Obtenga más información sobre la arquitectura de ingesta de datos casi en tiempo real para transformar y enriquecer los flujos de datos mediante Apache Flume, Apache Kafka y RocksDB en Santander, Reino Unido.
Cloudera Professional Services ha estado trabajando con Santander UK para construir un sistema de análisis transaccional casi en tiempo real (NRT) en Apache Hadoop. El objetivo es capturar, transformar, enriquecer, contabilizar y almacenar una transacción a los pocos segundos de realizada la compra con tarjeta. El sistema recibe las transacciones de tarjetas de los clientes minoristas del banco y calcula la información de tendencia asociada agregada por titular de la cuenta y sobre una serie de dimensiones y taxonomías. Luego, esta información se envía de forma segura a la aplicación "Spendlytics" de Santander (ver a continuación) para permitir que los clientes analicen sus patrones de gasto más recientes.
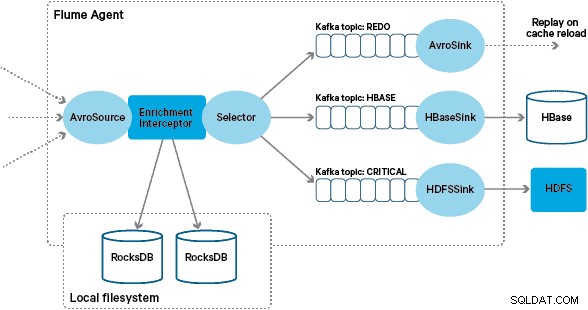
Apache HBase fue elegido como la solución de almacenamiento subyacente debido a su capacidad para admitir escrituras aleatorias de alto rendimiento y lecturas aleatorias de baja latencia. Sin embargo, el requisito de NRT descartó realizar transformaciones y enriquecimiento de las transacciones por lotes, por lo que deben realizarse mientras las transacciones se transmiten a HBase. Esto incluye transformar mensajes de XML a Avro y enriquecerlos con información de tendencia, como información de marca y comerciante.
Esta publicación describe cómo Santander usa Apache Flume, Apache Kafka y RocksDB para transformar, enriquecer y transmitir transacciones en HBase. Esta es una implementación del Procesamiento de eventos NRT con contexto externo patrón de transmisión descrito por Ted Malaska en esta publicación.
Flafka
La primera decisión que tuvo que tomar Santander fue la mejor forma de transmitir datos a HBase. Flume es casi siempre la mejor opción para transmitir la ingestión en Hadoop debido a su simplicidad, confiabilidad, gran variedad de fuentes y sumideros, y escalabilidad inherente.
Recientemente, se ha agregado una excelente integración con Kafka que lleva al inevitablemente llamado Flafka. Flume puede proporcionar de forma nativa la entrega garantizada de eventos a través de su canal de archivos, pero la capacidad de reproducir eventos y la flexibilidad adicional y la preparación para el futuro que ofrece Kafka fueron factores clave para la integración.
En esta arquitectura, Santander utiliza los canales de Kafka para proporcionar un búfer de ingesta confiable, autoequilibrado y escalable en el que todas las transformaciones y el procesamiento se representan en temas de Kafka encadenados. En particular, hacemos un uso extensivo de la fuente y el sumidero de Flafka, y la capacidad de Flume para realizar el procesamiento en vuelo utilizando Interceptors. Esto evitó que tuviéramos que codificar nuestro propio productor y consumidor de Kafka, y permitió a Santander aprovechar al máximo Cloudera Manager para configurar, implementar y monitorear a los agentes y corredores.
Transformación
Las transacciones capturadas por los sistemas bancarios centrales se entregan a Flume como mensajes XML, después de haber sido leídas de la base de datos de origen a través de la replicación de registros. (Seguir un registro de base de datos en temas de Kafka de esta manera es un patrón cada vez más común y, combinado con la compactación de registros, puede brindar una "vista más reciente" de la base de datos para casos de uso de captura de datos modificados).
Flume almacena estos mensajes XML en un tema de Kafka "en bruto". A partir de aquí, y como precursor de todos los demás procesamientos, se decidió transformar el XML semiestructurado en registros binarios estructurados para facilitar el procesamiento posterior estandarizado. Este procesamiento lo realiza un Flume Interceptor personalizado que transforma los mensajes XML en una representación Avro genérica, aplicando tipos específicos cuando corresponde y recurriendo a una representación de cadena cuando no. Todo el procesamiento posterior de NRT luego almacena los resultados derivados en Avro en temas dedicados de Kafka, lo que facilita acceder a la transmisión y obtener una fuente de eventos en cualquier punto de la cadena de procesamiento.
