Zonas MongoDB
Para entender las Zonas MongoDB, primero debemos entender qué es una Zona:un grupo de fragmentos basados en un conjunto específico de etiquetas.
MongoDB Zones ayuda en la distribución de fragmentos basados en etiquetas, entre fragmentos. Todo el trabajo (lecturas y escrituras) relacionado con documentos dentro de una zona se realiza en fragmentos que coinciden con esa zona.
Puede haber diferentes escenarios en los que los clústeres fragmentados (basados en zonas) pueden resultar muy útiles. Digamos:
- Una aplicación, que está distribuida geográficamente, puede requerir la interfaz, así como el almacén de datos
- Una aplicación tiene una arquitectura de n niveles, de modo que algunos registros se obtienen de un hardware de nivel superior (baja latencia), mientras que otros se pueden obtener de un hardware de nivel bajo (inducción de alta latencia)
Beneficios de usar zonas de MongoDB
Con la ayuda de MongoDB Zones, los DBA pueden crear soluciones de almacenamiento en niveles que respalden el ciclo de vida de los datos, con datos de uso frecuente almacenados en la memoria, datos menos utilizados almacenados en el servidor y, en el momento adecuado, datos archivados fuera de línea.
Cómo configurar zonas
En clústeres fragmentados, puede crear zonas que representen un grupo de fragmentos y asociar uno o más rangos de valores de clave de fragmento a esa zona. MongoDB enruta todas las lecturas y todas las escrituras que entran en un rango de zona solo a los fragmentos dentro de la zona. Puede asociar cada zona con uno o más fragmentos en el clúster y un fragmento puede asociarse con cualquier cantidad de zonas.
Algunos de los patrones de implementación más comunes en los que se pueden aplicar zonas son los siguientes:
- Aísle un subconjunto específico de datos en un conjunto específico de fragmentos.
- Al garantizar que los datos más relevantes residen en fragmentos que están geográficamente más cerca de los servidores de aplicaciones.
- Direccione los datos a los fragmentos en función del rendimiento del hardware del fragmento.
La siguiente imagen ilustra un clúster fragmentado con tres fragmentos y dos zonas. La zona A representa un rango con un límite inferior de 0 y un límite superior de 10. La zona B muestra un rango con un límite inferior de 10 y un límite superior de 20. Los fragmentos ROJO y AZUL tienen la zona A. Shard BLUE también tiene la zona B. Shard GREEN no tiene zonas asociadas. El clúster se encuentra en un estado estable y ningún fragmento viola ninguna de las zonas
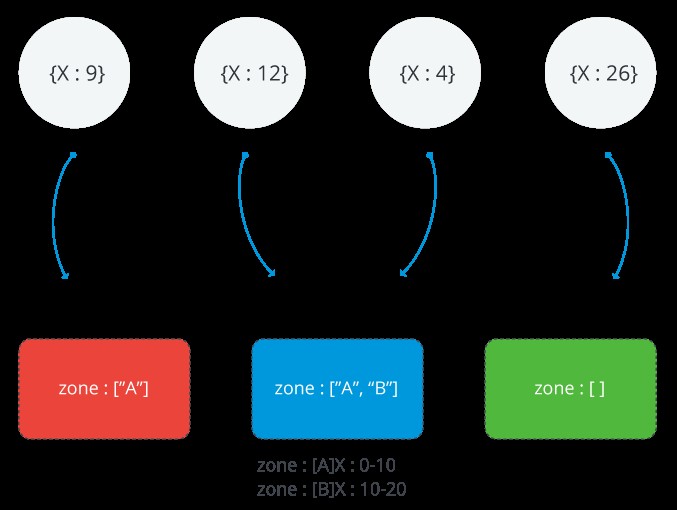
Alcance de una Zona MongoDB
Todas y cada una de las zonas cubren uno o más rangos de valores de clave de fragmento. Cada rango que cubre una zona siempre incluye su límite inferior y excluye su límite superior.
RECUERDA: Las zonas no pueden compartir rangos y no pueden tener rangos superpuestos.
Agregar fragmentos a una zona
El método sh.addShardTag() se usa para agregar zonas a un fragmento. Un solo fragmento puede tener varias zonas y varios fragmentos también pueden tener la misma zona. El siguiente ejemplo agrega la zona A a un fragmento.
sh.addShardTag("shard0000", "A")Eliminar fragmentos de una zona
Para eliminar una zona de un fragmento, se utiliza el método sh.removeShardTag(). El siguiente ejemplo elimina la zona A de un fragmento.
sh.removeShardTag("shard0002", "A")Consejos para zonas MongoDB
Mantenga los documentos simples
MongoDB es una base de datos sin esquemas. Esto significa que no hay un esquema predefinido por defecto. Podemos agregar un esquema predefinido en versiones más nuevas, pero no es obligatorio. No subestime las dificultades que surgen al trabajar con documentos y matrices, ya que puede volverse muy difícil analizar sus datos en el lado de la aplicación/proceso ETL. Además, las matrices pueden dañar el rendimiento de la replicación:por cada cambio en la matriz, se replican todos los valores de la matriz.
El mejor hardware no siempre es la mejor opción
El uso de un buen hardware definitivamente ayuda a un buen rendimiento. Pero, ¿qué podría suceder en un entorno cuando muere una instancia de una gran máquina? La respuesta es "conmutación por error".
Tener varias máquinas pequeñas (en lugar de una o dos) en un entorno distribuido puede garantizar que las interrupciones afecten solo a algunas partes del fragmento con poca o ninguna percepción por parte de la aplicación. Pero al mismo tiempo, más máquinas implica una alta probabilidad de fallar. Considere esta compensación cuando diseñe su entorno. Las elecciones correctas afectan el rendimiento.
Conjunto de trabajo
¿Qué tan grande es el conjunto de trabajo? Por lo general, una aplicación no utiliza todos los datos. Algunos datos se actualizan con frecuencia, mientras que otros no. ¿Su conjunto de datos de trabajo cabe en la RAM? El rendimiento óptimo se produce cuando todo el conjunto de datos de trabajo está en la RAM.



