La agrupación es una función importante que ayuda a organizar y ordenar los datos. Hay muchas formas de hacerlo, y uno de los métodos más efectivos es la cláusula SQL GROUP BY.
Puede usar SQL GROUP BY para dividir las filas de los resultados en grupos con una función agregada . Parece fácil sumar, promediar o contar registros con él.
¿Pero lo estás haciendo bien?
"Correcto" puede ser subjetivo. Cuando se ejecuta sin errores críticos con una salida correcta, se considera que está bien. Sin embargo, también debe ser rápido.
En este artículo, también se considerará la velocidad. Verá muchos análisis de consultas utilizando lecturas lógicas y planes de ejecución en todos los puntos.
Comencemos.
1. Filtrar temprano
Si está confundido acerca de cuándo usar WHERE y HAVING, este es para usted. Porque dependiendo de la condición que proporcione, ambos pueden dar el mismo resultado.
Pero son diferentes.
HAVING filtra los grupos usando las columnas en la cláusula SQL GROUP BY. WHERE filtra las filas antes de que se produzcan agrupaciones y agregaciones. Por lo tanto, si filtra utilizando la cláusula HAVING, la agrupación se produce para todos filas devueltas.
Y eso es malo.
¿Por qué? La respuesta corta es:es lento. Probemos esto con 2 consultas. Echa un vistazo al código a continuación. Antes de ejecutarlo en SQL Server Management Studio, primero presione Ctrl-M.
SET STATISTICS IO ON
GO
-- using WHERE
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
ORDER BY Product, OrderYear, OrderMonth;
-- using HAVING
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
HAVING YEAR(soh.OrderDate) = 2012
ORDER BY Product, OrderYear, OrderMonth;
SET STATISTICS IO OFF
GO
Análisis
Las 2 declaraciones SELECT anteriores devolverán las mismas filas. Ambos son correctos en la devolución de pedidos de productos por mes en el año 2012. Pero el primer SELECT tardó 136 ms. para ejecutarse en mi computadora portátil, ¡mientras que otro tardó 764 ms!
¿Por qué?
Primero verifiquemos las lecturas lógicas en la Figura 1. STATISTICS IO devolvió estos resultados. Luego, lo pegué en StatisticsParser.com para la salida formateada.
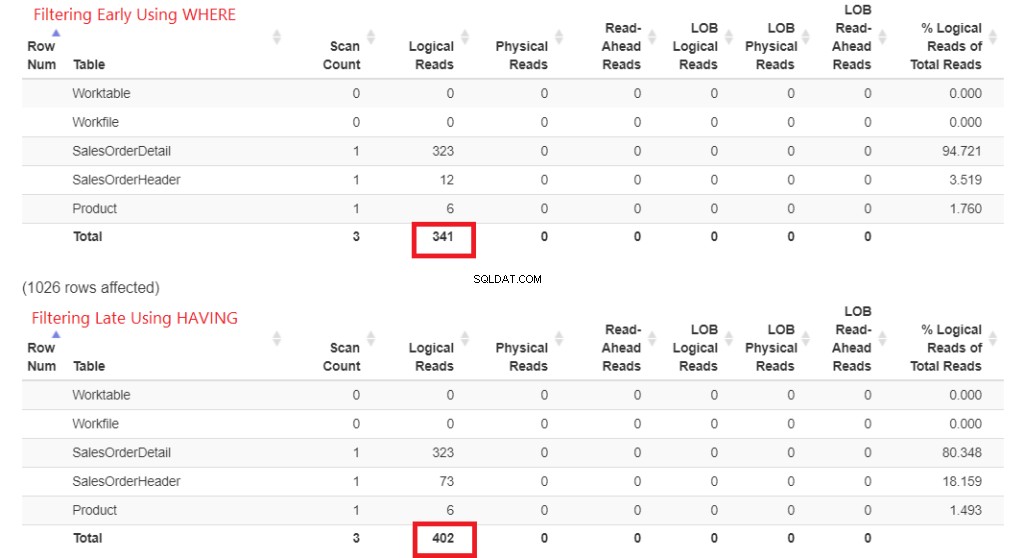
Figura 1 . Lecturas lógicas de filtrado temprano con WHERE frente a filtrado tardío con HAVING.
