidad de datos y tamaño. A menudo, las organizaciones se preocupan por cómo lidiar con el crecimiento y administrar el impacto del crecimiento porque falla la administración de la base de datos. La complejidad viene con preocupaciones que no se abordaron inicialmente y no se vieron, o podrían pasarse por alto porque la tecnología que se usa actualmente podrá manejarse por sí misma. La gestión de una base de datos grande y compleja debe planificarse en consecuencia, especialmente cuando se espera que el tipo de datos que gestiona o maneje crezca masivamente, ya sea de forma anticipada o impredecible. El objetivo principal de la planificación es evitar desastres no deseados, o deberíamos decir, ¡evitar convertirse en humo! En este blog, cubriremos cómo administrar de manera eficiente grandes bases de datos.
El tamaño de los datos sí importa
El tamaño de la base de datos es importante ya que tiene un impacto en el rendimiento y su metodología de gestión. La forma en que se procesan y almacenan los datos contribuirá a cómo se administrará la base de datos, lo que se aplica tanto a los datos en tránsito como en reposo. Para muchas organizaciones grandes, los datos son oro y el crecimiento de los datos podría tener un cambio drástico en el proceso. Por lo tanto, es vital contar con planes previos para manejar datos crecientes en una base de datos.
En mi experiencia trabajando con bases de datos, he sido testigo de que los clientes tienen problemas para lidiar con las penalizaciones de rendimiento y administrar el crecimiento extremo de los datos. Surgen dudas sobre si normalizar las tablas o desnormalizarlas.
Normalización de tablas
La normalización de las tablas mantiene la integridad de los datos, reduce la redundancia y facilita la organización de los datos en una forma más eficiente de administrar, analizar y extraer. Trabajar con tablas normalizadas genera eficiencia, especialmente cuando se analiza el flujo de datos y se recuperan datos mediante instrucciones SQL o cuando se trabaja con lenguajes de programación como C/C++, Java, Go, Ruby, PHP o interfaces de Python con MySQL Connectors.
Aunque las preocupaciones con las tablas normalizadas tienen una penalización en el rendimiento y pueden ralentizar las consultas debido a una serie de uniones al recuperar los datos. Mientras que las tablas desnormalizadas, todo lo que tiene que considerar para la optimización se basa en el índice o la clave principal para almacenar datos en el búfer para una recuperación más rápida que realizar búsquedas en varios discos. Las tablas desnormalizadas no requieren uniones, pero sacrifican la integridad de los datos y el tamaño de la base de datos tiende a crecer cada vez más.
Cuando su base de datos es grande, considere tener un DDL (lenguaje de definición de datos) para su tabla de base de datos en MySQL/MariaDB. Agregar una clave principal o única para su tabla requiere una reconstrucción de la tabla. Cambiar el tipo de datos de una columna también requiere una reconstrucción de la tabla, ya que el algoritmo aplicable para aplicar es solo ALGORITHM=COPY.
Si está haciendo esto en su entorno de producción, puede ser un desafío. Duplica el desafío si tu mesa es enorme. Imagine un millón o un billón de números de filas. No puede aplicar una instrucción ALTER TABLE directamente a su tabla. Eso puede bloquear todo el tráfico entrante que deberá acceder a la tabla en la que actualmente está aplicando el DDL. Sin embargo, esto se puede mitigar usando pt-online-schema-change o el gran fantasma. Sin embargo, requiere monitoreo y mantenimiento mientras se realiza el proceso de DDL.
fragmentación y partición
Con fragmentación y partición, ayuda a segregar o segmentar los datos según su identidad lógica. Por ejemplo, al segregar según la fecha, el orden alfabético, el país, el estado o la clave principal según el rango dado. Esto ayuda a que el tamaño de su base de datos sea manejable. Mantenga el tamaño de su base de datos hasta el límite que sea manejable para su organización y su equipo. Fácil de escalar si es necesario o fácil de administrar, especialmente cuando ocurre un desastre.
Cuando decimos manejable, considere también los recursos de capacidad de su servidor y también su equipo de ingeniería. No se puede trabajar con grandes y grandes datos con pocos ingenieros. Trabajar con big data, como 1000 bases de datos con una gran cantidad de conjuntos de datos, requiere una gran demanda de tiempo. Habilidad sabia y experiencia es una necesidad. Si el costo es un problema, ese es el momento en que puede aprovechar los servicios de terceros que ofrecen servicios administrados o consultas pagas o soporte para cualquier trabajo de ingeniería de este tipo.
Conjuntos de caracteres y clasificación
Los juegos de caracteres y las intercalaciones afectan el almacenamiento y el rendimiento de los datos, especialmente en el juego de caracteres y las intercalaciones seleccionadas. Cada conjunto de caracteres y colaciones tiene su propósito y, en su mayoría, requiere diferentes longitudes. Si tiene tablas que requieren otros conjuntos de caracteres y colaciones debido a la codificación de caracteres, los datos se almacenarán y procesarán para su base de datos y tablas o incluso con columnas.
