¿Ansioso por aprender todo sobre Hadoop Cluster?
Hadoop es un marco de software para analizar y almacenar grandes cantidades de datos en grupos de hardware básico. En este artículo, estudiaremos un Hadoop Cluster.
Comencemos primero con una introducción a Cluster.
¿Qué es un clúster?
Un clúster es una colección de nodos. Los nodos no son más que un punto de conexión/intersección dentro de una red.
Un clúster de computadoras es una colección de computadoras conectadas a una red, capaces de comunicarse entre sí y que funcionan como un solo sistema.
¿Qué es el clúster de Hadoop?
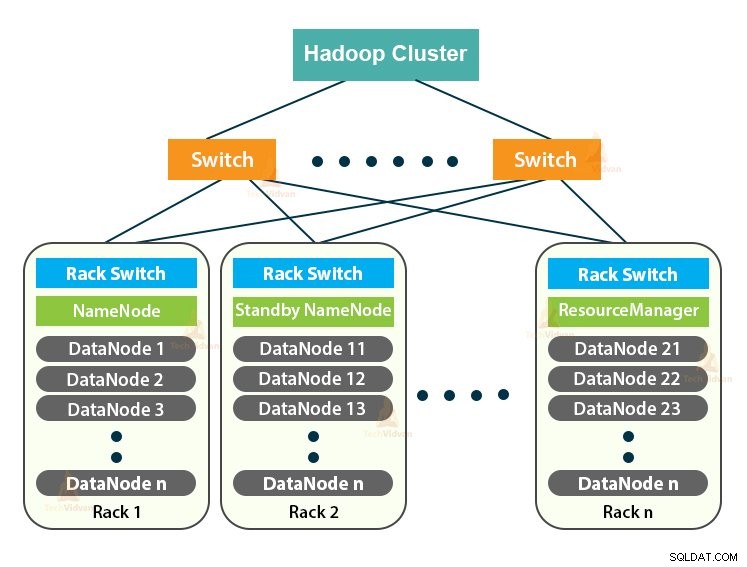
Hadoop Cluster es solo un clúster de computadoras utilizado para manejar una gran cantidad de datos de manera distribuida.
Es un clúster computacional diseñado para almacenar y analizar grandes cantidades de datos estructurados o no estructurados en un entorno informático distribuido.
Los clústeres de Hadoop también se conocen como sistemas sin nada compartido. porque nada se comparte entre los nodos del clúster excepto el ancho de banda de la red. Esto disminuye la latencia de procesamiento.
Por lo tanto, cuando es necesario procesar consultas sobre una gran cantidad de datos, la latencia de todo el clúster se minimiza.
Estudiemos ahora la Arquitectura de Hadoop Cluster.
Arquitectura del Clúster Hadoop
Hadoop Cluster sigue una arquitectura maestro-esclavo. Consta del nodo maestro, los nodos esclavos y el nodo cliente.
1. Máster en Clúster Hadoop
Master in the Hadoop Cluster es una máquina de alta potencia con una alta configuración de memoria y CPU. Los dos demonios que son NameNode y ResourceManager se ejecutan en el nodo maestro.
a. Funciones de NameNode
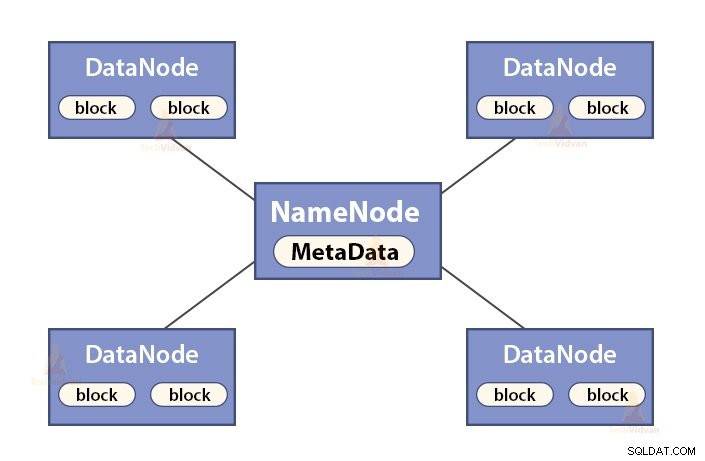
NameNode es un nodo maestro en Hadoop HDFS . NameNode administra el espacio de nombres del sistema de archivos. Almacena metadatos del sistema de archivos en la memoria para una recuperación rápida. Por lo tanto, debe configurarse en máquinas de gama alta.
Las funciones de NameNode son:
- Gestiona el espacio de nombres del sistema de archivos
- Almacena metadatos sobre bloques de un archivo, ubicación de bloques, permisos, etc.
