Obtenga una descripción general de los mecanismos disponibles para realizar copias de seguridad de los datos almacenados en Apache HBase y cómo restaurar esos datos en caso de varios escenarios de recuperación/conmutación por error
Con una mayor adopción e integración de HBase en los sistemas comerciales críticos, muchas empresas necesitan proteger este importante activo comercial mediante la creación de estrategias sólidas de copia de seguridad y recuperación ante desastres (BDR) para sus clústeres HBase. Aunque pueda parecer desalentador realizar copias de seguridad y restaurar de forma rápida y sencilla potencialmente petabytes de datos, HBase y el ecosistema Apache Hadoop proporcionan muchos mecanismos integrados para lograr precisamente eso.
En esta publicación, obtendrá una descripción general de alto nivel de los mecanismos disponibles para realizar copias de seguridad de los datos almacenados en HBase y cómo restaurar esos datos en caso de varios escenarios de recuperación/conmutación por error. Después de leer esta publicación, debería poder tomar una decisión informada sobre qué estrategia BDR es la mejor para sus necesidades comerciales. También debe comprender los pros, los contras y las implicaciones de rendimiento de cada mecanismo. (Los detalles aquí se aplican a CDH 4.3.0/HBase 0.94.6 y versiones posteriores).
Nota:En el momento de escribir este artículo, Cloudera Enterprise 4 ofrece funciones de copia de seguridad y recuperación ante desastres listas para producción para HDFS y Hive Metastore a través de Cloudera BDR 1.0 como una función con licencia individual. HBase no está incluido en esa versión de GA; por lo tanto, se requieren los diversos mecanismos descritos en este blog. (Cloudera Enterprise 5, actualmente en versión beta, ofrece administración de instantáneas HBase a través de Cloudera BDR).
Copia de seguridad
HBase es un almacén de datos distribuidos de árbol combinado con estructura de registro con mecanismos internos complejos para garantizar la precisión de los datos, la consistencia, el control de versiones, etc. Entonces, ¿cómo puede obtener una copia de seguridad coherente de estos datos que residen en una combinación de HFiles y Write-Ahead-Logs (WAL) en HDFS y en la memoria de docenas de servidores regionales?
Comencemos con el mecanismo menos disruptivo, la huella de datos más pequeña, el mecanismo de menor impacto en el rendimiento y avancemos hasta llegar a la herramienta de estilo montacargas más disruptiva:
- Instantáneas
- Replicación
- Exportar
- Copiar tabla
- API HTable
- Copia de seguridad sin conexión de datos HDFS
La siguiente tabla proporciona una descripción general para comparar rápidamente estos enfoques, que describiré en detalle a continuación.
| Impacto en el rendimiento | Huella de datos | Tiempo de inactividad | Copias de seguridad incrementales | Facilidad de implementación | Tiempo medio de recuperación (MTTR) | |
| Instantáneas | Mínimo | Pequeño | Breve (Solo en Restaurar) | No | Fácil | Segundos |
| Replicación | Mínimo | Grande | Ninguno | Intrínseco | Medio | Segundos |
| Exportar | Alto | Grande | Ninguno | Sí | Fácil | Alto |
| Copiar tabla | Alto | Grande | Ninguno | Sí | Fácil | Alto |
| API | Medio | Grande | Ninguno | Sí | Difícil | Depende de usted |
| Manual | N/D | Grande | Largo | No | Medio | Alto |
Instantáneas
A partir de CDH 4.3.0, las instantáneas de HBase son completamente funcionales, ricas en funciones y no requieren tiempo de inactividad del clúster durante su creación. Mi colega Matteo Bertozzi cubrió muy bien las instantáneas en su entrada de blog y posterior inmersión profunda. Aquí proporcionaré solo una descripción general de alto nivel.
Las instantáneas simplemente capturan un momento en el tiempo para su tabla al crear el equivalente de enlaces duros de UNIX a los archivos de almacenamiento de su tabla en HDFS (Figura 1). Estas instantáneas se completan en segundos, casi no generan sobrecarga de rendimiento en el clúster y crean una huella de datos minúscula. Sus datos no se duplican en absoluto, sino que simplemente se catalogan en pequeños archivos de metadatos, lo que permite que el sistema vuelva a ese momento en el tiempo en caso de que necesite restaurar esa instantánea.
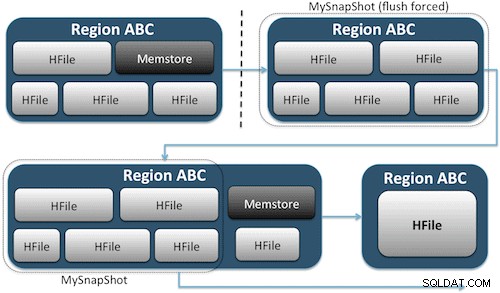
Crear una instantánea de una tabla es tan simple como ejecutar este comando desde el shell de HBase:
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
Después de emitir este comando, encontrará algunos archivos de datos pequeños ubicados en /hbase/.snapshot/myTable (CDH4) o /hbase/.hbase-snapshots (Apache 0.94.6.1) en HDFS que contienen la información necesaria para restaurar su instantánea . Restaurar es tan simple como emitir estos comandos desde el shell:
hbase(main):002:0> disable 'myTable' hbase(main):003:0> restore_snapshot 'MySnapShot' hbase(main):004:0> enable 'myTable'
Nota:Como puede ver, la restauración de una instantánea requiere una breve interrupción, ya que la tabla debe estar fuera de línea. Cualquier dato agregado/actualizado después de que se tomó la instantánea restaurada se perderá.