Mire las lecturas lógicas totales de cada uno. Para comprender estos números, cuantas más lecturas lógicas se necesiten, más lenta será la consulta. Por lo tanto, demuestra que usar HAVING es más lento y filtrar temprano con WHERE es más rápido.
Por supuesto, esto no significa que TENER sea inútil. Una excepción es cuando se usa HAVING con un agregado como HAVING SUM(sod.Linetotal)> 100000 . Puede combinar una cláusula WHERE y una cláusula HAVING en una consulta.
Ver el plan de ejecución en la Figura 2.
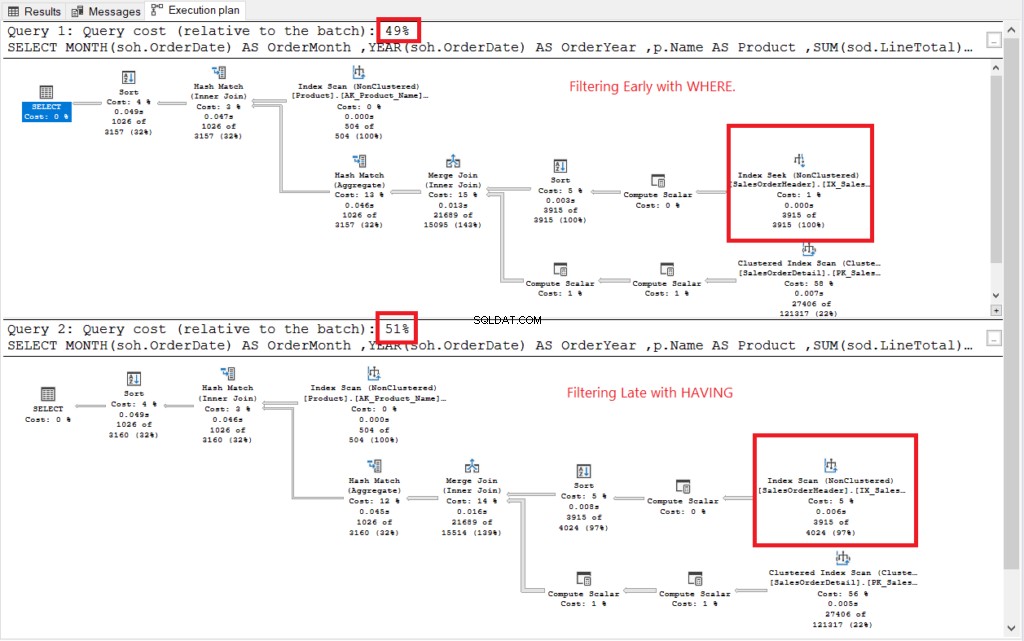
Figura 2 . Planes de ejecución de filtrado temprano versus filtrado tardío.
Ambos planes de ejecución se veían similares excepto por los que estaban enmarcados en rojo. El filtrado utilizó anteriormente el operador Index Seek, mientras que otro utilizó Index Scan. Las búsquedas son más rápidas que los escaneos en tablas grandes.
No te: Filtrar temprano tiene menos costo que filtrar tarde. Por lo tanto, la conclusión es que filtrar las filas antes puede mejorar el rendimiento.
2. Agrupa primero, únete después
Unirse a algunas de las tablas que necesita más tarde también puede mejorar el rendimiento.
Digamos que quieres tener ventas mensuales de productos. También debe obtener el nombre del producto, el número y la subcategoría en la misma consulta. Estas columnas están en otra tabla. Y todos deben agregarse en la cláusula GROUP BY para tener una ejecución exitosa. Aquí está el código.
SET STATISTICS IO ON
GO
SELECT
p.Name AS Product
,p.ProductNumber
,ps.Name AS ProductSubcategory
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.name, p.ProductNumber, ps.Name
ORDER BY Product
SET STATISTICS IO OFF
GO
Esto funcionará bien. Pero hay una manera mejor y más rápida. Esto no requerirá que agregue las 3 columnas para el nombre del producto, el número y la subcategoría en la cláusula GROUP BY. Sin embargo, esto requerirá un poco más de pulsaciones de teclas. Aquí está.
