Este tutorial de Hadoop se trata de MapReduce Shuffling and Sorting. Aquí le proporcionaremos una descripción detallada de la fase de clasificación y barajado de Hadoop.
En primer lugar, discutiremos qué es MapReduce Shuffling, luego MapReduce Sorting, luego cubriremos la fase de clasificación secundaria de MapReduce en detalle.
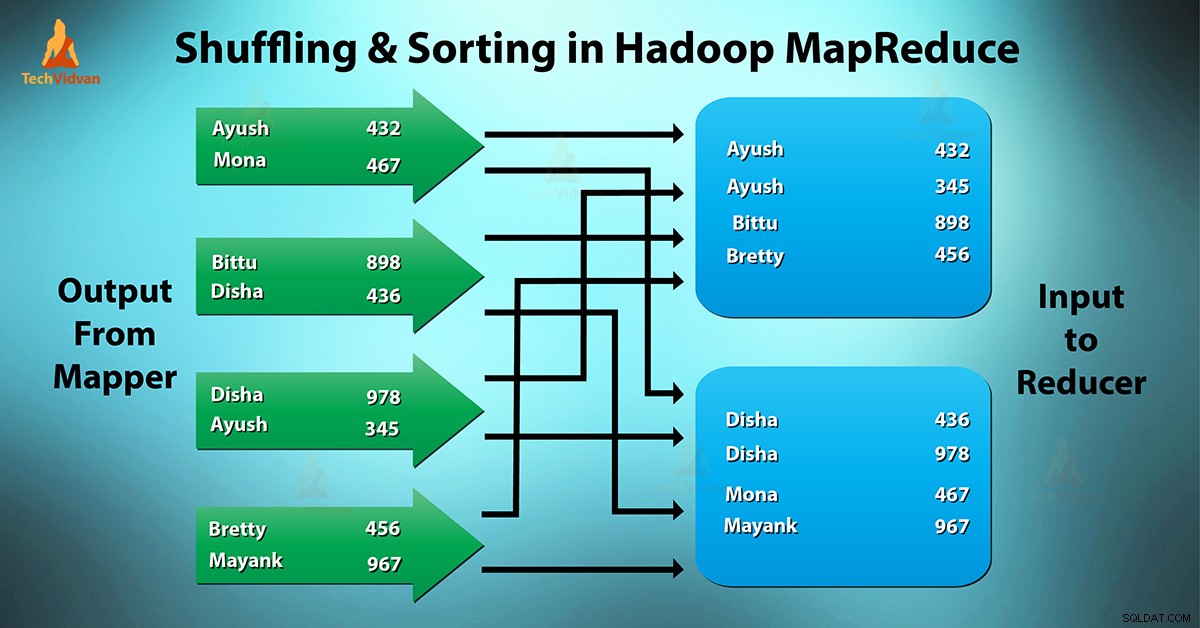
¿Qué es MapReduce Shuffling y Sorting?
Barajar es el proceso por el cual transfiere mapeadores salida intermedia al reductor. Reducer obtiene 1 o más claves y valores asociados sobre la base de reducers.
La clave intermediada:el valor generado por el mapeador se ordena automáticamente por clave. En la fase de clasificación, se lleva a cabo la combinación y clasificación de la salida del mapa.
La ordenación aleatoria y la clasificación en Hadoop ocurren simultáneamente.
Mezclar en MapReduce
El proceso de transferencia de datos de los mapeadores a los reductores es aleatorio. También es el proceso por el cual el sistema realiza la clasificación. Luego transfiere la salida del mapa al reductor como entrada. Esta es la razón por la cual la fase de reproducción aleatoria es necesaria para los reductores.
De lo contrario, no tendrían ninguna entrada (o entrada de cada mapeador). Dado que el barajado puede comenzar incluso antes de que finalice la fase del mapa. Esto ahorra algo de tiempo y completa las tareas en menos tiempo.
Ordenar en MapReduce
MapReduce Framework ordena automáticamente las claves generadas por el mapeador. Por lo tanto, antes de iniciar reducer, todos los pares clave-valor intermedios se ordenan por clave y no por valor. No ordena los valores pasados a cada reductor. Pueden estar en cualquier orden.
Ordenar en un trabajo de MapReduce ayuda a Reducer a distinguir fácilmente cuándo debe comenzar una nueva tarea de reducción.
Esto ahorra tiempo para el reductor. Reducer en MapReduce inicia una nueva tarea de reducción cuando la siguiente clave en los datos de entrada ordenados es diferente a la anterior. Cada tarea reduce toma pares clave-valor como entrada y genera pares clave-valor como salida.
Lo importante a tener en cuenta es que el barajado y la clasificación en Hadoop MapReduce no se llevarán a cabo si especifica cero reductores (setNumReduceTasks(0)).
Si reducer es cero, entonces el trabajo de MapReduce se detiene en la fase de mapa. Y la fase del mapa no incluye ningún tipo de clasificación (incluso la fase del mapa es más rápida).
Clasificación secundaria en MapReduce
Si queremos ordenar los valores de reducción, entonces usamos una técnica de clasificación secundaria. Esta técnica nos permite ordenar los valores (en orden ascendente o descendente) pasados a cada reductor.
Conclusión
En conclusión, MapReduce Shuffling y Sorting ocurren simultáneamente para resumir la salida intermedia de Mapper. La clasificación aleatoria de Hadoop no tendrá lugar si especifica cero reductores (setNumReduceTasks (0)).
Framework ordena todos los pares clave-valor intermedios por clave, no por valor. Utiliza clasificación secundaria para clasificar por valor. Si tiene alguna sugerencia o consulta relacionada con la fase de reproducción aleatoria y clasificación de MapReduce, deje un comentario en un cuadro de comentarios.
Estaremos encantados de resolverlos.



