En nuestros blogs anteriores, discutimos MHA como una herramienta de conmutación por error utilizada en las configuraciones maestro-esclavo de MySQL. El mes pasado, también escribimos en un blog sobre cómo manejar MHA cuando falla. Hoy, veremos los principales problemas que los DBA suelen encontrar con MHA y cómo puede solucionarlos.
Una breve introducción a MHA (Master High Availability)
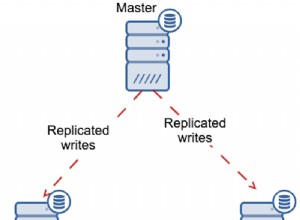
MHA significa (Master High Availability) sigue siendo relevante y se usa ampliamente en la actualidad, especialmente en configuraciones maestro-esclavo basadas en replicación sin GTID. MHA realiza bien una conmutación por error o un interruptor maestro, pero viene con algunas trampas y limitaciones. Una vez que MHA realiza una conmutación por error maestra y una promoción de esclavo, puede completar automáticamente la operación de conmutación por error de su base de datos en aproximadamente 30 segundos, lo que puede ser aceptable en un entorno de producción. MHA puede garantizar la consistencia de los datos. Todo esto sin degradación del rendimiento y no requiere ajustes ni cambios adicionales en sus implementaciones o configuraciones existentes. Aparte de esto, MHA se basa en Perl y es una solución HA de código abierto, por lo que es relativamente fácil crear ayudantes o ampliar la herramienta de acuerdo con la configuración deseada. Consulte esta presentación para obtener más información.
El software MHA consta de dos componentes, debe instalar uno de los siguientes paquetes de acuerdo con su rol de topología:
Nodo administrador MHA =Administrador MHA (administrador)/Nodo MHA (nodo de datos)
Nodos maestro/esclavo =nodo MHA (nodo de datos)
MHA Manager es el software que administra la conmutación por error (automática o manual), toma decisiones sobre cuándo y dónde realizar la conmutación por error y administra la recuperación del esclavo durante la promoción del maestro candidato para aplicar registros de retransmisión diferencial. Si la base de datos maestra deja de funcionar, MHA Manager se coordinará con el agente de nodo de MHA, ya que aplica registros de retransmisión diferencial a los esclavos que no tienen los últimos eventos binlog del maestro. El software MHA Node es un agente local que monitoreará su instancia de MySQL y permitirá que MHA Manager copie los registros de retransmisión de los esclavos. El escenario típico es que cuando el maestro candidato para la conmutación por error se está retrasando actualmente y MHA detecta que no tiene los registros de retransmisión más recientes. Por lo tanto, esperará el mandato de MHA Manager mientras busca el último esclavo que contiene los eventos binlog y copia los eventos faltantes del esclavo usando scp y se los aplica a sí mismo.
Sin embargo, tenga en cuenta que MHA actualmente no se mantiene activamente, pero la versión actual en sí es estable y puede ser "lo suficientemente buena" para la producción. Todavía puede hacer eco de su voz a través de github para solucionar algunos problemas o proporcionar parches para el software.
Principales problemas comunes
Ahora echemos un vistazo a los problemas más comunes que encontrará un DBA al usar MHA.
El esclavo está retrasado, ¡la conmutación por error no interactiva/automatizada falló!
Este es un problema típico que hace que la conmutación por error automatizada se anule o falle. Esto puede sonar simple, pero no apunta a un solo problema específico. El retraso del esclavo puede tener diferentes razones:
- Problemas de disco en el maestro candidato que provocan que esté vinculado a E/S de disco para procesar lecturas y escrituras. También puede conducir a la corrupción de datos si no se mitiga.
- Las consultas incorrectas se replican, especialmente las tablas que no tienen claves principales o índices agrupados.
- carga alta del servidor.
- Servidor frío y el servidor aún no se ha calentado
- No hay suficientes recursos de servidor. Es posible que su esclavo tenga poca memoria o recursos del servidor mientras replica escrituras o lecturas de alta intensidad.
