MongoDB es un almacén de datos de documentos que existe desde hace más de una década. En los últimos años, MongoDB se ha convertido en un producto maduro que presenta opciones de nivel empresarial como escalabilidad, seguridad y resiliencia. Sin embargo, con el exigente movimiento de la nube eso no fue lo suficientemente bueno.
Los recursos de la nube, como máquinas virtuales, contenedores, recursos informáticos sin servidor y bases de datos, tienen actualmente una gran demanda. En estos días, muchas soluciones de software pueden implementarse en una fracción del tiempo que solía llevar implementar en el propio hardware. Inició una tendencia y cambió las expectativas de los mercados al mismo tiempo.
Pero la calidad de un servicio en línea no se limita solo a la implementación. A menudo, los usuarios necesitan servicios adicionales, integraciones o funciones adicionales que les ayuden a hacer su trabajo. Las ofertas en la nube aún pueden ser muy limitadas y pueden causar más problemas de los que puede obtener de la automatización y la infraestructura remota.
Entonces, ¿cuál es el enfoque de MongoDB Inc. para este problema común?
La respuesta fue MongoDB Atlas, que trae extensiones internas como parte de una plataforma de automatización/nube más grande. Con la adición de componentes de terceros, MongoDB ha prosperado. En el blog de hoy, vamos a ver qué tienen los desarrolladores y cómo pueden ayudarlo a abordar sus necesidades de procesamiento de datos.
Los elementos que exploraremos hoy son...
- Gráficos de MongoDB
- MongoDB Stich
- Integraciones de MongoDB Kubernetes con Ops Manager