Esto afecta la forma de administrar su base de datos de manera efectiva. Afecta su almacenamiento de datos y también el rendimiento como se indicó anteriormente. Si ha entendido los tipos de caracteres que procesará su aplicación, tome nota del conjunto de caracteres y las intercalaciones que se utilizarán. Los juegos de caracteres de tipo LATIN serán suficientes en su mayoría para que se almacene y procese el tipo de caracteres alfanuméricos.
Si es inevitable, la fragmentación y el particionamiento ayudan, al menos, a mitigar y limitar los datos para evitar sobrecargar demasiados datos en su servidor de base de datos. La gestión de datos muy grandes en un solo servidor de base de datos puede afectar la eficiencia, especialmente para fines de copia de seguridad, desastres y recuperación, o recuperación de datos en caso de corrupción o pérdida de datos.
La complejidad de la base de datos afecta al rendimiento
Una base de datos grande y compleja tiende a tener un factor en lo que respecta a la penalización del rendimiento. Complejo, en este caso, significa que el contenido de su base de datos consta de ecuaciones matemáticas, coordenadas o registros numéricos y financieros. Ahora mezcló estos registros con consultas que utilizan agresivamente las funciones matemáticas nativas de su base de datos. Eche un vistazo al ejemplo de consulta SQL (compatible con MySQL/MariaDB) a continuación,
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
Considere que esta consulta se aplica en una tabla que va desde un millón de filas. Existe una gran posibilidad de que esto pueda paralizar el servidor y podría consumir muchos recursos y poner en peligro la estabilidad de su clúster de base de datos de producción. Las columnas involucradas tienden a indexarse para optimizar y hacer que esta consulta sea eficaz. Sin embargo, agregar índices a las columnas a las que se hace referencia para un rendimiento óptimo no garantiza la eficiencia de administrar sus bases de datos grandes.
Al manejar la complejidad, la forma más eficiente es evitar el uso riguroso de ecuaciones matemáticas complejas y el uso agresivo de esta capacidad computacional compleja integrada. Esto se puede operar y transportar a través de cálculos complejos utilizando lenguajes de programación de back-end en lugar de utilizar la base de datos. Si tiene cálculos complejos, entonces, ¿por qué no almacenar estas ecuaciones en la base de datos, recuperar las consultas, organizarlas para que sean más fáciles de analizar o depurar cuando sea necesario?
¿Está utilizando el motor de base de datos correcto?
Una estructura de datos afecta el rendimiento del servidor de la base de datos según la combinación de la consulta dada y los registros que se leen o recuperan de la tabla. Los motores de base de datos dentro de MySQL/MariaDB son compatibles con InnoDB y MyISAM que usan B-Trees, mientras que los motores de base de datos NDB o Memory usan Hash Mapping. Estas estructuras de datos tienen su notación asintótica que expresa el rendimiento de los algoritmos utilizados por estas estructuras de datos. Los llamamos en Ciencias de la Computación como notación Big O que describe el rendimiento o la complejidad de un algoritmo. Dado que InnoDB y MyISAM usan B-Trees, usa O (log n) para la búsqueda. Mientras que Hash Tables o Hash Maps usan O (n). Ambos comparten el promedio y el peor de los casos para su desempeño con su notación.
Ahora, de vuelta al motor específico, dada la estructura de datos del motor, la consulta que se aplicará en función de los datos de destino que se recuperarán, por supuesto, afecta el rendimiento de su servidor de base de datos. Las tablas hash no pueden recuperar rangos, mientras que B-Trees es muy eficiente para realizar este tipo de búsquedas y también puede manejar grandes cantidades de datos.
Usando el motor adecuado para los datos que almacena, necesita identificar qué tipo de consulta aplica para estos datos específicos que almacena. Qué tipo de lógica formularán estos datos cuando se transformen en una lógica de negocios.
Manejar miles o miles de bases de datos, usar el motor adecuado en combinación con sus consultas y los datos que desea recuperar y almacenar brindará un buen rendimiento. Dado que ha predeterminado y analizado sus requisitos para su propósito para el entorno de base de datos adecuado.
Herramientas adecuadas para administrar grandes bases de datos
Es muy duro y difícil administrar una base de datos muy grande sin una plataforma sólida en la que pueda confiar. Incluso con ingenieros de bases de datos buenos y capacitados, técnicamente el servidor de base de datos que está utilizando es propenso a errores humanos. Un error de cualquier cambio en sus parámetros y variables de configuración podría resultar en un cambio drástico que degradaría el rendimiento del servidor.
