Los puntos de referencia son una de las actividades que realizan los administradores de bases de datos. Los ejecuta para ver cómo se comporta su hardware, los ejecuta para ver cómo su aplicación y su base de datos funcionan juntas bajo presión. Los ejecutas en muchas situaciones diferentes. Hablemos un poco sobre ellos, cuáles son los desafíos que enfrentará, cuáles son los problemas que debe evitar.
Tipos de puntos de referencia
Cada punto de referencia es diferente. Sirven para diferentes propósitos y debe tenerse en cuenta cuando planea ejecutar uno. En general, puede definir dos tipos principales de puntos de referencia:puntos de referencia sintéticos y, llamémoslos, puntos de referencia del "mundo real".
Los puntos de referencia sintéticos suelen ser herramientas que simulan algún tipo de carga de trabajo. Puede ser una carga de trabajo OLTP como en el caso de Sysbench, puede ser un punto de referencia "estándar" como en TPC-C o TPC-H. Por lo general, la idea es que dicho punto de referencia simule algún tipo de carga de trabajo y podría ser útil si su carga de trabajo del mundo real va a seguir el mismo patrón. También se puede usar para determinar cómo funciona su combinación de hardware y configuración de base de datos bajo un determinado tipo de carga de trabajo. Las ventajas de los puntos de referencia sintéticos son bastante claras. Puede ejecutarlos en todas partes, no dependen de una configuración particular o diseño de esquema. Bueno, lo hacen, pero vienen con herramientas para configurar todo desde el servidor de base de datos vacío. El principal inconveniente es que esta no es su carga de trabajo. Si va a ejecutar pruebas OLTP utilizando Sysbench, debe tener en cuenta que su aplicación nunca será Sysbench. También puede ejecutar la carga de trabajo de OLTP, pero la combinación de consultas será diferente. Nunca, bajo ninguna circunstancia, el punto de referencia sintético le dirá exactamente cómo se comportará su aplicación en una combinación determinada de hardware/configuración.
En el otro extremo del espectro tenemos lo que llamamos puntos de referencia del "mundo real". Lo que queremos decir aquí con eso es un punto de referencia que utiliza un conjunto de datos y consultas relacionadas con su aplicación. No siempre tiene un conjunto de datos completo y una combinación de consultas completa. Es posible que desee centrarse en algunas partes de su aplicación, pero la idea principal detrás de esto es que desea comprender las interacciones exactas entre la configuración de la aplicación, el hardware y la base de datos, ya sea en general o en algún aspecto particular.
Como mencionamos anteriormente, tenemos dos tipos principales y diferentes de puntos de referencia pero, aún así, tienen algunas cosas en común que debe tener en cuenta al intentar ejecutar los puntos de referencia.
-
Decide qué quieres probar
En primer lugar, la evaluación comparativa por el simple hecho de ejecutar evaluaciones comparativas no tiene sentido. Tiene que estar diseñado para lograr realmente algo. ¿Qué quiere obtener de la ejecución de referencia? ¿Quieres afinar las consultas? ¿Quieres modificar la configuración? ¿Quieres evaluar la escalabilidad de tu stack? ¿Quieres preparar tu pila para una carga mayor? ¿Quieres hacer un ajuste de configuración genérico para un nuevo proyecto? ¿Quiere determinar la mejor configuración para su hardware? Esos son ejemplos de objetivos que puede querer lograr. Cada uno de estos requerirá un enfoque diferente y una configuración de referencia diferente.
-
Haga un cambio a la vez
Independientemente de lo que esté probando y ajustando, es de suma importancia que solo realice un cambio de configuración a la vez. Esto es realmente crítico. El punto de referencia está destinado a darle una idea sobre el rendimiento. Consultas por segundo, latencia, percentil 99, todo esto le indica qué tan rápido puede ejecutar las consultas y qué tan estable y predecible es la carga de trabajo. Es fácil saber si el cambio que realizó en la configuración, el hardware o la combinación de consultas cambia algo:las métricas del punto de referencia se verán diferentes. La cuestión es que, si realiza un par de cambios al mismo tiempo, no hay forma de saber cuál es el responsable del resultado general. Puede ir incluso más lejos que eso. Digamos que ha cambiado dos valores en la configuración de la base de datos. Valor A y B. La mejora general es del 20 %, lo cual es bastante bueno solo para un cambio de configuración. Sin embargo, bajo el capó, el cambio al valor A trajo una mejora del 30 %, mientras que el cambio adicional al valor B lo retrasó al 20 %. Con múltiples cambios al mismo tiempo, solo puede observar su impacto común, esta no es la forma de determinar correctamente el resultado de cada cambio que realizó. Claro, esto aumenta significativamente el tiempo que dedicará a ejecutar el punto de referencia, pero así son las cosas.