Esos pueden mitigarse de antemano si tiene un control adecuado de su base de datos. Un ejemplo con respecto a los retrasos de los esclavos en MHA es la falta de memoria cuando se descarga un archivo de registro binario grande. Como ejemplo a continuación, un maestro se marcó como inactivo y debe realizar una conmutación por error no interactiva/automática. Sin embargo, como el maestro candidato estaba retrasado y tiene que aplicar los registros que aún no fueron ejecutados por los subprocesos de replicación, MHA ubicará el esclavo más actualizado o más reciente, ya que intentará recuperar un esclavo contra el más antiguo. unos. Por lo tanto, como puede ver a continuación, mientras realizaba una recuperación de esclavo, la memoria se agotó demasiado:
example@sqldat.com:~$ masterha_manager --conf=/etc/app1.cnf --remove_dead_master_conf --ignore_last_failover
Mon May 6 08:43:46 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Mon May 6 08:43:46 2019 - [info] Reading application default configuration from /etc/app1.cnf..
Mon May 6 08:43:46 2019 - [info] Reading server configuration from /etc/app1.cnf..
…
Mon May 6 08:43:57 2019 - [info] Checking master reachability via MySQL(double check)...
Mon May 6 08:43:57 2019 - [info] ok.
Mon May 6 08:43:57 2019 - [info] Alive Servers:
Mon May 6 08:43:57 2019 - [info] 192.168.10.50(192.168.10.50:3306)
Mon May 6 08:43:57 2019 - [info] 192.168.10.70(192.168.10.70:3306)
Mon May 6 08:43:57 2019 - [info] Alive Slaves:
Mon May 6 08:43:57 2019 - [info] 192.168.10.50(192.168.10.50:3306) Version=5.7.23-23-log (oldest major version between slaves) log-bin:enabled
Mon May 6 08:43:57 2019 - [info] Replicating from 192.168.10.60(192.168.10.60:3306)
Mon May 6 08:43:57 2019 - [info] Primary candidate for the new Master (candidate_master is set)
Mon May 6 08:43:57 2019 - [info] 192.168.10.70(192.168.10.70:3306) Version=5.7.23-23-log (oldest major version between slaves) log-bin:enabled
Mon May 6 08:43:57 2019 - [info] Replicating from 192.168.10.60(192.168.10.60:3306)
Mon May 6 08:43:57 2019 - [info] Not candidate for the new Master (no_master is set)
Mon May 6 08:43:57 2019 - [info] Starting Non-GTID based failover.
….
Mon May 6 08:43:59 2019 - [info] * Phase 3.4: New Master Diff Log Generation Phase..
Mon May 6 08:43:59 2019 - [info]
Mon May 6 08:43:59 2019 - [info] Server 192.168.10.50 received relay logs up to: binlog.000004:106167341
Mon May 6 08:43:59 2019 - [info] Need to get diffs from the latest slave(192.168.10.70) up to: binlog.000005:240412 (using the latest slave's relay logs)
Mon May 6 08:43:59 2019 - [info] Connecting to the latest slave host 192.168.10.70, generating diff relay log files..
Mon May 6 08:43:59 2019 - [info] Executing command: apply_diff_relay_logs --command=generate_and_send --scp_user=vagrant --scp_host=192.168.10.50 --latest_mlf=binlog.000005 --latest_rmlp=240412 --target_mlf=binlog.000004 --target_rmlp=106167341 --server_id=3 --diff_file_readtolatest=/tmp/relay_from_read_to_latest_192.168.10.50_3306_20190506084355.binlog --workdir=/tmp --timestamp=20190506084355 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.58 --relay_dir=/var/lib/mysql --current_relay_log=relay-bin.000007
Mon May 6 08:44:00 2019 - [info]
Relay log found at /var/lib/mysql, up to relay-bin.000007
Fast relay log position search failed. Reading relay logs to find..
Reading relay-bin.000007
Binlog Checksum enabled
Master Version is 5.7.23-23-log
Binlog Checksum enabled
…
…...
Target relay log file/position found. start_file:relay-bin.000004, start_pos:106167468.
Concat binary/relay logs from relay-bin.000004 pos 106167468 to relay-bin.000007 EOF into /tmp/relay_from_read_to_latest_192.168.10.50_3306_20190506084355.binlog ..
Binlog Checksum enabled
Binlog Checksum enabled
Dumping binlog format description event, from position 0 to 361.. ok.
Dumping effective binlog data from /var/lib/mysql/relay-bin.000004 position 106167468 to tail(1074342689)..Out of memory!
Mon May 6 08:44:00 2019 - [error][/usr/local/share/perl/5.26.1/MHA/MasterFailover.pm, ln1090] Generating diff files failed with return code 1:0.
Mon May 6 08:44:00 2019 - [error][/usr/local/share/perl/5.26.1/MHA/MasterFailover.pm, ln1584] Recovering master server failed.