SET STATISTICS IO ON
GO
;WITH Orders2012 AS
(
SELECT
sod.ProductID
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY sod.ProductID
)
SELECT
P.Name AS Product
,P.ProductNumber
,ps.Name AS ProductSubcategory
,o.ProductSales
FROM Orders2012 o
INNER JOIN Production.Product p ON o.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
ORDER BY Product;
SET STATISTICS IO OFF
GO
Análisis
¿Por qué es esto más rápido? Las uniones a Producto y Subcategoría de producto se hacen mas tarde. Ambos no están involucrados en la cláusula GROUP BY. Demostremos esto con números en las ESTADÍSTICAS IO. Consulte la figura 4.
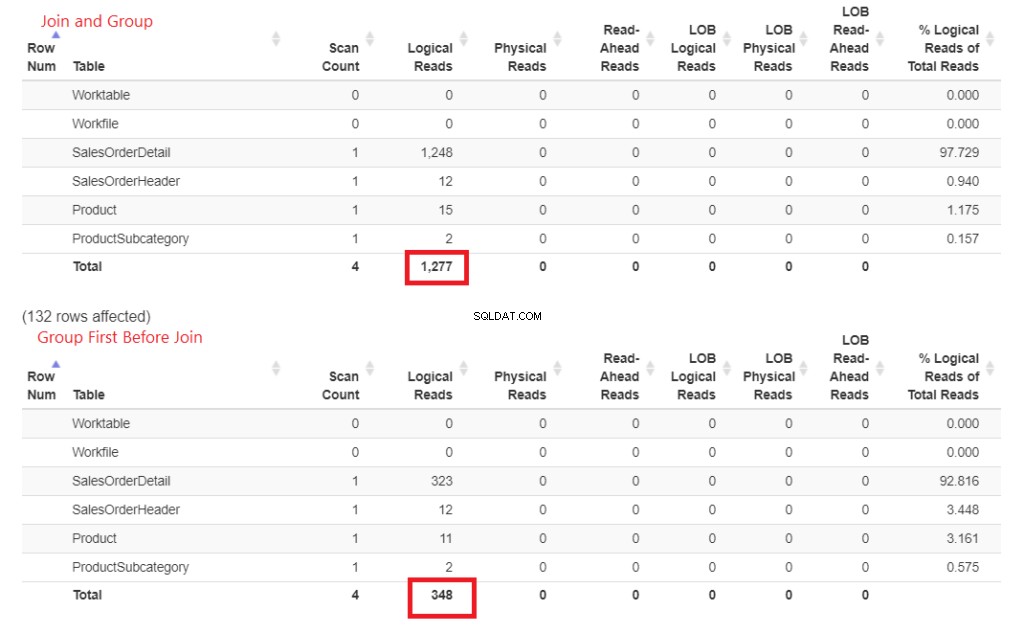
Figura 3 . Unirse temprano y luego agrupar consumía más lecturas lógicas que hacer las uniones más tarde.
¿Ves esas lecturas lógicas? La diferencia es grande y el ganador es obvio.
Comparemos el plan de ejecución de las 2 consultas para ver el motivo detrás de los números anteriores. Primero, vea la Figura 4 para ver el plan de ejecución de la consulta con todas las tablas unidas cuando están agrupadas.
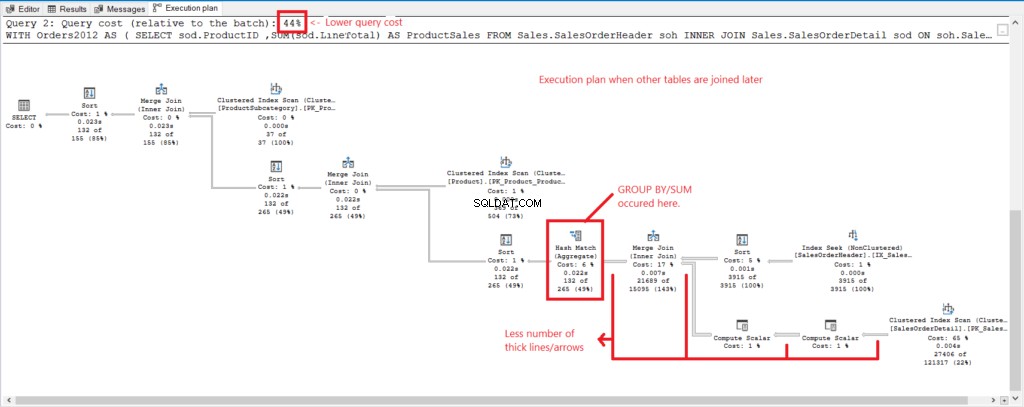
Figura 4 . Plan de ejecución cuando se unen todas las tablas.
