Las bases de datos que sirven aplicaciones comerciales a menudo deben admitir datos temporales. Por ejemplo, suponga que un contrato con un proveedor es válido solo por un tiempo limitado. Puede ser válido desde un momento específico en adelante, o puede ser válido para un intervalo de tiempo específico, desde un momento inicial hasta un momento final. Además, muchas veces es necesario auditar todos los cambios en una o más tablas. Es posible que también necesite poder mostrar el estado en un momento específico o todos los cambios realizados en una tabla en un período de tiempo específico. Desde la perspectiva de la integridad de los datos, es posible que deba implementar muchas restricciones temporales específicas adicionales.
Introducción de datos temporales
En una tabla con soporte temporal, el encabezado representa un predicado con un parámetro de al menos una vez que representa el intervalo cuando el resto del predicado es válido, el predicado completo es, por lo tanto, un predicado con marca de tiempo. Las filas representan proposiciones con marca de tiempo, y el período de tiempo válido de la fila generalmente se expresa con dos atributos:desde y a o comenzar y fin .
Tipos de tablas temporales
Es posible que haya notado durante la parte de la introducción que hay dos tipos de problemas temporales. El primero es el tiempo de validez de la proposición:en qué período la proposición que representa una fila con marca de tiempo en una tabla era realmente verdadera. Por ejemplo, un contrato con un proveedor fue válido solo desde el punto de tiempo 1 hasta el punto de tiempo 2. Este tipo de tiempo de validez es significativo para las personas, significativo para el negocio. El tiempo de validez también se denomina tiempo de aplicación o tiempo humano . Podemos tener múltiples periodos válidos para una misma entidad. Por ejemplo, el contrato antes mencionado que era válido desde el punto de tiempo 1 hasta el punto de tiempo 2 también podría ser válido desde el punto de tiempo 7 hasta el punto de tiempo 9.
El segundo problema temporal es el tiempo de transacción . Se insertó una fila para el contrato mencionado anteriormente en el punto de tiempo 1 y fue la única versión de la verdad conocida en la base de datos hasta que alguien la cambió, o incluso hasta el final del tiempo. Cuando la fila se actualiza en el punto de tiempo 2, se sabía que la fila original era verdadera para la base de datos desde el punto de tiempo 1 hasta el punto de tiempo 2. Se inserta una nueva fila para la misma proposición con un tiempo válido para la base de datos desde el punto de tiempo 2 hasta el punto de tiempo 2. el fin del tiempo La hora de la transacción también se conoce como hora del sistema o hora de la base de datos .
Por supuesto, también puede implementar tablas versionadas tanto de la aplicación como del sistema. Estas tablas se denominan bitemporales mesas.
En SQL Server 2016, obtiene soporte para el tiempo del sistema listo para usar con tablas temporales versionadas del sistema . Si necesita implementar el tiempo de aplicación, debe desarrollar una solución usted mismo.
Operadores de intervalo de Allen
La teoría de los datos temporales en un modelo relacional comenzó a evolucionar hace más de treinta años. Presentaré bastantes operadores booleanos útiles y un par de operadores que trabajan en intervalos y devuelven un intervalo. Estos operadores se conocen como operadores de Allen, en honor a J. F. Allen, quien definió varios de ellos en un artículo de investigación de 1983 sobre intervalos temporales. Todos ellos todavía se aceptan como válidos y necesarios. Un sistema de administración de base de datos podría ayudarlo a lidiar con los tiempos de aplicación al implementar estos operadores listos para usar.
Permítanme presentarles primero la notación que usaré. Trabajaré en dos intervalos, denotados i1 y i2 . El punto de tiempo inicial del primer intervalo es b1 , y el final es e1 ; el punto de tiempo inicial del segundo intervalo es b2 y el final es e2 . Los operadores booleanos de Allen se definen en la siguiente tabla.