Mon May 6 08:44:00 2019 - [error][/usr/local/share/perl/5.26.1/MHA/ManagerUtil.pm, ln178] Got ERROR: at /usr/local/bin/masterha_manager line 65.
Mon May 6 08:44:00 2019 - [info]
----- Failover Report -----
app1: MySQL Master failover 192.168.10.60(192.168.10.60:3306)
Master 192.168.10.60(192.168.10.60:3306) is down!
Check MHA Manager logs at testnode20 for details.
Started automated(non-interactive) failover.
Invalidated master IP address on 192.168.10.60(192.168.10.60:3306)
The latest slave 192.168.10.70(192.168.10.70:3306) has all relay logs for recovery.
Selected 192.168.10.50(192.168.10.50:3306) as a new master.
Recovering master server failed.
Got Error so couldn't continue failover from here.Por lo tanto, la conmutación por error falló. Este ejemplo anterior muestra que el nodo 192.168.10.70 contiene los registros de retransmisión más actualizados. Sin embargo, en este escenario de ejemplo, el nodo 192.168.10.70 se establece como no_master porque tiene poca memoria. Al intentar recuperar el esclavo 192.168.10.50, ¡falla!
Arreglos/Resolución:
Este escenario ilustra algo muy importante. ¡Se debe configurar un entorno de monitoreo avanzado! Por ejemplo, puede ejecutar una secuencia de comandos en segundo plano o daemon que supervise el estado de la replicación. Puede agregar como una entrada a través de un trabajo cron. Por ejemplo, agregue una entrada usando el script incorporado masterha_check_repl :
/usr/local/bin/masterha_check_repl --conf=/etc/app1.cnfo cree un script de fondo que invoque este script y lo ejecute en un intervalo. Puede usar la opción report_script para configurar una notificación de alerta en caso de que no se ajuste a sus requisitos, por ejemplo, el esclavo se retrasa unos 100 segundos durante un pico de carga alto. También puede usar plataformas de monitoreo como ClusterControl y configurarlo para que le envíe notificaciones basadas en las métricas que desea monitorear.
Además de esto, tenga en cuenta que, en el escenario de ejemplo, la conmutación por error falló debido a un error de falta de memoria. Podría considerar asegurarse de que todos sus nodos tengan suficiente memoria y el tamaño correcto de los registros binarios, ya que necesitarían volcar el binlog para una fase de recuperación secundaria.
Esclavo inconsistente, ¡falló la aplicación de diferencias!
En relación con el retraso del esclavo, dado que MHA intentará sincronizar los registros de retransmisión con un maestro candidato, asegúrese de que sus datos estén sincronizados. Diga un ejemplo a continuación:
...
Concat succeeded.
Generating diff relay log succeeded. Saved at /tmp/relay_from_read_to_latest_192.168.10.50_3306_20190506054328.binlog .
scp testnode7:/tmp/relay_from_read_to_latest_192.168.10.50_3306_20190506054328.binlog to example@sqldat.com(22) succeeded.
Mon May 6 05:43:53 2019 - [info] Generating diff files succeeded.
Mon May 6 05:43:53 2019 - [info]
Mon May 6 05:43:53 2019 - [info] * Phase 3.5: Master Log Apply Phase..
Mon May 6 05:43:53 2019 - [info]
Mon May 6 05:43:53 2019 - [info] *NOTICE: If any error happens from this phase, manual recovery is needed.
Mon May 6 05:43:53 2019 - [info] Starting recovery on 192.168.10.50(192.168.10.50:3306)..
Mon May 6 05:43:53 2019 - [info] Generating diffs succeeded.
Mon May 6 05:43:53 2019 - [info] Waiting until all relay logs are applied.
Mon May 6 05:43:53 2019 - [info] done.
Mon May 6 05:43:53 2019 - [info] Getting slave status..
Mon May 6 05:43:53 2019 - [info] This slave(192.168.10.50)'s Exec_Master_Log_Pos equals to Read_Master_Log_Pos(binlog.000010:161813650). No need to recover from Exec_Master_Log_Pos.
Mon May 6 05:43:53 2019 - [info] Connecting to the target slave host 192.168.10.50, running recover script..
Mon May 6 05:43:53 2019 - [info] Executing command: apply_diff_relay_logs --command=apply --slave_user='cmon' --slave_host=192.168.10.50 --slave_ip=192.168.10.50 --slave_port=3306 --apply_files=/tmp/relay_from_read_to_latest_192.168.10.50_3306_20190506054328.binlog --workdir=/tmp --target_version=5.7.23-23-log --timestamp=20190506054328 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.58 --slave_pass=xxx
Mon May 6 05:43:53 2019 - [info]
MySQL client version is 5.7.23. Using --binary-mode.