Realizar una copia de seguridad de su base de datos en una base de datos muy grande puede ser un desafío a veces. Hay casos en los que la copia de seguridad puede fallar por algunas razones extrañas. Por lo general, las consultas que podrían detener el servidor donde se ejecuta la copia de seguridad provocan un error. De lo contrario, debe investigar la causa.
El uso de automatización como Chef, Puppet, Ansible, Terraform o SaltStack se puede usar como su IaC para proporcionar tareas más rápidas de realizar. Mientras usa otras herramientas de terceros también para ayudarlo a monitorear y proporcionar imágenes gráficas de alta calidad. Los sistemas de notificación de alertas y alarmas también son muy importantes para informarle sobre problemas que pueden ocurrir desde una advertencia hasta un nivel de estado crítico. Aquí es donde ClusterControl es muy útil en este tipo de situaciones.
ClusterControl ofrece facilidad para administrar una gran cantidad de bases de datos o incluso con tipos de entornos fragmentados. Se ha probado e instalado miles de veces y se ha estado ejecutando en producciones que proporcionan alarmas y notificaciones a los DBA, ingenieros o DevOps que operan el entorno de la base de datos. Desde puesta en escena o desarrollo, control de calidad, hasta entorno de producción.
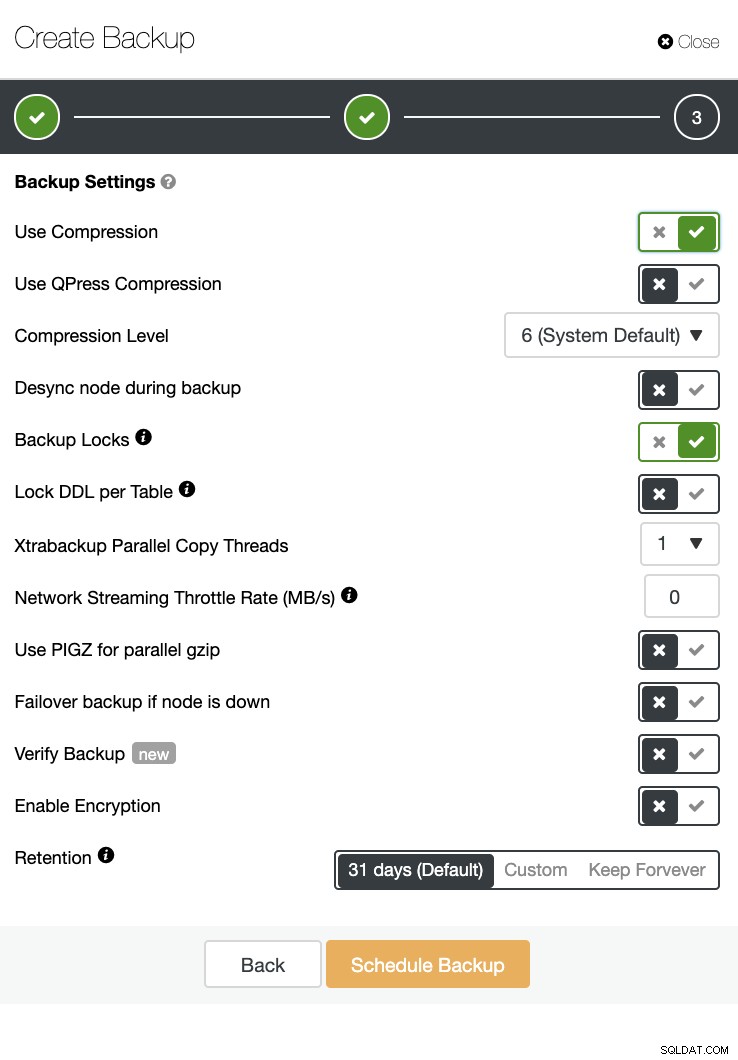
ClusterControl también puede realizar una copia de seguridad y una restauración. Incluso con grandes bases de datos, puede ser eficiente y fácil de administrar, ya que la interfaz de usuario proporciona programación y también tiene opciones para cargarlo en la nube (AWS, Google Cloud y Azure).
También hay una verificación de respaldo y muchas opciones como encriptación y compresión. Vea la captura de pantalla a continuación, por ejemplo (creando una copia de seguridad para MySQL usando Xtrabackup):
Conclusión
La administración de grandes bases de datos, como miles o más, se puede hacer de manera eficiente, pero se debe determinar y preparar de antemano. El uso de las herramientas adecuadas, como la automatización o incluso la suscripción a servicios administrados, ayuda drásticamente. Aunque incurre en costos, el tiempo de respuesta del servicio y el presupuesto para adquirir ingenieros capacitados se pueden reducir siempre que se disponga de las herramientas adecuadas.