-
Realizar varias ejecuciones de referencia
Las computadoras son sistemas complejos por sí mismas. Tienen múltiples componentes que interactúan entre sí:memoria, CPU, disco, red. Entonces agreguemos a esta virtualización, contenerización. Luego software:sistema operativo, aplicación, base de datos. Capa sobre capa sobre capa sobre capa de elementos que interactúan de alguna manera. No es fácil predecir su comportamiento. Bueno, se puede decir que es casi imposible predecir con precisión el comportamiento de sistemas tan complejos. Esta es la razón por la que ejecutar una prueba de referencia no es suficiente para sacar conclusiones. ¿Qué sucede si, sin saberlo, algún elemento, totalmente ajeno a lo que desea probar, afecta el rendimiento general? Alta carga en otra VM ubicada en el mismo host. Algún otro servidor está transmitiendo copias de seguridad a través de la red. Esto puede afectar temporalmente el rendimiento y sesgar los resultados de referencia. Si ejecuta solo una ejecución de referencia, terminará con resultados incorrectos. Esta es la razón por la cual la mejor práctica es ejecutar varias pasadas de un punto de referencia y luego eliminar la más lenta y la más rápida, promediando las demás.
-
Una imagen vale más que mil palabras
Bueno, esta es una descripción muy precisa de la evaluación comparativa. Si es posible, genere siempre gráficos. Lo ideal es realizar un seguimiento de las métricas durante la evaluación comparativa con la mayor frecuencia posible. Una granularidad de un segundo debería ser suficiente para la mayoría de los casos. Para evitar escribir miles de palabras, incluiremos este ejemplo. ¿Qué crees que es más útil? Este conjunto de resultados de referencia que representan QPS promedio para cada uno de los 10 pases, cada pase toma 600 segundos
11550.16
11247.08
11277.25
O esta trama:
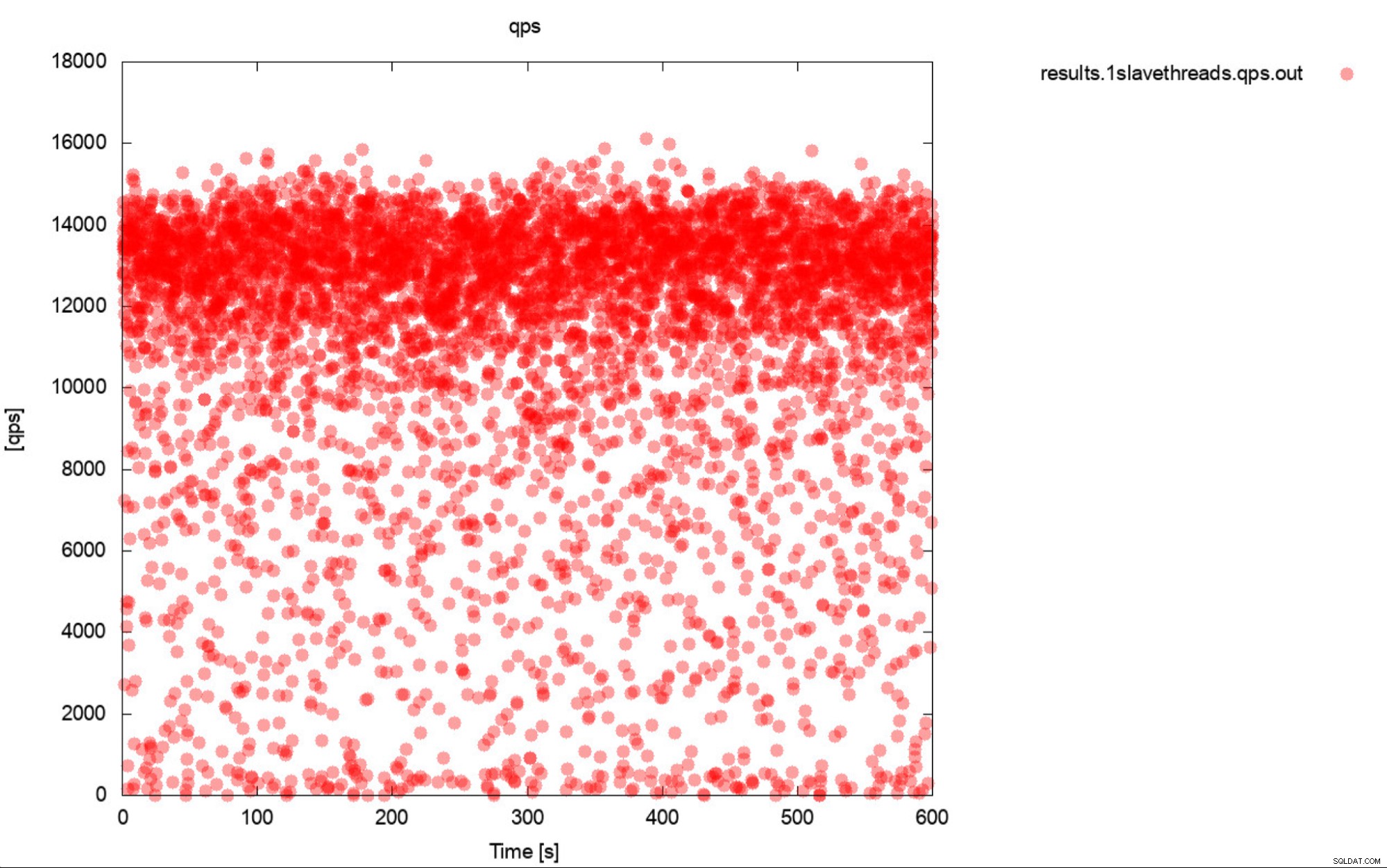
El promedio de QPS es de 11k pero la realidad es que el rendimiento está por todas partes. lugar, incluidas las caídas a 0 consultas ejecutadas en un segundo, y definitivamente es algo en lo que desea trabajar y mejorar en los sistemas de producción.