[table id=2 /]
Además de los operadores booleanos, hay tres operadores de Allen que aceptan intervalos como parámetros de entrada y devuelven un intervalo. Estos operadores constituyen álgebra de intervalos simple . Tenga en cuenta que esos operadores tienen el mismo nombre que los operadores relacionales con los que probablemente ya esté familiarizado:Unión, Intersección y Menos. Sin embargo, no se comportan exactamente como sus contrapartes relacionales. En general, si se utiliza cualquiera de los tres operadores de intervalo, si la operación da como resultado un conjunto vacío de puntos de tiempo o un conjunto que no se puede describir mediante un intervalo, entonces el operador debe devolver NULL. Una unión de dos intervalos solo tiene sentido si los intervalos se encuentran o se superponen. Una intersección tiene sentido solo si los intervalos se superponen. El operador Intervalo menos tiene sentido solo en algunos casos. Por ejemplo, (3:10) Menos (5:7) devuelve NULL porque el resultado no se puede describir mediante un intervalo. La siguiente tabla resume la definición de los operadores del álgebra de intervalos.
[identificación de la tabla=3 /]
Problema de rendimiento de consultas superpuestas Uno de los operadores más complejos de implementar es el de superposiciones operador. Las consultas que necesitan encontrar intervalos superpuestos no son fáciles de optimizar. Sin embargo, tales consultas son bastante frecuentes en las tablas temporales. En este artículo y en los próximos dos, le mostraré un par de formas de optimizar dichas consultas. Pero antes de presentar las soluciones, permítanme presentarles el problema.
Para poder explicar el problema, necesito algunos datos. El siguiente código muestra un ejemplo de cómo crear una tabla con intervalos de validez expresados con b y e columnas, donde el comienzo y el final de un intervalo se representan como números enteros. La tabla se completa con datos de demostración de la tabla WideWorldImporters.Sales.OrderLines. Tenga en cuenta que hay varias versiones de WideWorldImporters base de datos, por lo que puede obtener resultados ligeramente diferentes. Usé el archivo de respaldo WideWorldImporters-Standard.bak de https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0 para restaurar esta base de datos de demostración en mi instancia de SQL Server .
Creación de los datos de demostración
Creé una tabla de demostración dbo.Intervals en el tempd base de datos con el siguiente código.
USE tempdb; GO SELECT OrderLineID AS id, StockItemID * (OrderLineID % 5 + 1) AS b, LastEditedBy + StockItemID * (OrderLineID % 5 + 1) AS e INTO dbo.Intervals FROM WideWorldImporters.Sales.OrderLines; -- 231412 rows GO ALTER TABLE dbo.Intervals ADD CONSTRAINT PK_Intervals PRIMARY KEY(id); CREATE INDEX idx_b ON dbo.Intervals(b) INCLUDE(e); CREATE INDEX idx_e ON dbo.Intervals(e) INCLUDE(b); GO
Tenga en cuenta también los índices creado. Los dos índices son óptimos para búsquedas al comienzo de un intervalo o al final de un intervalo. Puede verificar el inicio mínimo y el final máximo de todos los intervalos con el siguiente código.
SELECT MIN(b), MAX(e) FROM dbo.Intervals;
Puede ver en los resultados que el punto de tiempo de inicio mínimo es 1 y el punto de tiempo de finalización máximo es 1155.
Dar el contexto a los datos
Puede notar que represento los puntos de tiempo de principio y final como números enteros. Ahora necesito dar a los intervalos algo de contexto de tiempo. En este caso, un solo punto de tiempo representa un día . El siguiente código crea una tabla de búsqueda de fechas y lo puebla. Tenga en cuenta que la fecha de inicio es el 1 de julio de 2014.
CREATE TABLE dbo.DateNums (n INT NOT NULL PRIMARY KEY, d DATE NOT NULL); GO DECLARE @i AS INT = 1, @d AS DATE = '20140701'; WHILE @i <= 1200 BEGIN INSERT INTO dbo.DateNums (n, d) SELECT @i, @d; SET @i += 1; SET @d = DATEADD(day,1,@d); END; GO
Ahora, puede unir la tabla dbo.Intervals a la tabla dbo.DateNums dos veces, para dar contexto a los números enteros que representan el principio y el final de los intervalos.