Applying differential binary/relay log files /tmp/relay_from_read_to_latest_192.168.10.50_3306_20190506054328.binlog on 192.168.10.50:3306. This may take long time...
mysqlbinlog: Error writing file 'UNOPENED' (Errcode: 32 - Broken pipe)
FATAL: applying log files failed with rc 1:0!
Error logs from testnode5:/tmp/relay_log_apply_for_192.168.10.50_3306_20190506054328_err.log (the last 200 lines)..
ICwgMmM5MmEwZjkzY2M5MTU3YzAxM2NkZTk4ZGQ1ODM0NDEgLCAyYzkyYTBmOTNjYzkxNTdjMDEz
….
…..
M2QxMzc5OWE1NTExOTggLCAyYzkyYTBmOTNjZmI1YTdhMDEzZDE2NzhiNDc3NDIzNCAsIDJjOTJh
MGY5M2NmYjVhN2EwMTNkMTY3OGI0N2Q0MjMERROR 1062 (23000) at line 72: Duplicate entry '12583545' for key 'PRIMARY'
5ICwgMmM5MmEwZjkzY2ZiNWE3YTAxM2QxNjc4YjQ4
OTQyM2QgLCAyYzkyYTBmOTNjZmI1YTdhMDEzZDE2NzhiNDkxNDI1MSAsIDJjOTJhMGY5M2NmYjVh
N2EwMTNkMTczN2MzOWM3MDEzICwgMmM5MmEwZjkzY2ZiNWE3YTAxM2QxNzM3YzNhMzcwMTUgLCAy
…
--------------
Bye
at /usr/local/bin/apply_diff_relay_logs line 554.
eval {...} called at /usr/local/bin/apply_diff_relay_logs line 514
main::main() called at /usr/local/bin/apply_diff_relay_logs line 121
Mon May 6 05:43:53 2019 - [error][/usr/local/share/perl/5.26.1/MHA/MasterFailover.pm, ln1399] Applying diffs failed with return code 22:0.
Mon May 6 05:43:53 2019 - [error][/usr/local/share/perl/5.26.1/MHA/MasterFailover.pm, ln1584] Recovering master server failed.
Mon May 6 05:43:53 2019 - [error][/usr/local/share/perl/5.26.1/MHA/ManagerUtil.pm, ln178] Got ERROR: at /usr/local/bin/masterha_manager line 65.
Mon May 6 05:43:53 2019 - [info]Un clúster inconsistente es realmente malo, especialmente cuando la conmutación por error automática está habilitada. En este caso, la conmutación por error no puede continuar porque detecta una entrada duplicada para la clave principal '12583545 '.
Arreglos/Resolución:
Hay varias cosas que puede hacer aquí para evitar el estado inconsistente de su clúster.
- Habilite la replicación semisincrónica sin pérdidas. Consulte este blog externo, que es una buena manera de saber por qué debería considerar usar semisincronización en una configuración de replicación MySQL estándar.
- Ejecute constantemente una suma de verificación contra su clúster maestro-esclavo. Puede usar pt-table-checksum y ejecutarlo una vez a la semana o al mes, según la frecuencia con la que se actualice su tabla. Tenga en cuenta que pt-table-checksum puede agregar sobrecarga al tráfico de su base de datos.
- Utilice la replicación basada en GTID. Aunque esto no afectará el problema per se. Sin embargo, la replicación basada en GTID lo ayuda a determinar transacciones erróneas, especialmente aquellas transacciones que se ejecutaron directamente en el esclavo. Otra ventaja de esto es que es más fácil administrar la replicación basada en GTID cuando necesita cambiar el host maestro en la replicación.