Y tenemos las siguientes observaciones:
- GROUP BY y SUM se realizaron tarde en el proceso después de unir todas las tablas.
- Muchas líneas y flechas más gruesas:esto explica las 1277 lecturas lógicas.
- Las 2 consultas combinadas forman el 100 % del costo de la consulta. Pero el plan de esta consulta tiene un costo de consulta más alto (56 %).
Ahora, aquí hay un plan de ejecución cuando nos agrupamos primero y nos unimos al Producto y Subcategoría de producto mesas más tarde. Mira la Figura 5.
Figura 5 . Plan de ejecución cuando el grupo primero, únase después esté terminado.
Y tenemos las siguientes observaciones en la Figura 5.
- GROUP BY y SUM terminaron temprano.
- Menor número de líneas gruesas y flechas:esto explica las 348 lecturas lógicas únicamente.
- Menor costo de consulta (44%).
3. Agrupar una columna indexada
Cada vez que SQL GROUP BY se realiza en una columna, esa columna debe tener un índice. Aumentará la velocidad de ejecución una vez que agrupe la columna con un índice. Modifiquemos la consulta anterior y usemos la fecha de envío en lugar de la fecha del pedido. La columna de fecha de envío no tiene índice en SalesOrderHeader .
SET STATISTICS IO ON
GO
SELECT
MONTH(soh.ShipDate) AS ShipMonth
,YEAR(soh.ShipDate) AS ShipYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.ShipDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.ShipDate), MONTH(soh.ShipDate)
ORDER BY Product, ShipYear, ShipMonth;
SET STATISTICS IO OFF
GO
Presione Ctrl-M, luego ejecute la consulta anterior en SSMS. Luego, cree un índice no agrupado en ShipDate columna. Tenga en cuenta las lecturas lógicas y el plan de ejecución. Finalmente, vuelva a ejecutar la consulta anterior en otra pestaña de consulta. Tenga en cuenta las diferencias en las lecturas lógicas y los planes de ejecución.
Aquí está la comparación de las lecturas lógicas en la Figura 6.
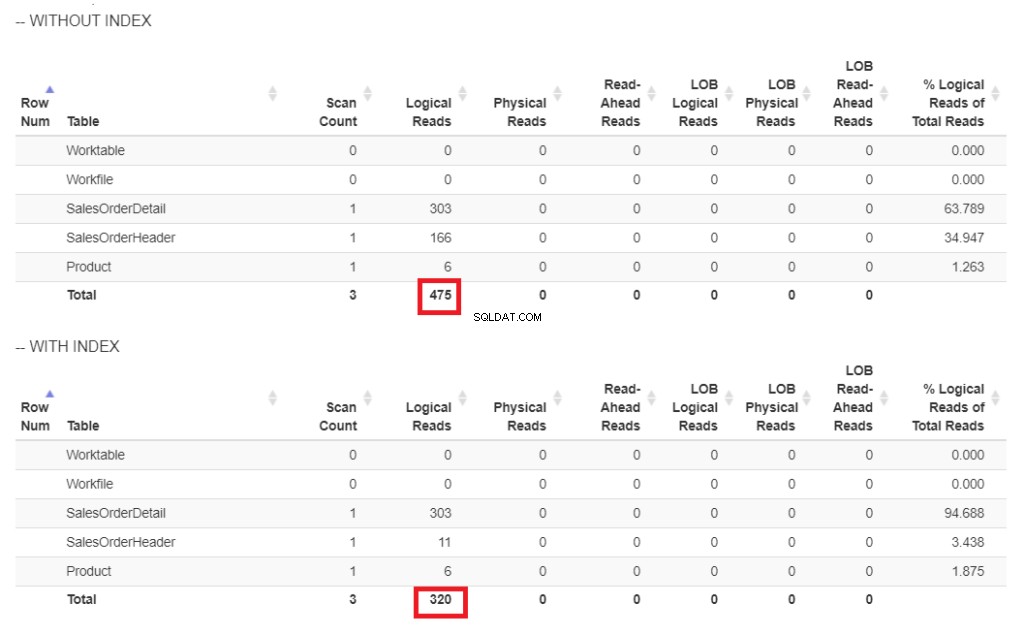
Figura 6 . Lecturas lógicas de nuestro ejemplo de consulta con y sin un índice en ShipDate.