SELECT i.id, i.b, d1.d AS dateB, i.e, d2.d AS dateE FROM dbo.Intervals AS i INNER JOIN dbo.DateNums AS d1 ON i.b = d1.n INNER JOIN dbo.DateNums AS d2 ON i.e = d2.n ORDER BY i.id;
Presentación del problema de rendimiento
El problema con las consultas temporales es que al leer de una tabla, SQL Server puede usar solo un índice y eliminar con éxito las filas que no son candidatas para el resultado solo de un lado, y luego escanea el resto de los datos. Por ejemplo, necesita encontrar todos los intervalos en la tabla que se superponen con un intervalo dado. Recuerda, dos intervalos se superponen cuando el comienzo del primero es menor o igual al final del segundo y el comienzo del segundo es menor o igual al final del primero, o matemáticamente cuando (b1 ≤ e2) Y (b2 ≤ e1).
La siguiente consulta buscó todos los intervalos que se superponen con el intervalo (10, 30). Tenga en cuenta que la segunda condición (b2 ≤ e1) se cambia a (e1 ≥ b2) para una lectura más sencilla (el comienzo y el final de los intervalos de la tabla siempre están en el lado izquierdo de la condición). El intervalo dado o buscado se encuentra al comienzo de la línea de tiempo para todos los intervalos de la tabla.
SET STATISTICS IO ON; DECLARE @b AS INT = 10, @e AS INT = 30; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
La consulta utilizó 36 lecturas lógicas. Si revisa el plan de ejecución, puede ver que la consulta usó la búsqueda de índice en el índice idx_b con el predicado de búsqueda [tempdb].[dbo].[Intervalos].b <=Operador escalar ((30)) y luego escanear las filas y seleccione las filas resultantes usando el predicado residual [tempdb].[dbo].[Intervalos].[e]>=(10). Debido a que el intervalo buscado está al comienzo de la línea de tiempo, el predicado de búsqueda eliminó con éxito la mayoría de las filas; solo unos pocos intervalos en la tabla tienen el punto inicial menor o igual a 30.
Obtendría una consulta igualmente eficiente si el intervalo buscado estuviera al final de la línea de tiempo, solo que SQL Server usaría el índice idx_e para buscar. Sin embargo, ¿qué sucede si el intervalo buscado está en el medio de la línea de tiempo, como muestra la siguiente consulta?
DECLARE @b AS INT = 570, @e AS INT = 590; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Esta vez, la consulta utilizó 111 lecturas lógicas. Con una tabla más grande, la diferencia con la primera consulta sería aún mayor. Si revisa el plan de ejecución, puede descubrir que SQL Server usó el índice idx_e con [tempdb].[dbo].[Intervalos].e>=Scalar Operator((570)) predicado de búsqueda y [tempdb].[ dbo].[Intervalos].[b]<=(590) predicado residual. El predicado de búsqueda excluye aproximadamente la mitad de las filas de un lado, mientras que la mitad de las filas del otro lado se escanea y las filas resultantes se extraen con el predicado residual.
Solución T-SQL mejorada
Hay una solución que usaría ese índice para la eliminación de las filas de ambos lados del intervalo buscado usando un solo índice. La siguiente figura muestra esta lógica.
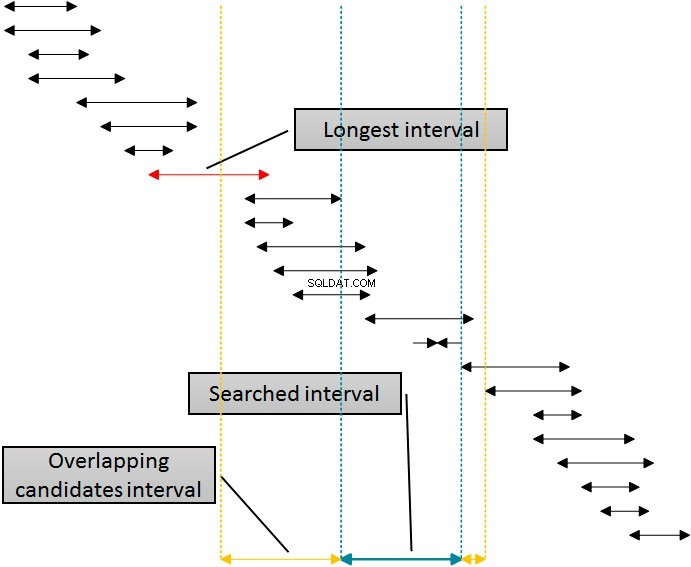
Los intervalos en la figura están ordenados por el límite inferior, lo que representa el uso del índice idx_b por parte de SQL Server. Eliminar intervalos del lado derecho del intervalo dado (buscado) es simple:simplemente elimine todos los intervalos donde el comienzo es al menos una unidad más grande (más a la derecha) del final del intervalo dado. Puede ver este límite en la figura indicada con la línea de puntos más a la derecha. Sin embargo, eliminar por la izquierda es más complejo. Para usar el mismo índice, el índice idx_b para eliminar desde la izquierda, necesito usar el comienzo de los intervalos en la tabla en la cláusula WHERE de la consulta. Tengo que ir al lado izquierdo lejos del comienzo del intervalo dado (buscado) al menos durante la duración del intervalo más largo de la tabla, que está marcado con una leyenda en la figura. Los intervalos que comienzan antes de la línea amarilla izquierda no pueden superponerse con el intervalo dado (azul).