Falla de hardware en el maestro, pero los esclavos aún no se han puesto al día
Una de las muchas razones por las que invertiría en conmutación por error automática es una falla de hardware en el maestro. Para algunas configuraciones, puede ser más ideal realizar una conmutación por error automática solo cuando el maestro encuentra una falla de hardware. El enfoque típico es notificar mediante el envío de una alarma, lo que podría significar despertar a la persona de operaciones de guardia en medio de la noche para que la persona decida qué hacer. Este tipo de enfoque se realiza en Github o incluso en Facebook. Una falla de hardware, especialmente si el volumen donde residen sus registros binarios y el directorio de datos se ve afectado, puede interferir con su conmutación por error, especialmente si los registros binarios se almacenan en ese disco fallido. Por diseño, MHA intentará guardar los registros binarios del maestro bloqueado, pero esto no será posible si el disco falló. Un posible escenario que puede ocurrir es que no se pueda acceder al servidor a través de SSH. MHA no puede guardar registros binarios y tiene que realizar una conmutación por error sin aplicar eventos de registro binario que existen solo en el maestro bloqueado. Esto resultará en la pérdida de los datos más recientes, especialmente si ningún esclavo ha alcanzado al maestro.
Arreglos/Resolución
Como uno de los casos de uso de MHA, se recomienda utilizar la replicación semisincrónica, ya que reduce en gran medida el riesgo de tal pérdida de datos. Es importante tener en cuenta que cualquier escritura que vaya al maestro debe garantizar que los esclavos hayan recibido los últimos eventos de registro binario antes de sincronizar con el disco. MHA puede aplicar los eventos a todos los demás esclavos para que sean coherentes entre sí.
Además, también es mejor ejecutar un flujo de respaldo de sus registros binarios para la recuperación ante desastres en caso de que el volumen del disco principal falle. Si aún se puede acceder al servidor a través de SSH, entonces la ruta del registro binario a la ruta de respaldo de su registro binario aún puede funcionar, por lo que la conmutación por error y la recuperación de esclavos aún pueden avanzar. De esta manera, puede evitar la pérdida de datos.
Conmutación por error de VIP (IP virtual) que causa cerebro dividido
MHA, por defecto, no maneja ninguna gestión VIP. Sin embargo, es fácil incorporar esto con la configuración de MHA y asignar enlaces de acuerdo con lo que desea que haga MHA durante la conmutación por error. Puede configurar su propio script y vincularlo a los parámetros master_ip_failover_script o master_ip_online_change_script. También hay scripts de muestra que se encuentran en el directorio
Durante una conmutación por error automática, una vez que se invoque y ejecute su secuencia de comandos con administración de VIP, MHA hará lo siguiente:verificará el estado, eliminará (o detendrá) el VIP anterior y luego reasignará el nuevo VIP al nuevo maestro. Un ejemplo típico de cerebro dividido es cuando un maestro se identifica como muerto debido a un problema de red pero, de hecho, los nodos esclavos aún pueden conectarse al maestro. Se trata de un falso positivo y, a menudo, genera incoherencias en los datos de las bases de datos de la configuración. Las conexiones de clientes entrantes que utilizan el VIP se enviarán al nuevo maestro. Mientras que, por otro lado, puede haber conexiones locales ejecutándose en el maestro antiguo, que se supone que está muerto. Las conexiones locales podrían estar usando el socket de Unix o localhost para disminuir los saltos de red. Esto puede hacer que los datos se desplacen contra el nuevo maestro y el resto de sus esclavos, ya que los datos del antiguo maestro no se replicarán en los esclavos.
Arreglos/Resolución:
Como se indicó anteriormente, algunos pueden preferir evitar la conmutación por error automática a menos que las comprobaciones hayan determinado que el maestro está totalmente inactivo (como una falla de hardware), es decir, incluso los nodos esclavos no pueden alcanzarlo. La idea es que un falso positivo podría ser causado por una falla en la red entre el controlador de nodo MHA y el maestro, por lo que un ser humano puede ser más adecuado en este caso para tomar una decisión sobre si se debe realizar una conmutación por error o no.
Cuando se trata de falsas alarmas, MHA tiene un parámetro llamado second_check_script. El valor colocado aquí puede ser sus secuencias de comandos personalizadas o puede usar la secuencia de comandos integrada /usr/local/bin/masterha_secondary_check que se envía junto con el paquete MHA Manager. Esto agrega verificaciones adicionales, que en realidad es el enfoque recomendado para evitar falsos positivos. En el siguiente ejemplo de mi propia configuración, estoy usando el script integrado masterha_secondary_check :
secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.10.50 --user=root --master_host=testnode6 --master_ip=192.168.10.60 --master_port=3306En el ejemplo anterior, MHA Manager realizará un ciclo basado en la lista de nodos esclavos (especificados por el argumento -s) que verificará la conexión con el host maestro MySQL (192.168.10.60). Tenga en cuenta que estos nodos esclavos en el ejemplo pueden ser algunos nodos remotos externos que pueden establecer una conexión con los nodos de la base de datos dentro del clúster. Este es un enfoque recomendado especialmente para aquellas configuraciones en las que MHA Manager se ejecuta en un centro de datos diferente o en una red diferente a la de los nodos de la base de datos. La siguiente secuencia a continuación ilustra cómo se procede con los controles:
- Desde el host MHA -> verifique la conexión TCP al primer nodo esclavo (IP:192.168.10.50). Llamemos a esto como Conexión A. Luego, desde el Nodo esclavo, verifica la conexión TCP al Nodo maestro (192.168.10.60). Llamemos a esta Conexión B.
