El siguiente tocsv y fromcsv Las funciones brindan una solución al problema planteado excepto por una complicación relacionada con el requisito (6) relacionado con los encabezados. Esencialmente, este requisito se puede cumplir usando las funciones dadas aquí agregando un paso de transposición de matriz.
Ya sea que se agregue o no un paso de transposición, la ventaja del enfoque adoptado aquí es que no hay restricciones en las claves o valores JSON. En particular, pueden contener puntos (puntos), líneas nuevas y/o caracteres NUL.
En el ejemplo, se proporciona una matriz de objetos, pero de hecho, cualquier flujo de documentos JSON válidos podría usarse como entrada para tocsv; gracias a la magia de jq, fromcsv recreará la transmisión original (en el sentido de igualdad entidad por entidad).
Por supuesto, dado que no existe un estándar CSV, el CSV producido por tocsv Es posible que no todos los procesadores CSV entiendan la función. En particular, tenga en cuenta que el tocsv función definida aquí mapea líneas nuevas incrustadas en cadenas JSON o nombres clave a la cadena de dos caracteres "\n" (es decir, una barra invertida literal seguida de la letra "n"); la operación inversa realiza la traducción inversa para cumplir con el "viaje de ida y vuelta" requisito.
(El uso de tail es solo para simplificar la presentación; sería trivial modificar la solución para convertirla en una única jq).
El CSV se genera asumiendo que se puede incluir cualquier valor en un campo siempre que (a) el campo esté entrecomillado y (b) las comillas dobles dentro del campo estén duplicadas.
Cualquier solución genérica que admita "viajes de ida y vuelta" seguramente será algo complicada. La razón principal por la que la solución que se presenta aquí es más compleja de lo que cabría esperar es que se agrega una tercera columna, en parte para facilitar la distinción entre enteros y cadenas con valores enteros, pero principalmente porque facilita la distinción entre tamaño-1 y tamaño -2 matrices producidas por jq's--stream opción. No hace falta decir que hay otras formas de abordar estos problemas; el número de llamadas a jq también podría reducirse.
La solución se presenta como un script de prueba que verifica el requisito de ida y vuelta en un caso de prueba revelador:
#!/bin/bash
function json {
cat<<EOF
[
{
"a": 1,
"b": [
1,
2,
"1"
],
"c": "d\",ef",
"embed\"ed": "quote",
"null": null,
"string": "null",
"control characters": "a\u0000c",
"newline": "a\nb"
},
{
"x": 1
}
]
EOF
}
function tocsv {
jq -ncr --stream '
(["path", "value", "stringp"],
(inputs | . + [.[1]|type=="string"]))
| map( tostring|gsub("\"";"\"\"") | gsub("\n"; "\\n"))
| "\"\(.[0])\",\"\(.[1])\",\(.[2])"
'
}
function fromcsv {
tail -n +2 | # first duplicate backslashes and deduplicate double-quotes
jq -rR '"[\(gsub("\\\\";"\\\\") | gsub("\"\"";"\\\"") ) ]"' |
jq -c '.[2] as $s
| .[0] |= fromjson
| .[1] |= if $s then . else fromjson end
| if $s == null then [.[0]] else .[:-1] end
# handle newlines
| map(if type == "string" then gsub("\\\\n";"\n") else . end)' |
jq -n 'fromstream(inputs)'
}
# Check the roundtrip:
json | tocsv | fromcsv | jq -s '.[0] == .[1]' - <(json)
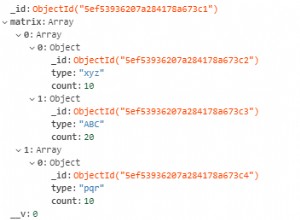
Aquí está el CSV que sería producido por json | tocsv , excepto que SO parece no permitir NUL literales, por lo que lo reemplacé por \0 :
"path","value",stringp
"[0,""a""]","1",false
"[0,""b"",0]","1",false
"[0,""b"",1]","2",false
"[0,""b"",2]","1",true
"[0,""b"",2]","false",null
"[0,""c""]","d"",ef",true
"[0,""embed\""ed""]","quote",true
"[0,""null""]","null",false
"[0,""string""]","null",true
"[0,""control characters""]","a\0c",true
"[0,""newline""]","a\nb",true
"[0,""newline""]","false",null
"[1,""x""]","1",false
"[1,""x""]","false",null
"[1]","false",null