Si su infraestructura de TI se ejecuta en AWS, probablemente haya oído hablar de Amazon Relational Database Service (RDS), una manera fácil de configurar, operar y escalar una base de datos relacional en la nube. Proporciona una capacidad rentable y redimensionable al mismo tiempo que automatiza las tareas de administración que consumen mucho tiempo, como el aprovisionamiento de hardware, la configuración de la base de datos, la aplicación de parches y las copias de seguridad. Hay varias ofertas de motores de base de datos para RDS como MySQL, MariaDB, PostgreSQL, Microsoft SQL Server y Oracle Server.
ClusterControl 1.7.3 actúa de manera similar a RDS, ya que admite la implementación, administración, monitoreo y escalado de clústeres de bases de datos en la plataforma de AWS. También es compatible con otras plataformas en la nube como Google Cloud Platform y Microsoft Azure. ClusterControl comprende la topología de la base de datos y es capaz de realizar recuperación automática, administración de topología y muchas funciones más avanzadas para tomar el control de su base de datos.
En esta publicación de blog, compararemos los tiempos de conmutación por error automáticos para Amazon Aurora, Amazon RDS para MySQL y una configuración de replicación de MySQL implementada y administrada por ClusterControl. El tipo de conmutación por error que vamos a hacer es la promoción de esclavos en caso de que el maestro se caiga. Aquí es donde el esclavo más actualizado asume la función de maestro en el clúster para reanudar el servicio de la base de datos.
Nuestra prueba de conmutación por error
Para medir el tiempo de conmutación por error, vamos a ejecutar una prueba simple de conexión y actualización de MySQL, con un ciclo para contar el estado de la instrucción SQL que se conecta a un solo punto final de la base de datos. El guión se ve así:
#!/bin/bash
_host='{MYSQL ENDPOINT}'
_user='sbtest'
_pass='password'
_port=3306
j=1
while true
do
echo -n "count $j : "
num=$(od -A n -t d -N 1 /dev/urandom |tr -d ' ')
timeout 1 bash -c "mysql -u${_user} -p${_pass} -h${_host} -P${_port} --connect-timeout=1 --disable-reconnect -A -Bse \
\"UPDATE sbtest.sbtest1 SET k = $num WHERE id = 1\" > /dev/null 2> /dev/null"
if [ $? -eq 0 ]; then
echo "OK $(date)"
else
echo "Fail ---- $(date)"
fi
j=$(( $j + 1 ))
sleep 1
done
La secuencia de comandos Bash anterior simplemente se conecta a un host MySQL y realiza una actualización en una sola fila con un tiempo de espera de 1 segundo en los comandos de cliente Bash y mysql. Los parámetros relacionados con los tiempos de espera son necesarios para que podamos medir correctamente el tiempo de inactividad en segundos, ya que el cliente mysql se vuelve a conectar por defecto hasta que alcanza el tiempo de espera de MySQL. Previamente, completamos un conjunto de datos de prueba con el siguiente comando:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host={MYSQL HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=50 \
--table-size=100000 \
prepareEl script informa si la consulta anterior tuvo éxito (OK) o falló (Falla). Las salidas de muestra se muestran más abajo.
Conmutación por error con Amazon RDS para MySQL
En nuestra prueba, usamos la oferta de RDS más baja con las siguientes especificaciones:
- Versión de MySQL:5.7.22
- vCPU:4
- RAM:16GB
- Tipo de almacenamiento:IOPS provisionadas (SSD)
- IOPS:1000
- Almacenamiento:100Gib
- Replicación Multi-AZ:Sí
Después de que Amazon RDS aprovisione su instancia de base de datos, puede usar cualquier aplicación o utilidad cliente de MySQL estándar para conectarse a la instancia. En la cadena de conexión, especifica la dirección DNS del punto de enlace de la instancia de base de datos como parámetro de host y especifica el número de puerto del punto de enlace de la instancia de base de datos como parámetro de puerto.