Si los requisitos de su negocio son tales que debe tener una copia de seguridad externa de sus datos, puede utilizar el comando exportSnapshot para duplicar los datos de una tabla en su clúster HDFS local o en un clúster HDFS remoto de su elección.
Las instantáneas son una imagen completa de su mesa cada vez; ninguna función de instantánea incremental está disponible actualmente.
Replicación de HBase
La replicación HBase es otra herramienta de copia de seguridad de muy baja sobrecarga. (Mi colega Himanshu Vashishtha cubre la replicación en detalle en esta publicación de blog). En resumen, la replicación se puede definir en el nivel de la familia de columnas, funciona en segundo plano y mantiene todas las ediciones sincronizadas entre los clústeres en la cadena de replicación.
La replicación tiene tres modos:maestro->esclavo, maestro<->maestro y cíclico. Este enfoque le brinda flexibilidad para ingerir datos de cualquier centro de datos y garantiza que se replique en todas las copias de esa tabla en otros centros de datos. En caso de una interrupción catastrófica en un centro de datos, las aplicaciones de los clientes se pueden redirigir a una ubicación alternativa para los datos utilizando herramientas de DNS.
La replicación es un proceso sólido y tolerante a fallas que brinda "coherencia eventual", lo que significa que, en cualquier momento, es posible que las ediciones recientes de una tabla no estén disponibles en todas las réplicas de esa tabla, pero se garantiza que eventualmente llegarán.
Nota:Para las tablas existentes, primero debe copiar manualmente la tabla de origen a la tabla de destino a través de uno de los otros medios descritos en esta publicación. La replicación solo actúa en escrituras/ediciones nuevas después de habilitarla.

(De la página de replicación de Apache)
Exportar
La herramienta de exportación de HBase es una utilidad HBase integrada que permite exportar fácilmente datos desde una tabla HBase a archivos de secuencia simples en un directorio HDFS. Crea un trabajo de MapReduce que realiza una serie de llamadas a la API de HBase a su clúster y, una por una, obtiene cada fila de datos de la tabla especificada y escribe esos datos en su directorio HDFS especificado. Esta herramienta es más intensiva en rendimiento para su clúster porque utiliza MapReduce y la API del cliente HBase, pero tiene muchas funciones y admite el filtrado de datos por versión o rango de fechas, lo que permite copias de seguridad incrementales.
Aquí hay una muestra del comando en su forma más simple:
hbase org.apache.hadoop.hbase.mapreduce.Export
Una vez que se exporta su tabla, puede copiar los archivos de datos resultantes en cualquier lugar que desee (como almacenamiento fuera del sitio/fuera del clúster). También puede especificar un clúster/directorio HDFS remoto como la ubicación de salida del comando, y Exportar escribirá directamente el contenido en el clúster remoto. Tenga en cuenta que este enfoque introducirá un elemento de red en la ruta de escritura de la exportación, por lo que debe confirmar que su conexión de red al clúster remoto sea confiable y rápida.
Copiar tabla
La utilidad CopyTable está bien cubierta en la entrada del blog de Jon Hsieh, pero aquí resumiré los conceptos básicos. Similar a Export, CopyTable crea un trabajo de MapReduce que utiliza la API de HBase para leer desde una tabla de origen. La diferencia clave es que CopyTable escribe su salida directamente en una tabla de destino en HBase, que puede ser local para su clúster de origen o en un clúster remoto.
Un ejemplo de la forma más simple del comando es:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
Este comando copiará el contenido de una tabla llamada "prueba" a una tabla en el mismo clúster llamado "testCopy".
Tenga en cuenta que existe una sobrecarga de rendimiento significativa para CopyTable, ya que utiliza "colocaciones" individuales para escribir los datos, fila por fila, en la tabla de destino. Si su tabla es muy grande, CopyTable podría hacer que se llene el almacenamiento de memoria en los servidores de la región de destino, lo que requerirá vaciar el almacenamiento de memoria que eventualmente conducirá a compactaciones, recolección de elementos no utilizados, etc.
Además, debe tener en cuenta las implicaciones de rendimiento de ejecutar MapReduce sobre HBase. Con grandes conjuntos de datos, ese enfoque podría no ser ideal.
API HTable (como una aplicación Java personalizada)
Como siempre ocurre con Hadoop, siempre puede escribir su propia aplicación personalizada que utilice la API pública y consulte la tabla directamente. Puede hacer esto a través de trabajos de MapReduce para utilizar las ventajas de procesamiento por lotes distribuidos de ese marco, o a través de cualquier otro medio de su propio diseño. Sin embargo, este enfoque requiere una comprensión profunda del desarrollo de Hadoop y todas las API y las implicaciones de rendimiento de usarlas en su clúster de producción.
