En nuestro Hadoop anterior blogs hemos estudiado cada componente de Hadoop Proceso de MapReduce en detalle. En esto, vamos a discutir el tema muy interesante, es decir, el trabajo Map Only en Hadoop.
En primer lugar, haremos una breve introducción del Mapa y Reducir fase en Hadoop MapReduce, luego discutiremos qué es el trabajo Map only en Hadoop MapReduce.
Por último, también discutiremos las ventajas y desventajas del trabajo Hadoop Map Only en este tutorial.
¿Qué es el trabajo de solo mapa de Hadoop?
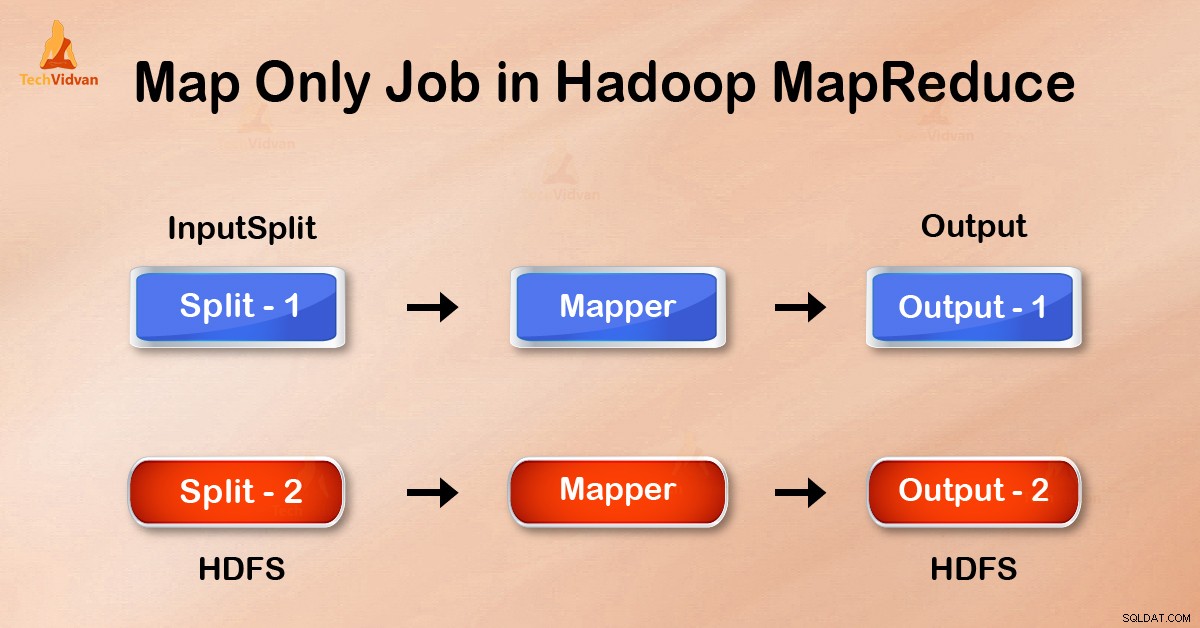
Trabajo de solo mapa en Hadoop es el proceso en el que mapper hace todas las tareas. El reductor no realiza ninguna tarea . La salida de Mapper es la salida final.
MapReduce es la capa de procesamiento de datos de Hadoop. Procesa grandes datos estructurados y no estructurados almacenados en HDFS . MapReduce también procesa una gran cantidad de datos en paralelo.
Para ello, divide el trabajo (trabajo enviado) en un conjunto de tareas independientes (subtrabajo). En Hadoop, MapReduce funciona dividiendo el procesamiento en fases:Mapa y Reducir .
- Mapa: Es la primera fase del procesamiento, donde especificamos todo el código lógico complejo. Toma un conjunto de datos y los convierte en otro conjunto de datos. Divide cada elemento individual en tuplas (pares clave-valor ).
- Reducir: Es la segunda fase del procesamiento. Aquí especificamos un procesamiento ligero como agregación/suma. Toma la salida del mapa como entrada. Luego combina esas tuplas según la clave.
A partir de este ejemplo de conteo de palabras, podemos decir que hay dos conjuntos de procesos paralelos, mapear y reducir. En el proceso del mapa, la primera entrada se divide para distribuir el trabajo entre todos los nodos del mapa, como se muestra arriba.
Luego, Framework identifica cada palabra y la asigna al número 1. Por lo tanto, crea pares llamados pares de tuplas (clave-valor).
En el primer nodo del mapeador, pasa tres palabras león, tigre y el río. Por lo tanto, produce 3 pares clave-valor como salida del nodo. Tres claves y valores diferentes establecidos en 1 y el mismo proceso se repite para todos los nodos.
Luego pasa estas tuplas a los nodos reductores. El particionador lleva a cabo barajar para que todas las tuplas con la misma clave vayan al mismo nodo.
En el proceso de reducción lo que ocurre básicamente es una agregación de valores o más bien una operación sobre valores que comparten la misma clave.
Ahora, consideremos un escenario en el que solo necesitamos realizar la operación. No necesitamos agregación, en tal caso, preferiremos 'Trabajo de solo mapa '.
En el trabajo Map-Only, el mapa realiza todas las tareas con su InputSplit . El reductor no hace ningún trabajo. La salida de Mappers es la salida final.
¿Cómo evitar la fase de reducción en MapReduce?
Configurando job.setNumreduceTasks(0) en la configuración en un controlador podemos evitar reducir la fase. Esto hará que un número de reductor sea 0 . Por lo tanto, el único mapeador estará haciendo la tarea completa.
Ventajas del trabajo Map only en Hadoop
En la ejecución del trabajo de MapReduce, entre las fases de mapa y reducción, hay una fase de clave, ordenación y reproducción aleatoria. Mezclar – Ordenar son los encargados de ordenar las claves en orden ascendente. Luego agrupando valores basados en las mismas claves. Esta fase es muy costosa.
Si no se requiere la fase de reducción, debemos evitarla. Como evitar la fase de reducción también eliminaría la clasificación y la fase de reproducción aleatoria. Por lo tanto, esto también evitará la congestión de la red.
La razón es que al barajar, una salida del mapeador viaja para reducir. Y cuando el tamaño de los datos es enorme, los datos grandes deben viajar al reductor.
La salida del asignador se escribe en el disco local antes de enviarla a reducir. Pero en el trabajo de solo mapa, esta salida se escribe directamente en HDFS. Esto ahorra más tiempo y reduce los costos.
Conclusión
Por lo tanto, hemos visto que el trabajo de solo mapa reduce la congestión de la red al evitar la fase de barajar, clasificar y reducir. Map solo se encarga del procesamiento general y produce la salida. POR usar job.setNumreduceTasks(0) esto se logra.
Espero que haya entendido el trabajo Solo mapa de Hadoop y es importante porque hemos cubierto todo sobre el trabajo Solo mapa en Hadoop. Pero si tiene alguna consulta, puede compartirla con nosotros en la sección de comentarios.