- Migración a la nube de MongoDB
- Búsqueda de texto completo
- Lago de datos de MongoDB (beta)
Gráficos MongoDB
MongoDB Charts es uno de los servicios accesibles a través de la plataforma MongoDB Atlas. Simplemente proporciona una manera fácil de visualizar sus datos viviendo dentro de MongoDB. No necesita mover sus datos a un repositorio diferente o escribir su propio código, ya que MongoDB Charts fue diseñado para trabajar con documentos de datos y facilitar la visualización de sus datos.
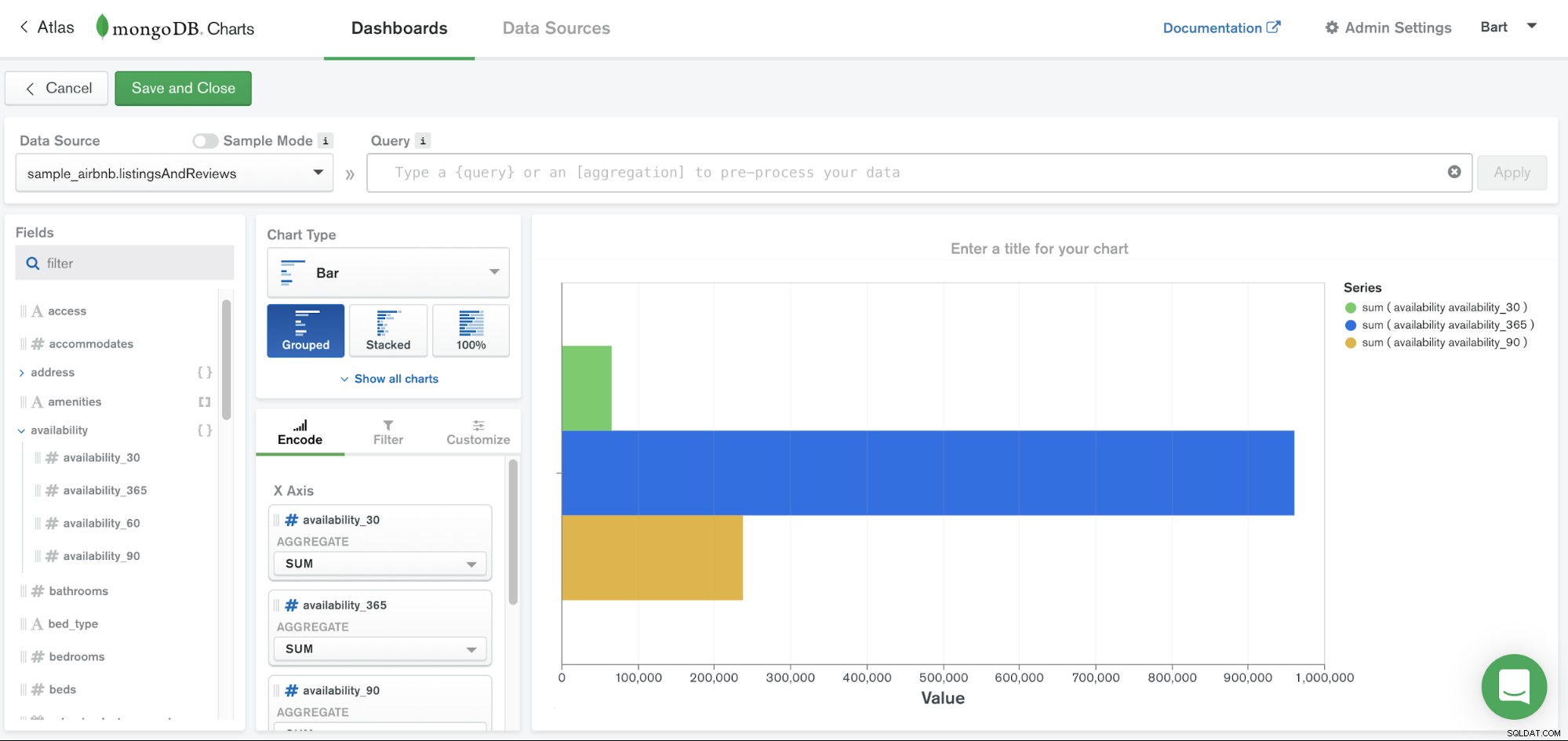
MongoDB Charts hace que comunicar sus datos sea un proceso sencillo al proporcionar herramientas integradas para compartir y colaborar fácilmente en visualizaciones. La visualización de datos es un componente clave para proporcionar una comprensión clara de sus datos, destacando las correlaciones entre las variables y facilitando el discernimiento de patrones y tendencias dentro de su conjunto de datos.
Estas son algunas funciones clave que puede usar en los Gráficos.
Agregación
El marco de agregación es un proceso operativo que manipula documentos en diferentes etapas, los procesa de acuerdo con los criterios proporcionados y luego devuelve los resultados calculados. Los valores de varios documentos se agrupan, en los que se pueden realizar más operaciones para obtener resultados coincidentes.
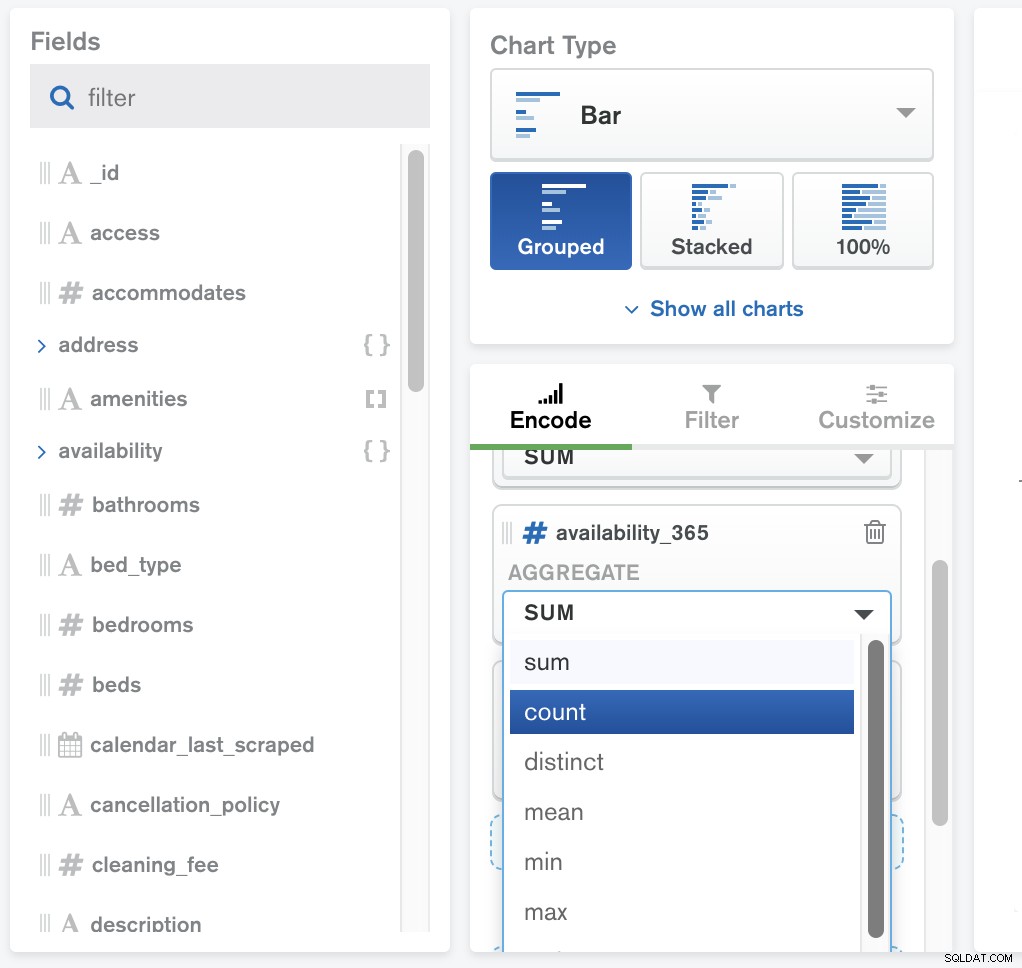
MongoDB Charts proporciona funcionalidad de agregación integrada. La agregación le permite procesar los datos de su colección mediante una variedad de métricas y realizar cálculos como la media y la desviación estándar.