-
Las consultas por segundo no son la métrica más importante
Puede pensar que la consulta por segundo es el santo grial del rendimiento, ya que representa cuántas consultas puede ejecutar una base de datos en un segundo. La verdad es que no es la métrica más importante, especialmente si estamos hablando del resultado promedio de un punto de referencia. QPS representa el rendimiento pero ignora la latencia. Puede intentar impulsar un gran volumen de consultas, pero luego termina esperando que arrojen resultados. Esto no es lo que los usuarios esperan de la aplicación. Los usuarios esperan un rendimiento estable. No tiene que ser increíblemente rápido, pero cuando una acción tarda un segundo en completarse, tendemos a esperar que realizar esa acción siempre tome ese segundo. Si, por alguna razón, comienza a tomar más tiempo, los humanos tienden a ponerse ansiosos. Esta es la razón principal por la que tendemos a preferir la latencia, especialmente su P99 (percentil 99) como una métrica más confiable. La latencia nos dice cuánto tiempo tuvo que esperar la aplicación para obtener el resultado de la base de datos. P99 nos dice latencia que el 99% de las consultas tienen menor que. Digamos que tenemos un P99 de 100ms, significa que el 99% de las consultas devuelven resultados no más lentos que 100ms. Si vemos que la latencia de P99 es baja, significa que casi todas las consultas regresan rápido y funcionan de manera estable y predecible. Esto es algo que nuestros usuarios quieren ver.
-
Comprender lo que está sucediendo antes de sacar conclusiones
Último punto que tenemos en este breve blog pero diríamos que es el más importante. Verá diferentes resultados y comportamientos extraños e inesperados durante los puntos de referencia. Peor aún, puede ver resultados bastante estándar, repetitivos pero aún defectuosos. La mayoría de ellos se pueden rastrear hasta el comportamiento de la base de datos o el hardware. Esto es realmente crucial:antes de dar por sentado el resultado, debe poder explicar el comportamiento y describir lo que sucedió. Sabemos que no es fácil y sabemos que realmente requiere conocimientos específicos de la base de datos, especialmente conocimientos relacionados con el funcionamiento interno de la base de datos. Sabemos que en el mundo real las personas normalmente no se molestan con esto, solo quieren obtener algunos resultados. La cuestión es que, especialmente en los casos en los que intenta mejorar el rendimiento a través de ajustes de configuración o hardware, comprender lo que sucedió debajo del capó le permite elegir la forma adecuada en la que debe proceder su ajuste. También permite saber si el benchmark que se ha ejecutado puede tener algún sentido. ¿Estamos realmente probando el elemento correcto? Un ejemplo sería una prueba ejecutada a través de la red (porque no querrá usar núcleos de CPU locales del nodo de la base de datos para la herramienta de referencia). Es muy probable que la propia red y la carga de la CPU de softirq sean el factor limitante, mucho antes de que llegue a los cuellos de botella "esperados", como la saturación de la CPU. Si no conoce su entorno y su comportamiento, medirá el rendimiento de su red para transferir grandes volúmenes de datos, no el rendimiento de la CPU.
Como puede ver, la evaluación comparativa no es lo más fácil de hacer, debe tener un nivel de conciencia de lo que está sucediendo, debe tener un plan adecuado para lo que va a hacer y que quieres probar En la siguiente parte de este blog, repasaremos algunos de los casos de prueba del mundo real. Qué puede salir mal, qué problemas encontraremos y cómo abordarlos.