En la Figura 6, hay lecturas lógicas más altas de la consulta sin un índice en ShipDate .
Ahora tengamos el plan de ejecución cuando no hay índice en ShipDate existe en la Figura 7.
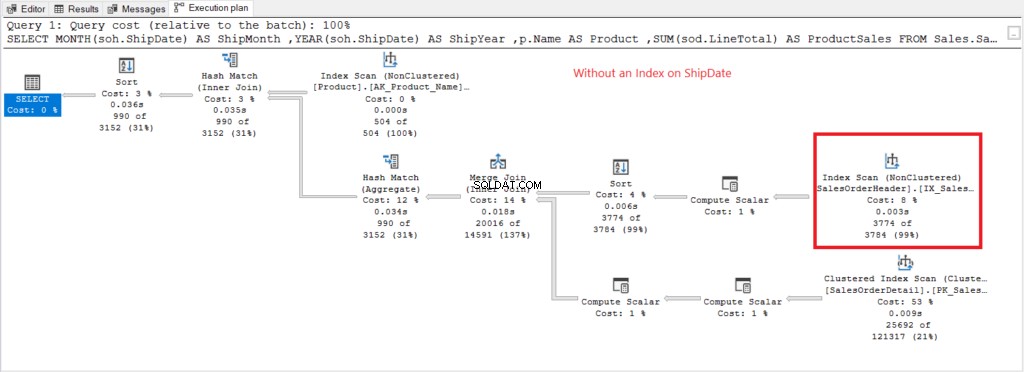
Figura 7 . Plan de ejecución cuando se usa GROUP BY en ShipDate sin indexar.
El escaneo de índice El operador utilizado en el plan de la Figura 7 explica las lecturas lógicas más altas (475). Aquí hay un plan de ejecución después de indexar ShipDate columna.
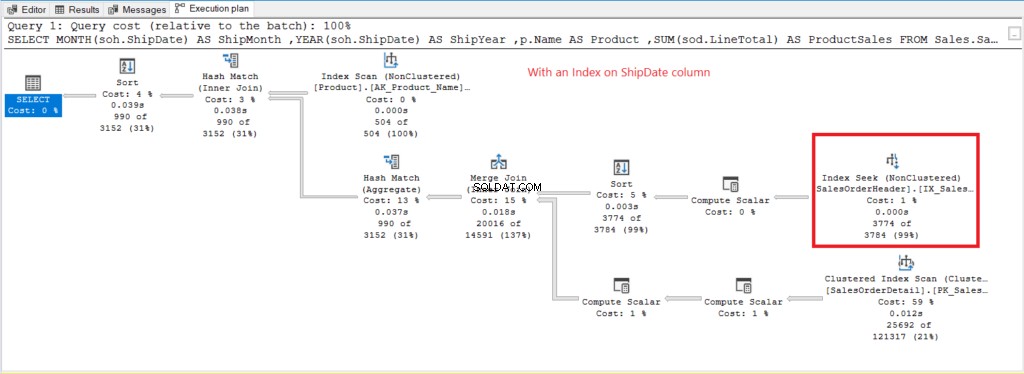
Figura 8 . Plan de ejecución cuando se usa GROUP BY en ShipDate indexado.
En lugar de Index Scan, se usa Index Seek después de indexar ShipDate columna. Esto explica las lecturas lógicas inferiores de la Figura 6.
Entonces, para mejorar el rendimiento al usar GROUP BY, considere indexar las columnas que usó para agrupar.
Conclusiones sobre el uso de SQL GROUP BY
SQL GROUP BY es fácil de usar. Pero debe dar el siguiente paso para ir más allá de resumir los datos para los informes. Aquí están los puntos de nuevo:
- Filtro anticipado . Elimine las filas que no necesita resumir usando la cláusula WHERE en lugar de la cláusula HAVING.
- Grupo primero, unirse después . A veces, habrá columnas que deba agregar aparte de las columnas que está agrupando. En lugar de incluirlos en la cláusula GROUP BY, divida la consulta con un CTE y únase a otras tablas más tarde.
- Utilice GROUP BY con columnas indexadas . Esta cosa básica puede resultar útil cuando la base de datos es tan rápida como un caracol.
Espero que esto te ayude a mejorar tu juego en la agrupación de resultados.
Si te gusta esta publicación, compártela en tus plataformas de redes sociales favoritas.