Los gráficos brindan una integración perfecta con MongoDB Atlas. Puede vincular los gráficos de MongoDB a los proyectos de Atlas y comenzar rápidamente a visualizar sus datos de clúster de Atlas.
Manejo de datos de documentos
MongoDB Charts comprende de forma nativa los beneficios del modelo de datos del documento. Gestiona datos basados en documentos, incluidos objetos fijos y matrices. El uso de una estructura de datos anidados proporciona la flexibilidad para estructurar sus datos de la forma que mejor se adapte a su aplicación y, al mismo tiempo, mantener las capacidades de visualización.
MongoDB Charts proporciona una funcionalidad de agregación integrada que le permite procesar los datos de su colección utilizando una variedad de métricas. Es lo suficientemente intuitivo para que lo usen los que no son desarrolladores, lo que permite el análisis de datos de autoservicio, lo que lo convierte en una gran herramienta para los equipos de análisis de datos.
Costura de MongoDB
¿Ha oído hablar de la arquitectura sin servidor?
Con Serverless, compone su aplicación en funciones individuales y autónomas. Cada función está alojada por el proveedor sin servidor y se puede escalar automáticamente a medida que aumenta o disminuye la frecuencia de llamada de función. Esto resulta ser una forma muy rentable de pagar por los recursos informáticos. Solo paga por las veces que se llama a sus funciones, en lugar de pagar para tener su aplicación siempre activa y esperando solicitudes en tantas instancias diferentes.
MongoDB Stitch es un tipo diferente de servicio MongoDB que toma solo lo que es más útil en los entornos de infraestructura en la nube. Es una plataforma sin servidor que permite a los desarrolladores crear aplicaciones sin tener que configurar la infraestructura del servidor. Stitch se realiza sobre MongoDB Atlas, integrando automáticamente la conexión a su base de datos. Puede conectarse a Stitch a través de los SDK de Stitch Client, que están abiertos para muchas de las plataformas que desarrolla.
Integraciones de MongoDB Kubernetes con Ops Manager
Ops Manager es una plataforma de administración para clústeres de MongoDB que ejecuta en su propia infraestructura. Las capacidades de Ops Manager incluyen monitoreo, alertas, recuperación ante desastres, escalado, implementación y actualización de conjuntos de réplicas y clústeres fragmentados, y otros productos de MongoDB. En 2018, MongoDB introdujo la integración beta con Kubernetes.
MongoDB Enterprise Operator es compatible con Kubernetes v1.11 y superior. Ha sido probado contra Openshift 3.11. Este operador requiere Ops Manager o Cloud Manager. En este documento, cuando nos referimos a "Ops Manager", puede sustituirlo por "Cloud Manager". La funcionalidad es la misma.
La instalación es bastante simple y requiere
- Instalación del operador empresarial de MongoDB. Esto se puede hacer mediante helm o un archivo YAML.
- Reúna las propiedades del administrador de operaciones.
- Cree y aplique un archivo ConfigMap de Kubernetes
- Cree el objeto secreto de Kubernetes que almacenará la clave API de Ops Manager
En este ejemplo básico vamos a utilizar el archivo YAML:
kubectl apply -f crds.yaml
kubectl apply -f https://raw.githubusercontent.com/mongodb/mongodb-enterprise-kubernetes/master/mongodb-enterprise.yamlEl siguiente paso es obtener la siguiente información que vamos a utilizar en el archivo ConfigMap. Todo eso se puede encontrar en el administrador de operaciones.