Copia de seguridad sin conexión de datos HDFS sin procesar
El mecanismo de copia de seguridad de fuerza bruta, también el más disruptivo, implica la huella de datos más grande. Puede cerrar limpiamente su clúster HBase y copiar manualmente todas las estructuras de datos y directorios que residen en /hbase en su clúster HDFS. Dado que HBase está inactivo, eso garantizará que todos los datos se hayan conservado en HFiles en HDFS y obtendrá una copia precisa de los datos. Sin embargo, las copias de seguridad incrementales serán casi imposibles de obtener, ya que no podrá determinar qué datos han cambiado o se han agregado al intentar realizar copias de seguridad futuras.
También es importante tener en cuenta que la restauración de sus datos requeriría una meta reparación fuera de línea porque el archivo .META. la tabla contendría información potencialmente no válida en el momento de la restauración. Este enfoque también requiere una red rápida y confiable para transferir los datos fuera del sitio y restaurarlos más tarde si es necesario.
Por estos motivos, Cloudera desaconseja encarecidamente este enfoque para las copias de seguridad de HBase.
Recuperación de desastres
HBase está diseñado para ser un sistema distribuido extremadamente tolerante a fallas con redundancia nativa, suponiendo que el hardware falle con frecuencia. La recuperación ante desastres en HBase suele presentarse de varias formas:
- Falla catastrófica a nivel del centro de datos, que requiere conmutación por error a una ubicación de respaldo
- Necesita restaurar una copia anterior de sus datos debido a un error del usuario o una eliminación accidental
- La capacidad de restaurar una copia puntual de sus datos con fines de auditoría
Al igual que con cualquier plan de recuperación ante desastres, los requisitos comerciales determinarán cómo se diseña el plan y cuánto dinero invertir en él. Una vez que haya establecido las copias de seguridad de su elección, la restauración toma diferentes formas según el tipo de recuperación requerida:
- Conmutación por error al clúster de copia de seguridad
- Importar tabla/Restaurar una instantánea
- Dirigir el directorio raíz de HBase a la ubicación de la copia de seguridad
Si su estrategia de copia de seguridad es tal que ha replicado sus datos de HBase en un clúster de copia de seguridad en un centro de datos diferente, la conmutación por error es tan fácil como apuntar sus aplicaciones de usuario final al clúster de copia de seguridad con técnicas de DNS.
Tenga en cuenta, sin embargo, que si planea permitir que los datos se escriban en su clúster de respaldo durante el período de interrupción, deberá asegurarse de que los datos regresen al clúster principal cuando finalice la interrupción. La replicación de maestro a maestro o cíclica manejará este proceso automáticamente por usted, pero un esquema de replicación maestro-esclavo dejará su clúster maestro sin sincronizar, lo que requerirá una intervención manual después de la interrupción.
Junto con la función Exportar descrita anteriormente, hay una herramienta Importar correspondiente que puede tomar los datos previamente respaldados por Exportación y restaurarlos en una tabla HBase. Las mismas implicaciones de rendimiento que se aplicaron a la exportación también están en juego con la importación. Si su esquema de copia de seguridad implicaba tomar instantáneas, volver a una copia anterior de sus datos es tan simple como restaurar esa instantánea.
También puede recuperarse de un desastre simplemente modificando la propiedad hbase.root.dir en hbase-site.xml y apuntando a una copia de seguridad de su directorio /hbase si ha hecho la copia sin conexión de fuerza bruta de las estructuras de datos HDFS . Sin embargo, esta es también la opción de restauración menos deseable, ya que requiere una interrupción prolongada mientras copia toda la estructura de datos en su clúster de producción y, como se mencionó anteriormente, .META. podría no estar sincronizado.
Conclusión
En resumen, la recuperación de datos después de algún tipo de pérdida o interrupción requiere un plan BDR bien diseñado. Le recomiendo que comprenda a fondo los requisitos de su negocio en cuanto a tiempo de actividad, precisión/disponibilidad de datos y recuperación ante desastres. Armado con un conocimiento detallado de los requisitos de su negocio, puede elegir cuidadosamente las herramientas que mejor satisfagan esas necesidades.
Sin embargo, seleccionar las herramientas es solo el comienzo. Debe ejecutar pruebas a gran escala de su estrategia de BDR para asegurarse de que funcione funcionalmente en su infraestructura, satisfaga sus necesidades comerciales y que sus equipos de operaciones estén muy familiarizados con los pasos necesarios antes de que ocurra una interrupción y descubra por las malas que su plan BDR no funcionará.
Si desea comentar o discutir más sobre este tema, use nuestro foro comunitario para HBase.
Lecturas adicionales:
- Presentación de Strata + Hadoop World 2012 de Jon Hsieh
- HBase:la guía definitiva (Lars George)
- HBase en acción (Nick Dimiduk/Amandeep Khurana)



