TL;DR:mongoengine está pasando mucho tiempo convirtiendo todas las matrices devueltas en dictados
Para probar esto, construí una colección con un documento con un DictField con un gran dict anidado . El documento está aproximadamente en su rango de 5-10 MB.
Entonces podemos usar timeit.timeit
para confirmar la diferencia en lecturas usando pymongo y mongoengine.
Entonces podemos usar pycallgraph y GraphViz para ver por qué mongoengine está tardando tanto.
Aquí está el código completo:
import datetime
import itertools
import random
import sys
import timeit
from collections import defaultdict
import mongoengine as db
from pycallgraph.output.graphviz import GraphvizOutput
from pycallgraph.pycallgraph import PyCallGraph
db.connect("test-dicts")
class MyModel(db.Document):
date = db.DateTimeField(required=True, default=datetime.date.today)
data_dict_1 = db.DictField(required=False)
MyModel.drop_collection()
data_1 = ['foo', 'bar']
data_2 = ['spam', 'eggs', 'ham']
data_3 = ["subf{}".format(f) for f in range(5)]
m = MyModel()
tree = lambda: defaultdict(tree) # https://stackoverflow.com/a/19189366/3271558
data = tree()
for _d1, _d2, _d3 in itertools.product(data_1, data_2, data_3):
data[_d1][_d2][_d3] = list(random.sample(range(50000), 20000))
m.data_dict_1 = data
m.save()
def pymongo_doc():
return db.connection.get_connection()["test-dicts"]['my_model'].find_one()
def mongoengine_doc():
return MyModel.objects.first()
if __name__ == '__main__':
print("pymongo took {:2.2f}s".format(timeit.timeit(pymongo_doc, number=10)))
print("mongoengine took", timeit.timeit(mongoengine_doc, number=10))
with PyCallGraph(output=GraphvizOutput()):
mongoengine_doc()
Y el resultado demuestra que mongoengine está siendo muy lento en comparación con pymongo:
pymongo took 0.87s
mongoengine took 25.81118331072267
El gráfico de llamadas resultante ilustra claramente dónde está el cuello de botella:
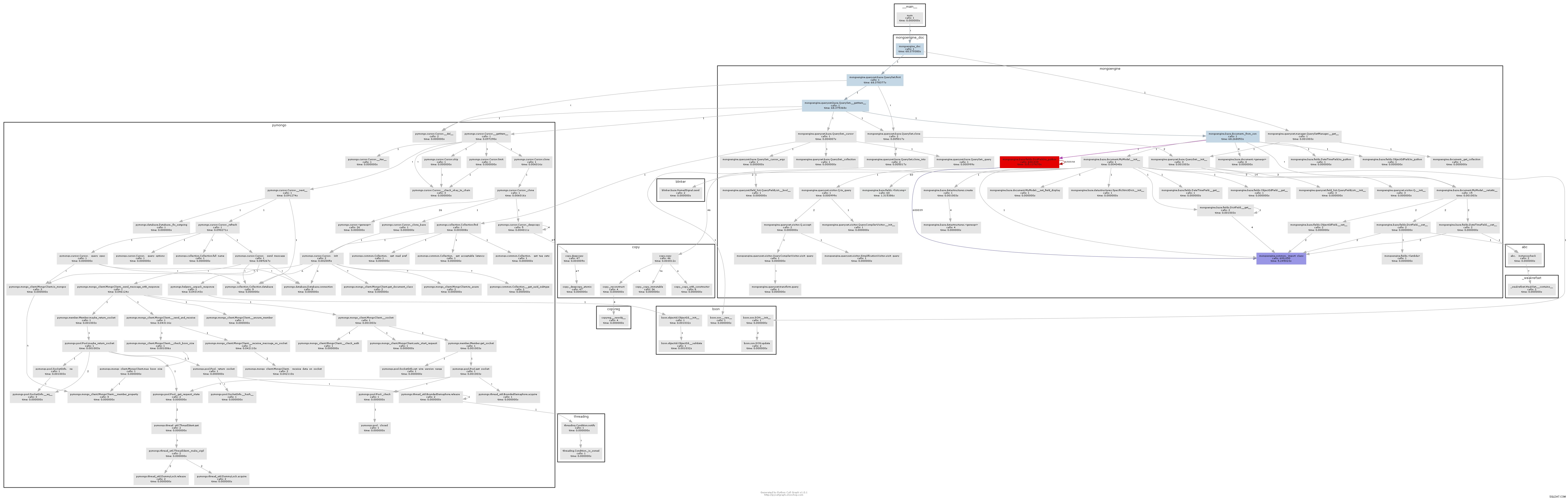
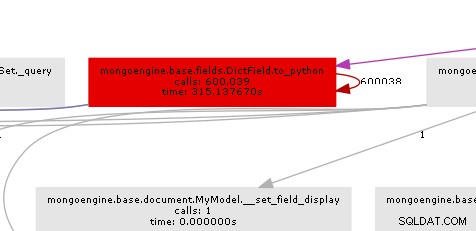
Esencialmente, mongoengine llamará al método to_python en cada DictField que vuelve de la base de datos. to_python es bastante lento y en nuestro ejemplo se llama una cantidad increíble de veces.
Mongoengine se utiliza para asignar con elegancia la estructura de su documento a objetos de Python. Si tiene documentos no estructurados muy grandes (para los que mongodb es excelente), entonces mongoengine no es realmente la herramienta adecuada y solo debe usar pymongo.
Sin embargo, si conoce la estructura, puede usar EmbeddedDocument campos para obtener un rendimiento ligeramente mejor de mongoengine. Ejecuté una prueba similar pero no equivalente código en esta esencia
y la salida es:
pymongo with dict took 0.12s
pymongo with embed took 0.12s
mongoengine with dict took 4.3059175412661075
mongoengine with embed took 1.1639373211854682
Entonces puede hacer que mongoengine sea más rápido, pero pymongo es mucho más rápido aún.
ACTUALIZAR
Un buen atajo a la interfaz de pymongo aquí es usar el marco de agregación:
def mongoengine_agg_doc():
return list(MyModel.objects.aggregate({"$limit":1}))[0]