- URL base. La URL base es la URL de su administrador de operaciones o administrador de la nube.
- Identificación del proyecto. La identificación de un proyecto de administrador de operaciones en el que se implementará el operador de Kubernetes.
- Usuario. Un nombre de usuario de administrador de operaciones existente
- Clave API pública. Utilizado por el operador de Kubernetes para conectarse al punto final de la API REST de Ops Manager
Ahora que hemos adquirido la información de configuración necesaria de Ops Manager, necesitamos crear un archivo Kubernetes ConfigMap para Kubernetes. Para fines de ejercicio, podemos llamar a este archivo project.yaml.
apiVersion: v1
kind: ConfigMap
metadata:
name:<<Name>>
namespace: mongodb
data:
projectId:<<Project ID>>
baseUrl: <<OpsManager URL>>El siguiente paso es crear ConfigMap para Kubernetes y un archivo secreto
kubectl apply -f my-project.yaml
kubectl -n mongodb create secret generic <<Name of credentials>> --from-literal="user=<<User>>" --from-literal="publicApiKey=<<public-api-key>>"Una vez que lo tengamos, podemos implementar nuestro primer clúster
apiVersion: mongodb.com/v1
kind: MongoDbReplicaSet
metadata:
name: <<Replica set name>>
namespace: mongodb
spec:
members: 3
version: 4.2.0
persistent: false
project: <<Name value specified in metadata.name of ConfigMap file>>
credentials: <<Name of credentials secret>>Para obtener instrucciones más detalladas, visite la documentación de MongoDB.
Migración a la nube de MongoDB
El Servicio de migración en vivo de Atlas puede migrar sus datos desde su entorno existente, ya sea en AWS, Azure, GCP o en las instalaciones, a MongoDB Atlas, la base de datos global en la nube para MongoDB.
La migración se realiza a través de un servicio de replicación dedicado. El proceso Atlas Live Migration transmite datos a través de un servidor de aplicaciones controlado por MongoDB.
La migración en vivo funciona manteniendo un clúster en MongoDB Atlas sincronizado con su base de datos de origen. Durante este proceso, su aplicación puede continuar leyendo y escribiendo desde su base de datos de origen. Dado que el proceso observa los próximos cambios, todos se replicarán y la migración se puede realizar en línea. Usted decide cuándo cambiar la configuración de conexión de la aplicación y realizar la transición. Para hacer el proceso menos propenso, Atlas proporciona la opción Validar que verifica el acceso IP de la lista blanca, la configuración SSL, CA, etc.
Búsqueda de texto completo
La búsqueda de texto completo es otro servicio en la nube proporcionado por MongoDB y está disponible solo en MongoDB Atlas. Las implementaciones que no son de Atlas MongoDB pueden utilizar la indexación de texto. Atlas Full-Text Search se basa en Open Source Apache Lucene. Lucene es una poderosa biblioteca de búsqueda de texto. Lucene tiene una sintaxis de consulta personalizada para consultar sus índices. Es la base de sistemas populares como Elasticsearch y Apache Solr. Permite crear un índice para la búsqueda de texto completo, es buscar, guardar y leer. Está completamente integrado en Atlas MongoDB, por lo que no hay sistemas o infraestructura adicionales para aprovisionar o administrar.
Lago de datos MongoDB (beta)
La última característica de la nube de MongoDB que nos gustaría mencionar en MongoDB Data Lake. Es un servicio bastante nuevo que aborda el popular concepto de lagos de datos. Un lago de datos es una gran cantidad de datos sin procesar, cuyo propósito aún no está definido. En lugar de colocar los datos en un almacén de datos especialmente diseñado, los mueve a un lago de datos en su formato original. Esto elimina los costos iniciales de ingesta de datos, como la transformación. Una vez que los datos se colocan en el.
El uso de Atlas Data Lake para ingerir sus datos de S3 en los clústeres de Atlas le permite consultar los datos almacenados en sus depósitos de AWS S3 mediante Mongo Shell, MongoDB Compass y cualquier controlador de MongoDB.
Sin embargo, existen algunas limitaciones. Las siguientes funciones aún no funcionan, como monitorear lagos de datos con herramientas de monitoreo de Atlas, compatibilidad con una sola cuenta S3 de AWS, lista blanca de IP y limitaciones de cuentas y grupos de seguridad de AWS o sin posibilidad de agregar índices.