Si la "Conexión A" tuvo éxito pero la "Conexión B" no tuvo éxito en ambas rutas, masterha_secondary_check el script sale con el código de retorno 0 y MHA Manager decide que MySQL maestro está realmente inactivo y comenzará la conmutación por error. Si la "Conexión A" no tuvo éxito, masterha_secondary_check sale con el código de retorno 2 y MHA Manager adivina que hay un problema de red y no inicia la conmutación por error. Si la "Conexión B" fue exitosa, masterha_secondary_check sale con el código de retorno 3 y MHA Manager entiende que el servidor maestro de MySQL está realmente vivo y no inicia la conmutación por error.
Un ejemplo de cómo reacciona durante la conmutación por error según el registro,
Tue May 7 05:31:57 2019 - [info] OK.
Tue May 7 05:31:57 2019 - [warning] shutdown_script is not defined.
Tue May 7 05:31:57 2019 - [info] Set master ping interval 1 seconds.
Tue May 7 05:31:57 2019 - [info] Set secondary check script: /usr/local/bin/masterha_secondary_check -s 192.168.10.50 -s 192.168.10.60 -s 192.168.10.70 --user=root --master_host=192.168.10.60 --master_ip=192.168.10.60 --master_port=3306
Tue May 7 05:31:57 2019 - [info] Starting ping health check on 192.168.10.60(192.168.10.60:3306)..
Tue May 7 05:31:58 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.10.60' (110))
Tue May 7 05:31:58 2019 - [warning] Connection failed 1 time(s)..
Tue May 7 05:31:58 2019 - [info] Executing SSH check script: exit 0
Tue May 7 05:31:58 2019 - [info] Executing secondary network check script: /usr/local/bin/masterha_secondary_check -s 192.168.10.50 -s 192.168.10.60 -s 192.168.10.70 --user=root --master_host=192.168.10.60 --master_ip=192.168.10.60 --master_port=3306 --user=vagrant --master_host=192.168.10.60 --master_ip=192.168.10.60 --master_port=3306 --master_user=cmon example@sqldat.com --ping_type=SELECT
Master is reachable from 192.168.10.50!
Tue May 7 05:31:58 2019 - [warning] Master is reachable from at least one of other monitoring servers. Failover should not happen.
Tue May 7 05:31:59 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.10.60' (110))
Tue May 7 05:31:59 2019 - [warning] Connection failed 2 time(s)..
Tue May 7 05:32:00 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.10.60' (110))
Tue May 7 05:32:00 2019 - [warning] Connection failed 3 time(s)..
Tue May 7 05:32:01 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.10.60' (110))
Tue May 7 05:32:01 2019 - [warning] Connection failed 4 time(s)..
Tue May 7 05:32:03 2019 - [warning] HealthCheck: Got timeout on checking SSH connection to 192.168.10.60! at /usr/local/share/perl/5.26.1/MHA/HealthCheck.pm line 343.
Tue May 7 05:32:03 2019 - [warning] Secondary network check script returned errors. Failover should not start so checking server status again. Check network settings for details.
Tue May 7 05:32:04 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.10.60' (110))
Tue May 7 05:32:04 2019 - [warning] Connection failed 1 time(s)..
Tue May 7 05:32:04 2019 - [info] Executing secondary network check script: /usr/local/bin/masterha_secondary_check -s 192.168.10.50 -s 192.168.10.60 -s 192.168.10.70 --user=root --master_host=192.168.10.60 --master_ip=192.168.10.60 --master_port=3306 --user=vagrant --master_host=192.168.10.60 --master_ip=192.168.10.60 --master_port=3306 --master_user=cmon example@sqldat.com --ping_type=SELECT
Tue May 7 05:32:04 2019 - [info] Executing SSH check script: exit 0Otra cosa para agregar es asignar un valor al parámetro shutdown_script. Este script es especialmente útil si tiene que implementar un STONITH adecuado o una valla de nodo para que no se levante de entre los muertos. Esto puede evitar la inconsistencia de los datos.