- Ejecuta las operaciones del espacio de nombres del sistema de archivos, como abrir, cerrar, renombrar archivos y directorios, etc.
- Mantiene y administra el DataNode.
b. Funciones del administrador de recursos
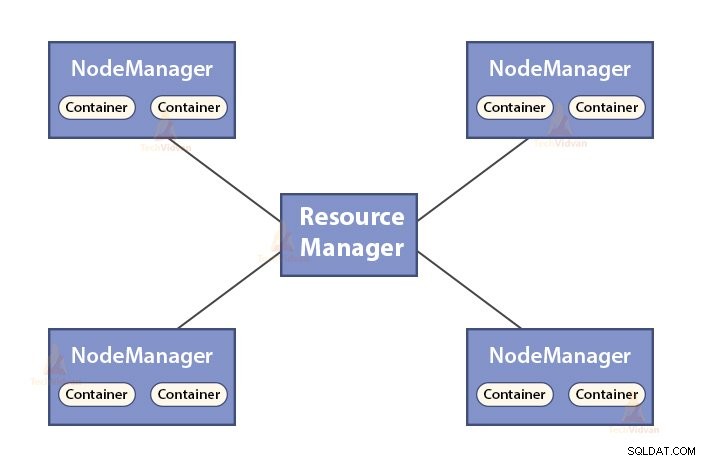
- ResourceManager es el demonio maestro de YARN.
- ResourceManager arbitra los recursos entre todas las aplicaciones del sistema.
- Realiza un seguimiento de los nodos vivos y muertos en el clúster.
2. Esclavos en el clúster de Hadoop
Los esclavos en Hadoop Cluster son hardware básico económico. Los dos demonios que son DataNodes y YARN NodeManagers se ejecutan en los nodos esclavos.
a. Funciones de los nodos de datos
- DataNodes almacena los datos comerciales reales. Almacena los bloques de un archivo.
- Realiza la creación, eliminación y replicación de bloques según las instrucciones de NameNode.
- DataNode es responsable de atender las operaciones de lectura/escritura del cliente.
b. Funciones de NodeManager
- NodeManager es el demonio esclavo de YARN.
- Es responsable de los contenedores, monitorea su uso de recursos (como CPU, disco, memoria, red) e informa al ResourceManager.
- El NodeManager también comprueba el estado del nodo en el que se está ejecutando.
3. Nodo de cliente en Hadoop Cluster
Los nodos de cliente en Hadoop no son nodos maestros ni nodos esclavos. Tienen Hadoop instalado en ellos con todas las configuraciones del clúster.
Funciones de los nodos Cliente
- Los nodos de cliente cargan datos en Hadoop Cluster.
- Envía trabajos de MapReduce, describiendo cómo se deben procesar esos datos.
- Recuperar los resultados del trabajo después de completar el procesamiento.
Podemos escalar el clúster de Hadoop agregando más nodos. Esto hace que Hadoop sea escalable linealmente . Con cada adición de nodo, obtenemos un aumento correspondiente en el rendimiento. Si tenemos 'n' nodos, agregar 1 nodo proporciona (1/n) potencia informática adicional.
Clúster de Hadoop de un solo nodo VS Clúster de Hadoop de varios nodos
1. Clúster de Hadoop de un solo nodo
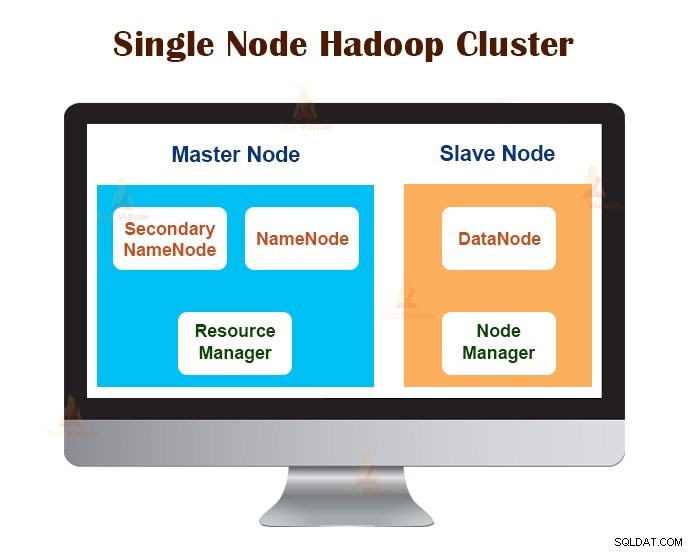
El clúster de Hadoop de un solo nodo se implementa en una sola máquina. Todos los demonios como NameNode, DataNode, ResourceManager, NodeManager se ejecutan en la misma máquina/host.