Como ya sé que la longitud del intervalo más largo es 20, puedo escribir una consulta mejorada de una forma bastante sencilla.
DECLARE @b AS INT = 570, @e AS INT = 590; DECLARE @max AS INT = 20; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND b >= @b - @max AND e >= @b AND e <= @e + @max OPTION (RECOMPILE);
Esta consulta recupera las mismas filas que la anterior con solo 20 lecturas lógicas. Si revisa el plan de ejecución, puede ver que se usó idx_b, con el predicado de búsqueda Seek Keys[1]:Start:[tempdb].[dbo].[Intervals].b>=Scalar Operator((550)) , End:[tempdb].[dbo].[Intervals].b <=Scalar Operator((590)), que eliminó con éxito filas de ambos lados de la línea de tiempo, y luego el predicado residual [tempdb].[dbo]. [Intervals].[e]>=(570) AND [tempdb].[dbo].[Intervals].[e]<=(610) se usó para seleccionar filas de un escaneo parcial muy limitado.
Por supuesto, la cifra podría invertirse para cubrir los casos en los que el índice idx_e sería más útil. Con este índice, la eliminación desde la izquierda es simple:elimine todos los intervalos que terminan al menos una unidad antes del comienzo del intervalo dado. Esta vez, la eliminación por la derecha es más compleja:el final de los intervalos de la tabla no puede estar más a la derecha que el final del intervalo dado más la longitud máxima de todos los intervalos de la tabla.
Tenga en cuenta que este rendimiento es la consecuencia de los datos específicos de la tabla. La longitud máxima de un intervalo es 20. De esta manera, SQL Server puede eliminar intervalos de ambos lados de manera muy eficiente. Sin embargo, si solo hubiera un intervalo largo en la tabla, el código se volvería mucho menos eficiente, porque SQL Server no podría eliminar muchas filas de un lado, ya sea izquierdo o derecho, según el índice que usaría. . De todos modos, en la vida real, la duración de los intervalos no varía mucho muchas veces, por lo que esta técnica de optimización puede ser muy útil, especialmente porque es simple.
Conclusión
Tenga en cuenta que esta es solo una posible solución. Puede encontrar una solución que sea más compleja, pero que produzca un rendimiento predecible sin importar la duración del intervalo más largo en el artículo Interval Queries in SQL Server de Itzik Ben-Gan (https://sqlmag.com/t-sql/ sql-server-interval-consultas). Sin embargo, me gusta mucho el T-SQL mejorado solución que presenté en este artículo. La solución es muy simple; todo lo que necesita hacer es agregar dos predicados a la cláusula WHERE de sus consultas superpuestas. Sin embargo, este no es el final de las posibilidades. Estén atentos, en los próximos dos artículos les mostraré más soluciones, para que tengan un amplio conjunto de posibilidades en su caja de herramientas de optimización.
Herramienta útil:
dbForge Query Builder para SQL Server:permite a los usuarios crear consultas SQL complejas rápida y fácilmente a través de una interfaz visual intuitiva sin necesidad de escribir código manualmente.