Los sistemas de bases de datos son componentes cruciales en el ciclo de cualquier aplicación que se ejecute con éxito. Por lo tanto, cada organización que los involucre tiene el mandato de garantizar el buen desempeño de estos DBM a través de un monitoreo constante y el manejo de contratiempos menores antes de que se conviertan en enormes complicaciones que pueden resultar en un tiempo de inactividad de la aplicación o un rendimiento lento.
Puede preguntar cómo puede saber si la base de datos realmente va a tener un problema mientras funciona normalmente. Bueno, eso es lo que vamos a discutir en este artículo y lo llamamos evaluación comparativa. La evaluación comparativa consiste básicamente en ejecutar un conjunto de consultas con algunos datos de prueba junto con alguna provisión de recursos para determinar si estos parámetros cumplen con el nivel de rendimiento esperado.
MongoDB no tiene una metodología de evaluación comparativa estándar, por lo que debemos resolver las consultas de prueba en el propio hardware. Por mucho que también pueda obtener cifras impresionantes del proceso de referencia, debe tener cuidado, ya que este puede ser un caso diferente cuando ejecuta su base de datos con consultas reales.
La idea detrás de la evaluación comparativa es obtener una idea general de cómo las diferentes opciones de configuración afectan el rendimiento, cómo puede modificar algunas de estas configuraciones para obtener el máximo rendimiento y estimar el costo de mejorar esta implementación. Además, las aplicaciones crecen con el tiempo en términos de usuarios y, probablemente, la cantidad de datos que se van a servir, por lo que es necesario planificar la capacidad antes de ese momento. Después de darse cuenta de una tendencia al alza de los datos, debe realizar una evaluación comparativa sobre cómo cumplirá con los requisitos de esta gran cantidad de datos en crecimiento.
Consideraciones en Benchmarking MongoDB
- Seleccione cargas de trabajo que sean una representación típica de las aplicaciones modernas de hoy. Las aplicaciones modernas son cada día más complejas y esto se transmite a las estructuras de datos. Es decir, la presentación de datos también ha cambiado con el tiempo, por ejemplo, almacenando campos simples en objetos y matrices. No es muy fácil trabajar con estos datos con configuraciones de base de datos predeterminadas o por debajo del estándar, ya que puede derivar en problemas como latencia deficiente y operaciones de bajo rendimiento que involucran datos complejos. Por lo tanto, al ejecutar un punto de referencia, debe usar datos que sean una presentación clara de su aplicación.
- Compruebe dos veces las escrituras. Siempre asegúrese de que todas las escrituras de datos se hayan realizado de una manera que no permita la pérdida de datos. Esto es para mejorar la integridad de los datos al garantizar que los datos sean consistentes y sean más aplicables, especialmente en el entorno de producción.
- Emplear volúmenes de datos que son una representación de conjuntos de datos de "grandes datos" que ciertamente excederán la capacidad de RAM para un nodo individual. Cuando la carga de trabajo de prueba es grande, lo ayudará a predecir las expectativas futuras del rendimiento de su base de datos, por lo tanto, comience a planificar la capacidad con suficiente anticipación.
Metodología
Nuestra prueba de referencia incluirá algunos datos de ubicación importantes que se pueden descargar desde aquí y usaremos el software Robo3t para manipular nuestros datos y recopilar la información que necesitamos. El archivo tiene más de 500 documentos que son suficientes para nuestra prueba. Estamos usando MongoDB versión 4.0 en un servidor dedicado Ubuntu Linux 12.04 Intel Xeon-SandyBridge E3-1270-Quadcore de 3,4 GHz con 32 GB de RAM, disco giratorio Western Digital WD Caviar RE4 de 1 TB y SSD Smart XceedIOPS de 256 GB. Insertamos los primeros 500 documentos.
Ejecutamos los comandos de inserción a continuación
db.getCollection('location').insertMany([<document1, <document2>…<document500>],{w:0})
db.getCollection('location').insertMany([<document1, <document2>…<document500>],{w:1})Escribir preocupación
Preocupación de escritura describe el nivel de reconocimiento solicitado de MongoDB para operaciones de escritura en este caso a un MongoDB independiente. Para una operación de alto rendimiento, si este valor se establece en un valor bajo, las llamadas de escritura serán tan rápidas que se reducirá la latencia de la solicitud. Por otro lado, si el valor se establece alto, las llamadas de escritura son lentas y, en consecuencia, aumentan la latencia de la consulta. Una explicación simple para esto es que cuando el valor es bajo, no le preocupa la posibilidad de perder algunas escrituras en caso de bloqueo de mongod, error de red o falla anónima del sistema. Una limitación en este caso será que no estará seguro de si estas escrituras fueron exitosas. Por otro lado, si la preocupación de escritura es alta, hay un aviso de manejo de errores y, por lo tanto, se reconocerán las escrituras. Un acuse de recibo es simplemente un recibo de que el servidor aceptó el proceso de escritura.