En una configuración de clúster de un solo nodo, todo se ejecuta en una sola instancia de JVM. El usuario de Hadoop no tuvo que realizar ningún ajuste de configuración excepto establecer la variable JAVA_HOME.
El factor de replicación predeterminado para un clúster de Hadoop de un solo nodo siempre es 1.
2. Clúster de Hadoop de varios nodos
El clúster de Hadoop de varios nodos se implementa en varias máquinas. Todos los demonios en el clúster Hadoop de múltiples nodos están activos y se ejecutan en diferentes máquinas/hosts.
Un clúster Hadoop de múltiples nodos sigue una arquitectura maestro-esclavo. Los demonios Namenode y ResourceManager se ejecutan en los nodos maestros, que son máquinas informáticas de alta gama.
Los daemons DataNodes y NodeManagers se ejecutan en los nodos esclavos (nodos trabajadores), que son hardware básico económico.
En el clúster Hadoop de múltiples nodos, las máquinas esclavas pueden estar presentes en cualquier ubicación, independientemente de la ubicación física del servidor maestro.
Protocolos de comunicación utilizados en Hadoop Cluster
Los protocolos de comunicación HDFS están superpuestos al protocolo TCP/IP. Un cliente establece una conexión con NameNode a través del puerto TCP configurable en la máquina NameNode.
Hadoop Cluster establece una conexión con el cliente a través de ClientProtocol. Además, el DataNode se comunica con el NameNode mediante el protocolo DataNode.
La abstracción de llamada a procedimiento remoto (RPC) envuelve el protocolo de cliente y el protocolo de nodo de datos. Por diseño, NameNode no inicia ningún RPC. Solo responde a las solicitudes de RPC emitidas por los clientes o DataNodes.
Mejores prácticas para construir Hadoop Cluster
El rendimiento de un Hadoop Cluster depende de varios factores basados en los recursos de hardware bien dimensionados que usan CPU, memoria, ancho de banda de red, disco duro y otras capas de software bien configuradas.
Construir un Hadoop Cluster no es un trabajo trivial. Requiere la consideración de varios factores, como elegir el hardware adecuado, dimensionar los clústeres de Hadoop y configurar el clúster de Hadoop.
Veamos ahora cada uno en detalle.
1. Elección del hardware adecuado para Hadoop Cluster
Muchas organizaciones, al configurar la infraestructura de Hadoop, se encuentran en una situación difícil, ya que no conocen el tipo de máquinas que deben comprar para configurar un entorno de Hadoop optimizado y la configuración ideal que deben usar.
Para elegir el hardware adecuado para Hadoop Cluster, se deben considerar los siguientes puntos:
- El volumen de datos que manejará ese clúster.
- El tipo de cargas de trabajo que manejará el clúster (límite de CPU, límite de E/S).
- Metodología de almacenamiento de datos, como contenedores de datos, técnicas de compresión de datos utilizadas, si corresponde.
- Una política de retención de datos, es decir, cuánto tiempo queremos conservar los datos antes de eliminarlos.
2. Dimensionamiento del clúster de Hadoop
Para determinar el tamaño del clúster de Hadoop, el volumen de datos que los usuarios de Hadoop procesarán en el clúster de Hadoop debe ser una consideración clave.
Al conocer el volumen de datos a procesar, ayuda a decidir cuántos nodos se requerirán para procesar los datos de manera eficiente y la capacidad de memoria requerida para cada nodo. Debe haber un equilibrio entre el rendimiento y el costo del hardware aprobado.
3. Configuración del clúster de Hadoop
Encontrar la configuración ideal para Hadoop Cluster no es un trabajo fácil. El marco Hadoop debe adaptarse al clúster que se está ejecutando y también al trabajo.
La mejor manera de decidir la configuración ideal para Hadoop Cluster es ejecutar los trabajos de Hadoop con la configuración predeterminada disponible para obtener una línea de base. Después de eso, podemos analizar los archivos de registro del historial de trabajos para ver si hay algún recurso débil o si el tiempo necesario para ejecutar los trabajos es más alto de lo esperado.
Si es así, cambie la configuración. Repetir el mismo proceso puede ajustar la configuración de Hadoop Cluster que mejor se adapte a los requisitos comerciales.
El rendimiento de Hadoop Cluster depende en gran medida de los recursos asignados a los demonios. Para contextos de datos pequeños a medianos, Hadoop reserva un núcleo de CPU en cada DataNode, mientras que, para conjuntos de datos largos, asigna 2 núcleos de CPU en cada DataNode para demonios HDFS y MapReduce.
Administración de clústeres de Hadoop
Al implementar Hadoop Cluster en producción, es evidente que debe escalar en todas las dimensiones que son volumen, variedad y velocidad.
