En este tutorial de Big Data Hadoop , le proporcionaremos una descripción detallada del bloque de datos Hadoop HDFS. En primer lugar, cubriremos qué es un bloque de datos en Hadoop, cuál es su importancia, por qué el tamaño de los bloques de datos HDFS es de 128 MB.
También discutiremos el ejemplo de bloques de datos en Hadoop y varias ventajas de HDFS en Hadoop.
Introducción al bloque de datos HDFS
HDFS de Hadoop dividir archivos grandes en pequeños fragmentos conocidos como Bloques . El bloque es la representación física de los datos. Contiene una cantidad mínima de datos que se pueden leer o escribir. HDFS almacena cada archivo como bloques. El cliente HDFS no tiene ningún control sobre el bloque, como la ubicación del bloque, Namenode decide todas esas cosas.
De forma predeterminada, el tamaño del bloque HDFS es 128 MB que puede cambiar según sus necesidades. Todos los bloques HDFS tienen el mismo tamaño excepto el último bloque, que puede ser del mismo tamaño o más pequeño.
El marco Hadoop divide los archivos en bloques de 128 MB y luego los almacena en el sistema de archivos Hadoop. La aplicación Apache Hadoop es responsable de distribuir el bloque de datos en varios nodos.
Ejemplo-
Supongamos que el tamaño del archivo es de 513 MB y estamos usando la configuración predeterminada de tamaño de bloque de 128 MB. Luego, el marco Hadoop creará 5 bloques, los primeros cuatro bloques de 128 MB, pero el último bloque será de solo 1 MB.
Por lo tanto, del ejemplo queda claro que no es necesario que en HDFS cada archivo almacenado deba ser un múltiplo exacto del tamaño de bloque configurado de 128 mb, 256 mb, etc. Por lo tanto, el bloque final para el archivo usa solo el espacio que se necesita.
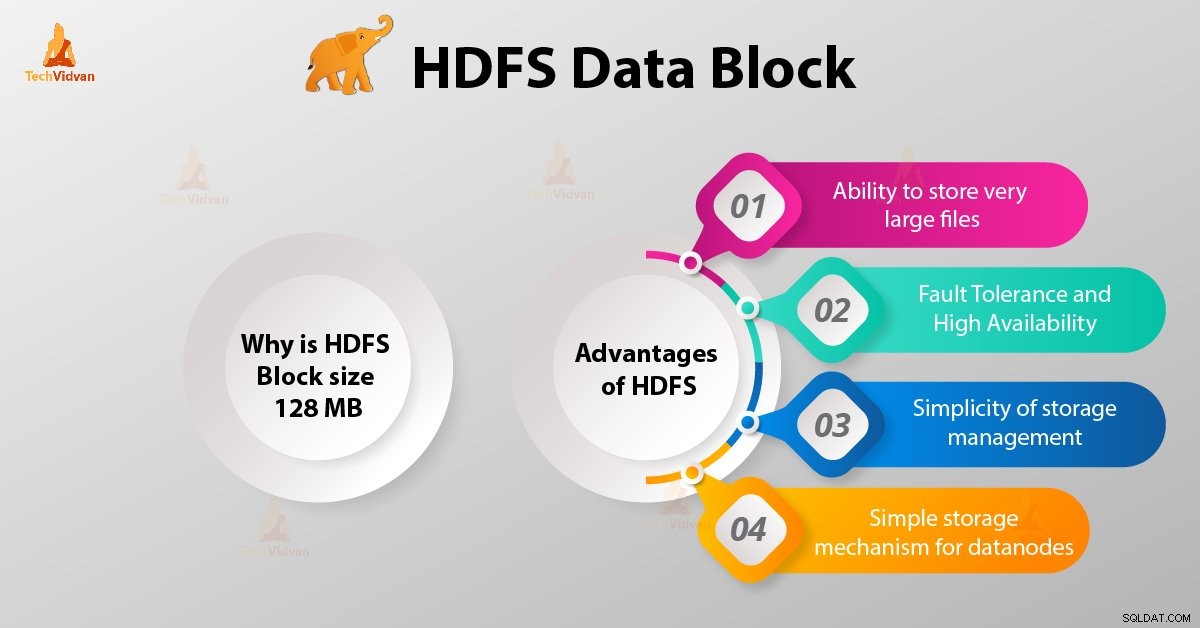
¿Por qué el tamaño del bloque HDFS es de 128 MB?
HDFS almacena terabytes y petabytes de datos. Si el tamaño del bloque HDFS es de 4 kb como el sistema de archivos de Linux, tendremos demasiados bloques de datos en Hadoop HDFS, por lo tanto, demasiados metadatos.
Por lo tanto, mantener y administrar esta gran cantidad de bloques y metadatos generará una gran sobrecarga y tráfico, algo que no queremos.
El tamaño del bloque no puede ser tan grande que el sistema esté esperando mucho tiempo para que una última unidad de procesamiento de datos termine su trabajo.
Ventajas de HDFS
Después de aprender qué es HDFS Data Block, analicemos ahora las ventajas de Hadoop HDFS.
1. Capacidad para almacenar archivos muy grandes
Hadoop HDFS almacena archivos muy grandes que son incluso más grandes que el tamaño de un solo disco, ya que el marco de trabajo de Hadoop divide el archivo en bloques y los distribuye en varios nodos.
2. Tolerancia a fallas y alta disponibilidad de HDFS
El marco Hadoop puede replicar fácilmente bloques entre los nodos de datos. Por lo tanto, proporcione tolerancia a fallos y alta disponibilidad HDFS.
3. Simplicidad de la gestión del almacenamiento
Como HDFS tiene un tamaño de bloque fijo (128 MB), es muy fácil calcular la cantidad de bloques que se pueden almacenar en el disco.
4. Mecanismo de almacenamiento simple para nodos de datos
Block en HDFS simplifica el almacenamiento de los Datanodes . Nodo de nombre mantiene los metadatos de todos los bloques. HDFS Datanode no necesita preocuparse por los metadatos del bloque, como los permisos de archivos, etc.
Conclusión
Por lo tanto, el bloque de datos HDFS es la unidad de datos más pequeña en un sistema de archivos. El tamaño predeterminado del bloque HDFS es de 128 MB, que puede configurar según los requisitos. Los bloques HDFS son fáciles de replicar entre los nodos de datos. Por lo tanto, proporcione tolerancia a fallas y alta disponibilidad de HDFS.
Para cualquier consulta o sugerencia relacionada con los bloques de datos de Hadoop HDFS, háganoslo saber dejando un comentario en la sección que figura a continuación.