De acuerdo con la página de documentación de Amazon RDS, en caso de una interrupción planificada o no planificada de su instancia de base de datos, Amazon RDS cambia automáticamente a una réplica en espera en otra zona de disponibilidad si ha habilitado Multi-AZ. El tiempo que tarda en completarse la conmutación por error depende de la actividad de la base de datos y otras condiciones en el momento en que la instancia de base de datos principal dejó de estar disponible. Los tiempos de conmutación por error suelen ser de 60 a 120 segundos.
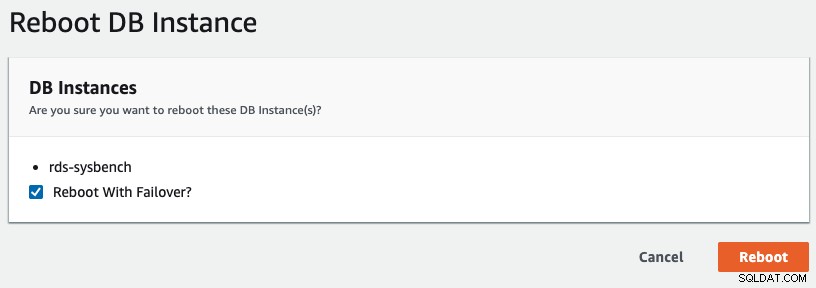
Para iniciar una conmutación por error multi-AZ en RDS, realizamos una operación de reinicio con "Reiniciar con conmutación por error" marcada, como se muestra en la siguiente captura de pantalla:
Lo siguiente es lo que está siendo observado por nuestra aplicación:
...
count 30 : OK Wed Aug 28 03:41:06 UTC 2019
count 31 : OK Wed Aug 28 03:41:07 UTC 2019
count 32 : Fail ---- Wed Aug 28 03:41:09 UTC 2019
count 33 : Fail ---- Wed Aug 28 03:41:11 UTC 2019
count 34 : Fail ---- Wed Aug 28 03:41:13 UTC 2019
count 35 : Fail ---- Wed Aug 28 03:41:15 UTC 2019
count 36 : Fail ---- Wed Aug 28 03:41:17 UTC 2019
count 37 : Fail ---- Wed Aug 28 03:41:19 UTC 2019
count 38 : Fail ---- Wed Aug 28 03:41:21 UTC 2019
count 39 : Fail ---- Wed Aug 28 03:41:23 UTC 2019
count 40 : Fail ---- Wed Aug 28 03:41:25 UTC 2019
count 41 : Fail ---- Wed Aug 28 03:41:27 UTC 2019
count 42 : Fail ---- Wed Aug 28 03:41:29 UTC 2019
count 43 : Fail ---- Wed Aug 28 03:41:31 UTC 2019
count 44 : Fail ---- Wed Aug 28 03:41:33 UTC 2019
count 45 : Fail ---- Wed Aug 28 03:41:35 UTC 2019
count 46 : OK Wed Aug 28 03:41:36 UTC 2019
count 47 : OK Wed Aug 28 03:41:37 UTC 2019
...El tiempo de inactividad de MySQL visto por el lado de la aplicación se inició desde las 03:41:09 hasta las 03:41:36, que es de alrededor de 27 segundos en total. A partir de los eventos de RDS, podemos ver que la conmutación por error multi-AZ solo ocurrió 15 segundos después del tiempo de inactividad real:
Wed, 28 Aug 2019 03:41:24 GMT Multi-AZ instance failover started.
Wed, 28 Aug 2019 03:41:33 GMT DB instance restarted
Wed, 28 Aug 2019 03:41:59 GMT Multi-AZ instance failover completed.Una vez que la nueva instancia de la base de datos se reinició alrededor de las 03:41:33, se pudo acceder al servicio MySQL unos 3 segundos después.
Conmutación por error con Amazon Aurora para MySQL
Amazon Aurora se puede considerar como una versión superior de RDS, con muchas características notables, como una replicación más rápida con almacenamiento compartido, sin pérdida de datos durante la conmutación por error y hasta 64 TB de límite de almacenamiento. Amazon Aurora para MySQL se basa en MySQL Edition de código abierto, pero no es un código abierto en sí mismo; es una base de datos patentada de código cerrado. Funciona de manera similar con la replicación de MySQL (uno y solo un maestro, con varios esclavos) y Amazon Aurora maneja automáticamente la conmutación por error.