 Cuando el problema de escritura es alto
Cuando el problema de escritura es alto  Cuando el problema de escritura se establece bajo
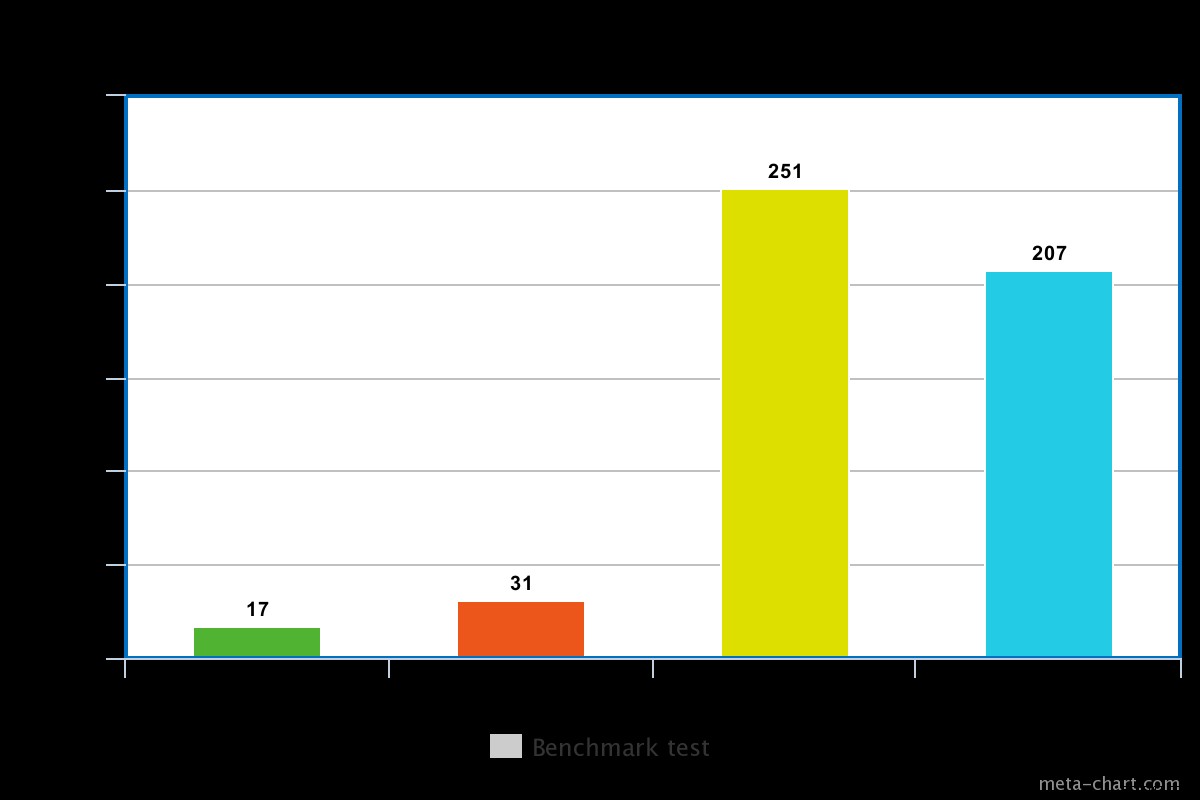
Cuando el problema de escritura se establece bajo En nuestra prueba, el problema de escritura establecido en bajo dio como resultado que la consulta se ejecutara en un mínimo de 0,013 ms y un máximo de 0,017 ms. En este caso, el reconocimiento básico de escritura está deshabilitado, pero aún se puede obtener información sobre las excepciones de socket y cualquier error de red que pueda haberse desencadenado.
Cuando el problema de escritura se establece en un valor alto, casi se tarda el doble de tiempo en volver, siendo el tiempo de ejecución de 0,027 ms min y 0,031 ms max. La confirmación en este caso está garantizada, pero no al 100 %, ya que ha llegado al diario del disco. En este caso, las posibilidades de una pérdida de escritura son, por lo tanto, del 50 % debido a la ventana de 100 ms en la que es posible que el diario no se vacíe en el disco.