Si se requiriera un procesamiento de eventos más complejo, por ejemplo, agregaciones con Spark Streaming, sería una cuestión trivial consumir uno o más de estos temas y publicarlos en nuevos temas derivados. (Apache Avro es una opción natural para este formato:es un protocolo binario compacto que admite la evolución del esquema, tiene una definición de esquema flexible y es compatible con toda la pila de Hadoop. Avro se está convirtiendo rápidamente en un estándar de facto para el almacenamiento de datos provisionales y generales en un centro de datos empresarial y está perfectamente ubicado para la transformación en Apache Parquet para cargas de trabajo de análisis).
Enriquecimiento
La inspiración para el diseño de la solución de enriquecimiento de transmisión provino de una publicación de O'Reilly Radar escrita por Jay Kreps. En su publicación, Jay describe los beneficios de usar una tienda local para permitir que un procesador de flujo consulte o modifique un estado local en respuesta a su entrada, en lugar de realizar llamadas remotas a una base de datos distribuida.
En Santander, adaptamos este patrón para proporcionar tiendas de referencia locales que se utilizan para consultar y enriquecer las transacciones a medida que se transmiten a través de Flume. ¿Por qué no utilizar simplemente HBase como almacén de referencia? Bueno, un patrón típico para este tipo de problema es simplemente almacenar el estado en HBase y hacer que el mecanismo de enriquecimiento lo consulte directamente. Decidimos en contra de este enfoque por un par de razones. En primer lugar, los datos de referencia son relativamente pequeños y caben en una sola región HBase, lo que probablemente cause un punto crítico de la región. En segundo lugar, HBase sirve la aplicación Spendlytics orientada al cliente y Santander no quería que la carga adicional afectara la latencia de la aplicación, o viceversa. Esta es también la razón por la que decidimos no usar HBase ni siquiera para iniciar las tiendas locales al inicio.
Por lo tanto, al proporcionar a cada Flume Agent una tienda local rápida para enriquecer los eventos durante el vuelo, Santander puede ofrecer mejores garantías de rendimiento tanto para el enriquecimiento durante el vuelo como para la aplicación Spendlytics. Decidimos usar RocksDB para implementar las tiendas locales porque puede proporcionar un acceso rápido a grandes cantidades de datos fuera del montón (eliminando la carga de GC) y el hecho de que tiene una API de Java para que sea más fácil de usar desde un interceptor de canal personalizado. Este enfoque nos salvó de tener que codificar nuestro propio almacén fuera del montón. RocksDB se puede cambiar fácilmente por otra implementación de tienda local, pero en este caso encajaba perfectamente con el caso de uso de Santander.
La implementación personalizada del interceptor de enriquecimiento de Flume procesa los eventos del tema "transformado" ascendente, consulta su almacén local para enriquecerlos y escribe los resultados en los temas Kafka descendentes según el resultado. Este proceso se ilustra con más detalle a continuación.
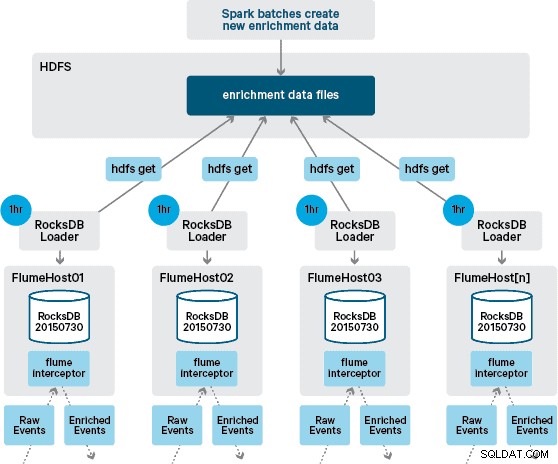
En este punto, es posible que se pregunte:sin persistencia proporcionada por HBase, ¿cómo se generan las tiendas locales? Los datos de referencia comprenden una serie de conjuntos de datos diferentes que deben unirse. Estos conjuntos de datos se actualizan en HDFS diariamente y forman la entrada a una aplicación Apache Spark programada, que genera las tiendas RocksDB. Las tiendas RocksDB recién generadas se organizan en HDFS hasta que los agentes de Flume las descargan para garantizar que el flujo de eventos se enriquezca con la información más reciente.