De acuerdo con las preguntas frecuentes de Amazon Aurora, si tiene una réplica de Amazon Aurora, en la misma zona de disponibilidad o en una diferente, al realizar la conmutación por error, Aurora invierte el registro de nombre canónico (CNAME) para que su instancia de base de datos apunte a la réplica en buen estado, que está en turno es promovido para convertirse en el nuevo primario. De principio a fin, la conmutación por error generalmente se completa en 30 segundos.
Si no tiene una réplica de Amazon Aurora (es decir, una sola instancia), Aurora primero intentará crear una nueva instancia de base de datos en la misma zona de disponibilidad que la instancia original. Si no puede hacerlo, Aurora intentará crear una nueva instancia de base de datos en una zona de disponibilidad diferente. De principio a fin, la conmutación por error generalmente se completa en menos de 15 minutos.
Su aplicación debe volver a intentar las conexiones a la base de datos en caso de pérdida de conexión.
Después de que Amazon Aurora aprovisione su instancia de base de datos, obtendrá dos puntos de enlace, uno para el escritor y otro para el lector. El punto de enlace del lector proporciona soporte de equilibrio de carga para conexiones de solo lectura al clúster de base de datos. Los siguientes puntos finales se toman de nuestra configuración de prueba:
- escritor:aurora-sysbench.cluster-cw9j4kdnvun9.ap-sureste-1.rds.amazonaws.com
- lector - aurora-sysbench.cluster-ro-cw9j4kdnvun9.ap-sureste-1.rds.amazonaws.com
En nuestra prueba, usamos las siguientes especificaciones de Aurora:
- Tipo de instancia:db.r5.large
- Versión de MySQL:5.7.12
- vCPU:2
- RAM:16GB
- Replicación Multi-AZ:Sí
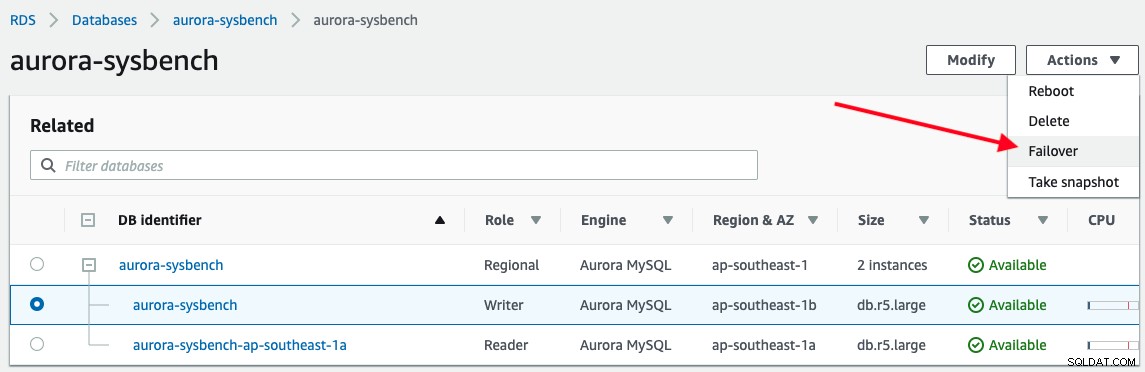
Para desencadenar una conmutación por error, simplemente elija la instancia del escritor -> Acciones -> Conmutación por error, como se muestra en la siguiente captura de pantalla:
Nuestra aplicación informa sobre el siguiente resultado mientras se conecta al punto final del escritor de Aurora :
...