Por último, asegúrese de que MHA Manager resida dentro de la misma red local junto con los nodos del clúster, ya que reduce la posibilidad de interrupciones de la red, especialmente la conexión de MHA Manager a los nodos de la base de datos.
Evitar SPOF en MHA
MHA puede fallar por varias razones y, lamentablemente, no hay una función integrada para solucionar esto, es decir, alta disponibilidad para MHA. Sin embargo, como comentamos en nuestro blog anterior "¡El administrador maestro de alta disponibilidad (MHA) se bloqueó! ¿Qué debo hacer ahora?", hay una manera de evitar SPOF para MHA.
Arreglos/Resolución:
Puede aprovechar Pacemaker para crear nodos activos/en espera administrados por el administrador de recursos de clúster (crm). Como alternativa, puede crear una secuencia de comandos para comprobar el estado del nodo del administrador de MHA. Por ejemplo, puede aprovisionar un nodo en espera que verifique activamente el nodo del administrador de MHA haciendo ssh para ejecutar el script integrado masterha_check_status como a continuación:
example@sqldat.com:~$ /usr/local/bin/masterha_check_status --conf=/etc/app1.cnf
app1 is stopped(2:NOT_RUNNING).luego haga un cercado de nodos si ese controlador está dañado. También puede ampliar la herramienta MHA con una secuencia de comandos auxiliar que se ejecuta a través de un trabajo cron y monitorear el proceso del sistema de la secuencia de comandos masterha_manager y volver a generarlo si el proceso está inactivo.
Pérdida de datos durante la conmutación por error
MHA se basa en la replicación asíncrona tradicional. Aunque admite la semisincronización, la semisincronización se basa en la replicación asíncrona. En este tipo de entorno, la pérdida de datos puede ocurrir después de una conmutación por error. Cuando su base de datos no está configurada correctamente y utiliza un enfoque de replicación anticuado, puede ser una molestia, especialmente cuando se trata de la coherencia de los datos y las transacciones perdidas.
Otra cosa importante a tener en cuenta con la pérdida de datos con MHA, es cuando se usa GTID sin semisincronización habilitada. MHA con GTID no se conectará a través de ssh al maestro, pero primero intentará sincronizar los registros binarios para la recuperación del nodo con los esclavos. Esto puede conducir potencialmente a una mayor pérdida de datos en comparación con MHA no GTID con semisincronización no habilitada.
Arreglos/Resolución
Cuando realice una conmutación por error automática, cree una lista de escenarios en los que espera que su MHA realice una conmutación por error. Dado que MHA se ocupa de la replicación maestro-esclavo, nuestros consejos para evitar la pérdida de datos son los siguientes:
- Habilite la replicación semisincrónica sin pérdidas (existe en la versión MySQL 5.7)
- Utilice la replicación basada en GTID. Por supuesto, puede usar la replicación tradicional usando las coordenadas x e y de binlog. Sin embargo, hace las cosas más difíciles y lleva más tiempo cuando necesita ubicar una entrada de registro binario específica que no se aplicó en el esclavo. Por lo tanto, con GTID en MySQL, es más fácil detectar transacciones erróneas.
- Para cumplir con ACID de su replicación maestro-esclavo de MySQL, habilite estas variables específicas:sync_binlog =1, innodb_flush_log_at_trx_commit =1. Esto es costoso ya que requiere más poder de procesamiento cuando MySQL llama a la función fsync() cuando se confirma, y el rendimiento puede vincularse al disco en caso de un gran número de escrituras. Sin embargo, el uso de RAID con caché de respaldo de batería ahorra E/S de disco. Además, MySQL en sí ha mejorado con la confirmación del grupo de registros binarios, pero seguir usando un caché de copia de seguridad puede ahorrar algunas sincronizaciones de disco.
- Aproveche la replicación paralela o la replicación esclava de subprocesos múltiples. Esto puede ayudar a sus esclavos a tener un mejor rendimiento y evita retrasos de esclavos contra el maestro. No desea que su conmutación por error automática ocurra cuando no se puede acceder al maestro a través de una conexión ssh o tcp, o si encontró una falla en el disco y sus esclavos se están quedando atrás. Eso podría conducir a la pérdida de datos.
- Al realizar una conmutación por error en línea o manual, es mejor que lo haga durante los períodos de menor actividad para evitar percances inesperados que podrían provocar la pérdida de datos. O para evitar búsquedas que consumen mucho tiempo grepping a través de sus registros binarios mientras hay mucha actividad en curso.