Idealmente, no tendríamos que esperar a que todos estos conjuntos de datos estén disponibles en HDFS antes de poder procesarlos. Si este fuera el caso, las actualizaciones de los datos de referencia podrían transmitirse a través de la canalización de Flafka para mantener continuamente el estado de los datos de referencia locales.
En nuestro diseño inicial, habíamos planeado escribir y programar a través de cron una secuencia de comandos para sondear HDFS para buscar nuevas versiones de las tiendas RocksDB, descargándolas de HDFS cuando estén disponibles. Aunque debido a los controles internos y la gobernanza de los entornos de producción de Santander, este mecanismo tuvo que incorporarse en el mismo Flume Interceptor que se utiliza para realizar el enriquecimiento (verifica actualizaciones una vez por hora, por lo que no es una operación costosa). Cuando hay disponible una nueva versión de la tienda, se envía una tarea a un subproceso de trabajo para descargar la nueva tienda de HDFS y cargarla en RocksDB. Este proceso ocurre en segundo plano mientras el interceptor de enriquecimiento continúa procesando la transmisión. Una vez que la nueva versión de la tienda se carga en RocksDB, Interceptor cambia a la última versión y la tienda caducada se elimina. El mismo mecanismo se utiliza para iniciar las tiendas RocksDB desde un inicio en frío antes de que el Interceptor comience a intentar enriquecer los eventos.
Los mensajes enriquecidos con éxito se escriben en un tema de Kafka para que se escriban de manera idempotente en HBase utilizando HBaseEventSerializer.
Si bien el flujo de eventos se procesa de forma continua, las nuevas versiones de la tienda local solo se pueden generar diariamente. Inmediatamente después de que Flume haya cargado una nueva versión de la tienda local, se considera nueva”, aunque se vuelve cada vez más obsoleta antes de la disponibilidad de una nueva versión. En consecuencia, el número de "errores de caché" aumenta hasta que esté disponible una versión más nueva de la tienda local. Por ejemplo, se puede agregar información nueva y actualizada de la marca y del comerciante a los datos de referencia, pero hasta que esté disponible para el Interceptor de enriquecimiento de Flume, las transacciones pueden no enriquecerse o enriquecerse con información desactualizada que luego debe ser conciliado después de que se haya conservado en HBase.
Para manejar este caso, los errores de caché (eventos que no se enriquecen) se escriben en un tema de Kafka "rehacer" mediante un selector de canal. El tema de rehacer se vuelve a reproducir en el tema de origen del Interceptor de enriquecimiento cuando hay una nueva tienda local disponible.
Para evitar los "mensajes dudosos" (eventos que continuamente fallan en el enriquecimiento), decidimos agregar un contador al encabezado de un evento antes de agregarlo al tema de rehacer. Los eventos que aparecen repetidamente sobre ese tema finalmente se redirigen a un tema "crítico", que se escribe en HDFS para su posterior inspección y corrección. Este enfoque se ilustra en el primer diagrama.
Conclusión
Para resumir los puntos principales de esta publicación:
- Usar una cadena de temas de Kafka para almacenar datos compartidos intermedios como parte de su proceso de ingesta es un patrón efectivo.
- Tiene varias opciones para conservar y consultar datos de referencia o de estado en su canalización de ingesta de NRT. Favorezca HBase para este propósito como el patrón común cuando los datos complementarios son grandes, pero considere el uso de almacenes locales integrados (como RocksDB) o memoria JVM cuando no sea práctico usar HBase.
- El manejo de fallas es importante. (Consulte el n.° 1 para obtener ayuda al respecto).
En una publicación de seguimiento, describiremos cómo hacemos uso de los coprocesadores HBase para proporcionar agregaciones por cliente de tendencias de compra históricas, y cómo las transacciones fuera de línea se procesan por lotes usando (proyecto Cloudera Labs) SparkOnHBase (que se comprometió recientemente en el troncal HBase). También describiremos cómo se diseñó la solución para cumplir con los requisitos de alta disponibilidad entre centros de datos del cliente.
James Kinley, Ian Buss y Rob Siwicki son arquitectos de soluciones en Cloudera.