Varias características que debe poseer para estar listo para la producción son:disponibilidad las 24 horas, robustez, capacidad de administración y rendimiento. La gestión de Hadoop Cluster es la faceta principal de la iniciativa de big data.
La mejor herramienta para la gestión de Hadoop Cluster debe tener las siguientes características:-
- Debe garantizar una alta disponibilidad las 24 horas, los 7 días de la semana, el aprovisionamiento de recursos, la seguridad diversa, la gestión de la carga de trabajo, la supervisión del estado y la optimización del rendimiento. Además, debe proporcionar programación de trabajos, gestión de políticas, copia de seguridad y recuperación en uno o más nodos.
- Implemente alta disponibilidad de NameNode de HDFS redundante con balanceo de carga, espera activa, resincronización y conmutación por error automática.
- Hacer cumplir los controles basados en políticas que evitan que cualquier aplicación obtenga una parte desproporcionada de los recursos en un Hadoop Cluster que ya está al máximo.
- Realización de pruebas de regresión para administrar la implementación de cualquier capa de software en clústeres de Hadoop. Esto es para asegurarse de que ningún trabajo o datos se bloqueen o encuentren cuellos de botella en las operaciones diarias.
Beneficios del clúster de Hadoop
Los diversos beneficios proporcionados por Hadoop Cluster son:
1. Escalable
Los clústeres de Hadoop son escalables. Podemos agregar cualquier cantidad de nodos al Hadoop Cluster sin tiempo de inactividad y sin ningún esfuerzo adicional. Con cada adición de nodo, obtenemos un aumento correspondiente en el rendimiento.
2. Robustez
Hadoop Cluster es mejor conocido por su almacenamiento confiable. Puede almacenar datos de manera confiable, incluso en casos como falla de DataNode, falla de NameNode y partición de red. El DataNode envía periódicamente una señal de latido al NameNode.
En la partición de red, un conjunto de DataNodes se separa del NameNode debido a que NameNode no recibe ningún latido de estos DataNodes. NameNode luego considera estos DataNodes como inactivos y no les envía ninguna solicitud de E/S.
Además, el factor de replicación de los bloques almacenados en estos DataNodes cae por debajo de su valor especificado. Como resultado, NameNode luego inicia la replicación de estos bloques y se recupera de la falla.
3. Reequilibrio de clústeres
La arquitectura Hadoop HDFS realiza automáticamente el reequilibrio del clúster. Si el espacio libre en el DataNode cae por debajo del nivel de umbral, entonces la arquitectura HDFS mueve automáticamente algunos datos a otro DataNode donde hay suficiente espacio disponible.
4. Rentable
La configuración de Hadoop Cluster es rentable porque incluye hardware básico económico. Cualquier organización puede configurar fácilmente un clúster de Hadoop potente sin gastar mucho en hardware de servidor costoso.
Además, Hadoop Clusters con su topología de almacenamiento distribuido supera las limitaciones del sistema tradicional. El almacenamiento limitado se puede ampliar simplemente agregando unidades de almacenamiento económicas adicionales al sistema.
5. flexibles
Los clústeres de Hadoop son muy flexibles, ya que pueden procesar datos de cualquier tipo, ya sea estructurados, semiestructurados o no estructurados, y de cualquier tamaño, desde gigabytes hasta petabytes.
6. Procesamiento rápido
En Hadoop Cluster, los datos se pueden procesar en paralelo en un entorno distribuido. Esto proporciona capacidades de procesamiento de datos rápidos para Hadoop. Los clústeres de Hadoop pueden procesar Terabytes o Petabytes de datos en una fracción de segundos.
7. Integridad de datos
Para verificar si hay corrupción en los bloques de datos debido a errores de software, fallas en un dispositivo de almacenamiento, etc., Hadoop Cluster implementa una suma de verificación en cada bloque del archivo. Si encuentra algún bloque corrupto, lo busca de otro DataNode que contenga la réplica del mismo bloque. Por lo tanto, Hadoop Cluster mantiene la integridad de los datos.
Resumen
Después de leer este artículo, podemos decir que Hadoop Cluster es un clúster computacional especial diseñado para analizar y almacenar big data. Hadoop Cluster sigue la arquitectura maestro-esclavo.
El nodo maestro es la máquina informática de gama alta, y los nodos esclavos son máquinas con CPU y configuración de memoria normales. También hemos visto que Hadoop Cluster se puede configurar en una sola máquina llamada Hadoop Cluster de un solo nodo o en varias máquinas llamadas Hadoop Cluster de varios nodos.
En este artículo, también cubrimos las mejores prácticas que se deben seguir al construir un Hadoop Cluster. También habíamos visto muchas ventajas del Hadoop Cluster, incluida la escalabilidad, la flexibilidad, la rentabilidad, etc.