MHA dice que la aplicación no se está ejecutando o la conmutación por error no funciona. ¿Qué debo hacer?
Ejecutar comprobaciones con el script incorporado masterha_check_status verificará si el script mastreha_manager se está ejecutando. De lo contrario, obtendrá un error como el siguiente:
example@sqldat.com:~$ /usr/local/bin/masterha_check_status --conf=/etc/app1.cnf app1 is stopped(2:NOT_RUNNING).Sin embargo, hay ciertos casos en los que puede obtener NOT_RUNNING incluso cuando masterha_manager Esta corriendo. Esto puede deberse al privilegio del ssh_user que configuró, o si ejecuta masterha_manager con un usuario del sistema diferente, o si el usuario ssh encontró un permiso denegado.
Arreglos/Resolución:
MHA utilizará el ssh_user definido en la configuración si se especifica. De lo contrario, usará el usuario del sistema actual que usa para invocar los comandos MHA. Al ejecutar el script masterha_check_status por ejemplo, debe asegurarse de que masterha_manager se ejecute con el mismo usuario que se especifica en ssh_user en su archivo de configuración, o el usuario que interactuará con los otros nodos de la base de datos en el clúster. Debe asegurarse de que tenga claves SSH sin contraseña ni frase de contraseña para que MHA no tenga ningún problema al establecer la conexión con los nodos que MHA está monitoreando.
Tenga en cuenta que necesita el ssh_user tener acceso a lo siguiente:
- Puede leer los registros binarios y de retransmisión de los nodos MySQL que MHA está monitoreando
- Debe tener acceso a los registros de monitoreo de MHA. Consulte estos parámetros en MHA:master_binlog_dir, manager_workdir y manager_log
- Debe tener acceso al archivo de configuración de MHA. Esto también es muy importante. Durante una conmutación por error, una vez que finalice la conmutación por error, intentará actualizar el archivo de configuración y eliminar la entrada del maestro inactivo. Si el archivo de configuración no permite el ssh_user o el usuario del sistema operativo que está utilizando actualmente, no actualizará el archivo de configuración, lo que provocará una escalada del problema si el desastre vuelve a ocurrir.
Retrasos del maestro candidato, cómo forzar y evitar la conmutación por error fallida
En referencia a la wiki de MHA, por defecto, si un esclavo detrás del maestro tiene más de 100 MB de registros de retransmisión (=necesita aplicar más de 100 MB de registros de retransmisión), MHA no elige al esclavo como nuevo maestro porque lleva mucho tiempo recuperarse. .
Arreglos/Resolución
En MHA, esto se puede anular configurando el parámetro check_repl_delay=0. Durante una conmutación por error, MHA ignora el retraso de replicación al seleccionar un nuevo maestro y ejecutará las transacciones faltantes. Esta opción es útil cuando establece candidato_maestro=1 en un host específico y desea asegurarse de que el host pueda ser el nuevo maestro.
También puede integrarse con pt-heartbeat para lograr la precisión del retraso esclavo (consulte esta publicación y esta). Pero esto también se puede aliviar con la replicación paralela o los esclavos de replicación de subprocesos múltiples, presentes desde MySQL 5.6 o con MariaDB 10, que afirma tener un impulso con una mejora de 10 veces en la replicación paralela y los esclavos de subprocesos múltiples. Esto puede ayudar a que tus esclavos se repliquen más rápido.
Las contraseñas de MHA están expuestas
Asegurar o cifrar las contraseñas no es algo que esté a cargo de MHA. The parameters password or repl_password will be exposed via the configuration file. So your system administrator or security architect must evaluate the grants or privileges of this file as you don’t want to expose valuable database/SSH credentials.
Fixes/Resolution:
MHA has an optional parameter init_conf_load_script. This parameter can be used to have a custom script load your MHA config that will interface to e.g. a database, and retrieve the user/password credentials of your replication setup.
Of course, you can also limit the file attribute of the configuration and the user you are using, and limit the access to the specific Ops/DBA's/Engineers that will handle MHA.
MHA is Not My Choice, What Are the Alternatives for replication failover?
MHA is not a one-size-fits-all solution, it has its limitations and may not fit your desired setup. However, here's a list of variants that you can try.
- PRM
- Maxscale with Mariadb Monitor or MariaDB Replication Manager (MRM)
- Orchestrator
- ClusterControl