count 37 : OK Wed Aug 28 12:35:47 UTC 2019
count 38 : OK Wed Aug 28 12:35:48 UTC 2019
count 39 : Fail ---- Wed Aug 28 12:35:49 UTC 2019
count 40 : Fail ---- Wed Aug 28 12:35:50 UTC 2019
count 41 : Fail ---- Wed Aug 28 12:35:51 UTC 2019
count 42 : Fail ---- Wed Aug 28 12:35:52 UTC 2019
count 43 : Fail ---- Wed Aug 28 12:35:53 UTC 2019
count 44 : Fail ---- Wed Aug 28 12:35:54 UTC 2019
count 45 : Fail ---- Wed Aug 28 12:35:55 UTC 2019
count 46 : OK Wed Aug 28 12:35:56 UTC 2019
count 47 : OK Wed Aug 28 12:35:57 UTC 2019
...El tiempo de inactividad de la base de datos se inició a las 12:35:49 hasta las 12:35:56 con una cantidad total de 7 segundos. Eso es bastante impresionante.
Mirando el evento de la base de datos desde la consola de administración de Aurora, solo ocurrieron estos dos eventos:
Wed, 28 Aug 2019 12:35:50 GMT A new writer was promoted. Restarting database as a reader.
Wed, 28 Aug 2019 12:35:55 GMT DB instance restartedNo le toma mucho tiempo a Aurora promover a un esclavo para que se convierta en maestro y degradar al maestro para que se convierta en esclavo. Tenga en cuenta que todas las réplicas de Aurora comparten el mismo volumen subyacente con la instancia principal y esto significa que la replicación se puede realizar en milisegundos, ya que las actualizaciones realizadas por la instancia principal están disponibles al instante para todas las réplicas de Aurora. Por lo tanto, tiene un retraso de replicación mínimo (Amazon afirma que es de 100 milisegundos o menos). Esto reducirá en gran medida el tiempo de verificación de estado y mejorará significativamente el tiempo de recuperación.
Conmutación por error con ClusterControl
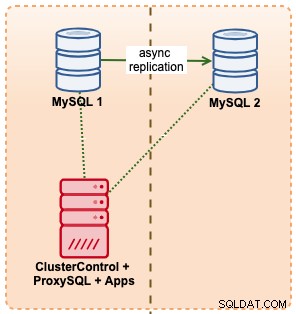
En este ejemplo, imitamos una configuración similar con Amazon RDS usando instancias m5.xlarge, con un ProxySQL en el medio para automatizar la conmutación por error desde la aplicación usando un acceso de punto final único como RDS. El siguiente diagrama ilustra nuestra arquitectura:
Dado que tenemos acceso directo a las instancias de la base de datos, desencadenaríamos una conmutación por error automática simplemente eliminando el proceso de MySQL en el maestro activo:
$ kill -9 $(pidof mysqld)El comando anterior activó una recuperación automática dentro de ClusterControl:
[11:08:49]: Job Completed.
[11:08:44]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: Failover Complete. New master is 10.15.3.141:3306.
[11:08:39]: Attaching slaves to new master.
[11:08:39]: 10.15.3.141:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.
[11:08:39]: 10.15.3.141:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: 10.15.3.141:3306: Setting read_only=OFF and super_read_only=OFF.
[11:08:38]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:38]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: Stopping slaves.
[11:08:38]: 10.15.3.141:3306: Completed preparations of candidate.
[11:08:38]: 10.15.3.141:3306: Applied 0 transactions. Remaining: .
[11:08:38]: 10.15.3.141:3306: waiting up to 4294967295 seconds before timing out.
[11:08:38]: 10.15.3.141:3306: Checking if the candidate has relay log to apply.
[11:08:38]: 10.15.3.141:3306: preparing candidate.
[11:08:38]: No errant transactions found.
[11:08:38]: 10.15.3.141:3306: Skipping, same as slave 10.15.3.141:3306
[11:08:38]: Checking for errant transactions.
[11:08:37]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Can't connect to MySQL server on '10.15.3.69' (115)
[11:08:37]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Failed to CREATE USER rpl_user. Error: 10.15.3.69:3306: Query failed: Can't connect to MySQL server on '10.15.3.69' (115).
[11:08:36]: 10.15.3.69:3306: Creating user 'rpl_user'@'10.15.3.141.