Diario
Esta es una técnica para garantizar que no se pierdan datos al proporcionar durabilidad en caso de falla. Esto se logra a través de un registro de escritura anticipada en archivos de diario en disco. Es más eficiente cuando la preocupación de escritura es alta.
Para un disco giratorio, el tiempo de ejecución con el diario habilitado es un poco alto, por ejemplo, en nuestra prueba fue de aproximadamente 0,251 ms para la misma operación anterior.

Sin embargo, el tiempo de ejecución para un SSD es un poco menor para el mismo comando. En nuestra prueba, fue de aproximadamente 0,207 ms, pero dependiendo de la naturaleza de los datos, a veces esto podría ser 3 veces más rápido que un disco giratorio.

Cuando el registro en diario está habilitado, confirma que se han realizado escrituras en el diario y, por lo tanto, garantiza la durabilidad de los datos. En consecuencia, la operación de escritura sobrevivirá a un apagado de mongod y garantiza que la operación de escritura sea duradera.
Para una operación de alto rendimiento, puede reducir a la mitad los tiempos de consulta configurando w=0. De lo contrario, si necesita estar seguro de que los datos se han registrado o, más bien, lo estarán en caso de que vuelvan a funcionar después de una falla, entonces debe configurar w=1.
 Varios nueve Conviértase en un administrador de bases de datos de MongoDB:lleve MongoDB a la producción Obtenga información sobre lo que necesita saber para implementar, monitorear, administrar y scale MongoDBDescargar gratis
Varios nueve Conviértase en un administrador de bases de datos de MongoDB:lleve MongoDB a la producción Obtenga información sobre lo que necesita saber para implementar, monitorear, administrar y scale MongoDBDescargar gratis Replicación
El reconocimiento de un problema de escritura se puede habilitar para más de un nodo que sea el principal y algunos secundarios dentro de un conjunto de réplicas. Esto se caracterizará por qué número entero se valora en el parámetro de escritura. Por ejemplo, si w =3, Mongod debe asegurarse de que la consulta reciba un reconocimiento del nodo principal y 2 esclavos. Si intenta establecer un valor mayor que uno y el nodo aún no se ha replicado, arrojará un error que indica que el host debe replicarse.
La replicación viene con un retraso en la latencia que aumentará el tiempo de ejecución. Para la consulta simple anterior, si w =3, el tiempo de ejecución promedio aumenta a 270 ms. Un factor que impulsa esto es el rango en el tiempo de respuesta entre los nodos afectados por la latencia de la red, la sobrecarga de comunicación entre los 3 nodos y la congestión. Además, los tres nodos esperan a que terminen antes de devolver el resultado. En una implementación de producción, por lo tanto, no necesitará involucrar tantos nodos si desea mejorar el rendimiento. MongoDB es responsable de seleccionar qué nodos se reconocerán a menos que haya una especificación en el archivo de configuración usando etiquetas.
Disco giratorio frente a disco de estado sólido
Como se mencionó anteriormente, el disco SSD es bastante más rápido que el disco giratorio, según los datos involucrados. A veces podría ser 3 veces más rápido, por lo que vale la pena pagarlo si es necesario. Sin embargo, será más costoso usar un SSD, especialmente cuando se trata de una gran cantidad de datos. MongoDB tiene el mérito de admitir el almacenamiento de bases de datos en directorios que se pueden montar, por lo tanto, existe la posibilidad de usar un SSD. Emplear un SSD y habilitar el registro en diario es una gran optimización.
Conclusión
El experimento estaba seguro de que la preocupación de escritura deshabilitada da como resultado un tiempo de ejecución reducido de una consulta a expensas de las posibilidades de pérdida de datos. Por otro lado, cuando la preocupación de escritura está habilitada, el tiempo de ejecución es casi 2 veces mayor que cuando está deshabilitada, pero existe la seguridad de que los datos no se perderán. Además, podemos justificar que SSD es más rápido que un disco giratorio. Sin embargo, para garantizar la durabilidad de los datos en caso de que falle el sistema, se recomienda habilitar la función de escritura. Cuando habilite la preocupación de escritura para un conjunto de réplicas, no configure el número demasiado grande de modo que pueda resultar en un rendimiento degradado desde el final de la aplicación.