[11:08:36]: 10.15.3.141:3306: Executing GRANT REPLICATION SLAVE 'rpl_user'@'10.15.3.69'.
[11:08:36]: 10.15.3.141:3306: Creating user 'rpl_user'@'10.15.3.69.
[11:08:36]: 10.15.3.141:3306: Elected as the new Master.
[11:08:36]: 10.15.3.141:3306: Slave lag is 0 seconds.
[11:08:36]: 10.15.3.141:3306 to slave list
[11:08:36]: 10.15.3.141:3306: Checking if slave can be used as a candidate.
[11:08:33]: 10.15.3.69:3306: Trying to shutdown the failed master if it is up.
[11:08:32]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:31]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.141:3306: ioerrno=2003 io running 0
[11:08:30]: Checking 10.15.3.141:3306
[11:08:30]: 10.15.3.69:3306: REPL_UNDEFINED
[11:08:30]: 10.15.3.69:3306
[11:08:30]: Failover to a new Master.
Job spec: Failover to a new Master.Mientras que, desde el punto de vista de nuestra aplicación de prueba, el tiempo de inactividad ocurrió en el siguiente momento mientras se conectaba al puerto de host ProxySQL 6033:
...
count 1 : OK Wed Aug 28 11:08:24 UTC 2019
count 2 : OK Wed Aug 28 11:08:25 UTC 2019
count 3 : OK Wed Aug 28 11:08:26 UTC 2019
count 4 : Fail ---- Wed Aug 28 11:08:28 UTC 2019
count 5 : Fail ---- Wed Aug 28 11:08:30 UTC 2019
count 6 : Fail ---- Wed Aug 28 11:08:32 UTC 2019
count 7 : Fail ---- Wed Aug 28 11:08:34 UTC 2019
count 8 : Fail ---- Wed Aug 28 11:08:36 UTC 2019
count 9 : Fail ---- Wed Aug 28 11:08:38 UTC 2019
count 10 : OK Wed Aug 28 11:08:39 UTC 2019
count 11 : OK Wed Aug 28 11:08:40 UTC 2019
...Al observar tanto los eventos del trabajo de recuperación como el resultado de nuestra aplicación, el nodo de la base de datos MySQL estuvo inactivo 4 segundos antes de que comience el trabajo de recuperación del clúster, desde las 11:08:28 hasta las 11:08:39, con un tiempo de inactividad total de MySQL de 11 segundos. . Una de las cosas más impresionantes de ClusterControl es que puede realizar un seguimiento del progreso de la recuperación sobre las acciones que realiza ClusterControl durante la conmutación por error. Proporciona un nivel de transparencia que no podrá obtener con ninguna oferta de bases de datos de los proveedores de la nube.
Para la replicación de MySQL/MariaDB/PostgreSQL, ClusterControl le permite tener una mayor precisión en sus bases de datos con el soporte de la siguiente configuración y parámetros avanzados:
- Administración de topología de replicación maestro-maestro
- Administración de topología de replicación de cadena
- Visor de topología
- Lista blanca/lista negra de esclavos para ser promovidos como maestros
- Comprobador de transacciones errantes
- Los eventos previos/posteriores, exitosos/fallidos de conmutación por error/conmutación se conectan con un script externo
- Esclavo de reconstrucción automática en caso de error
- Escalar hacia fuera el esclavo desde la copia de seguridad existente
Resumen del tiempo de conmutación por error
En términos de tiempo de conmutación por error, Amazon RDS Aurora for MySQL es el claro ganador con 7 segundos , seguido de ClusterControl 11 segundos y Amazon RDS para MySQL con 27 segundos .
Tenga en cuenta que esta es solo una prueba simple, con un cliente y una transacción por segundo para medir el tiempo de recuperación más rápido. Las transacciones grandes o un proceso de recuperación prolongado pueden aumentar el tiempo de conmutación por error, por ejemplo, las transacciones de ejecución prolongada pueden demorar mucho tiempo al cerrar MySQL.